 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Proximal Algorithms for Accelerated Langevin Dynamics
Nov 28, 2023
We develop a novel class of MCMC algorithms based on a stochastized Nesterov scheme. With an appropriate addition of noise, the result is a time-inhomogeneous underdamped Langevin equation, which we prove emits a specified target distribution as its invariant measure. Convergence rates to stationarity under Wasserstein-2 distance are established as well. Metropolis-adjusted and stochastic gradient versions of the proposed Langevin dynamics are also provided. Experimental illustrations show superior performance of the proposed method over typical Langevin samplers for different models in statistics and image processing including better mixing of the resulting Markov chains.
Disentangling Structure and Appearance in ViT Feature Space
Nov 20, 2023

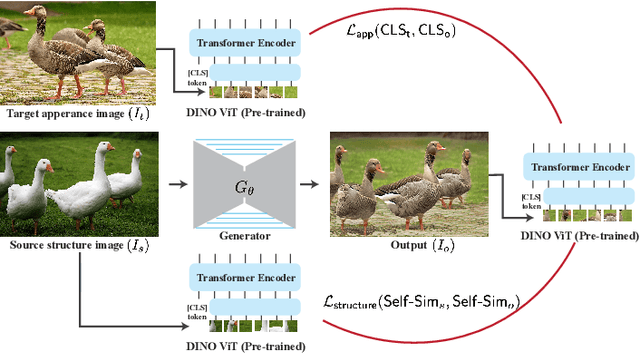
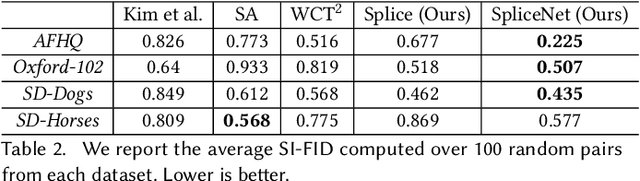
We present a method for semantically transferring the visual appearance of one natural image to another. Specifically, our goal is to generate an image in which objects in a source structure image are "painted" with the visual appearance of their semantically related objects in a target appearance image. To integrate semantic information into our framework, our key idea is to leverage a pre-trained and fixed Vision Transformer (ViT) model. Specifically, we derive novel disentangled representations of structure and appearance extracted from deep ViT features. We then establish an objective function that splices the desired structure and appearance representations, interweaving them together in the space of ViT features. Based on our objective function, we propose two frameworks of semantic appearance transfer -- "Splice", which works by training a generator on a single and arbitrary pair of structure-appearance images, and "SpliceNet", a feed-forward real-time appearance transfer model trained on a dataset of images from a specific domain. Our frameworks do not involve adversarial training, nor do they require any additional input information such as semantic segmentation or correspondences. We demonstrate high-resolution results on a variety of in-the-wild image pairs, under significant variations in the number of objects, pose, and appearance. Code and supplementary material are available in our project page: splice-vit.github.io.
Davidsonian Scene Graph: Improving Reliability in Fine-grained Evaluation for Text-to-Image Generation
Oct 30, 2023Evaluating text-to-image models is notoriously difficult. A strong recent approach for assessing text-image faithfulness is based on QG/A (question generation and answering), which uses pre-trained foundational models to automatically generate a set of questions and answers from the prompt, and output images are scored based on whether these answers extracted with a visual question answering model are consistent with the prompt-based answers. This kind of evaluation is naturally dependent on the quality of the underlying QG and QA models. We identify and address several reliability challenges in existing QG/A work: (a) QG questions should respect the prompt (avoiding hallucinations, duplications, and omissions) and (b) VQA answers should be consistent (not asserting that there is no motorcycle in an image while also claiming the motorcycle is blue). We address these issues with Davidsonian Scene Graph (DSG), an empirically grounded evaluation framework inspired by formal semantics. DSG is an automatic, graph-based QG/A that is modularly implemented to be adaptable to any QG/A module. DSG produces atomic and unique questions organized in dependency graphs, which (i) ensure appropriate semantic coverage and (ii) sidestep inconsistent answers. With extensive experimentation and human evaluation on a range of model configurations (LLM, VQA, and T2I), we empirically demonstrate that DSG addresses the challenges noted above. Finally, we present DSG-1k, an open-sourced evaluation benchmark that includes 1,060 prompts, covering a wide range of fine-grained semantic categories with a balanced distribution. We release the DSG-1k prompts and the corresponding DSG questions.
ToddlerDiffusion: Flash Interpretable Controllable Diffusion Model
Nov 24, 2023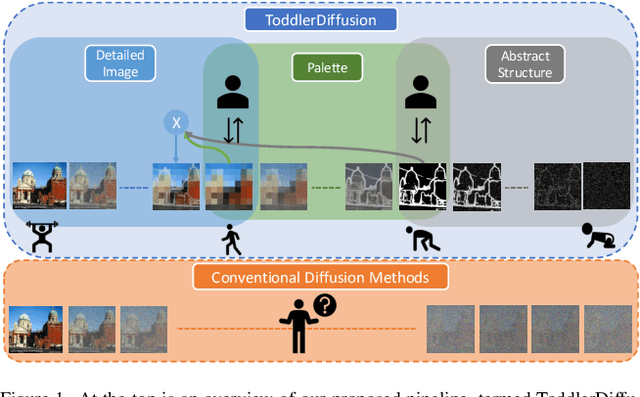

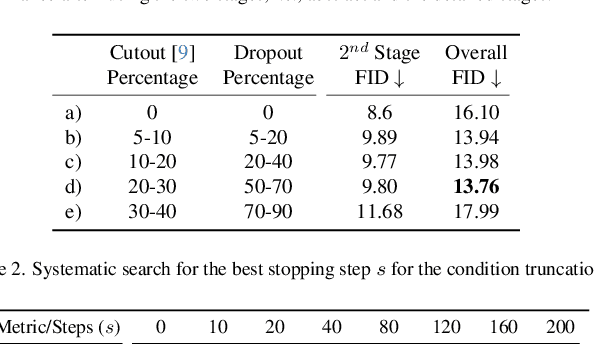

Diffusion-based generative models excel in perceptually impressive synthesis but face challenges in interpretability. This paper introduces ToddlerDiffusion, an interpretable 2D diffusion image-synthesis framework inspired by the human generation system. Unlike traditional diffusion models with opaque denoising steps, our approach decomposes the generation process into simpler, interpretable stages; generating contours, a palette, and a detailed colored image. This not only enhances overall performance but also enables robust editing and interaction capabilities. Each stage is meticulously formulated for efficiency and accuracy, surpassing Stable-Diffusion (LDM). Extensive experiments on datasets like LSUN-Churches and COCO validate our approach, consistently outperforming existing methods. ToddlerDiffusion achieves notable efficiency, matching LDM performance on LSUN-Churches while operating three times faster with a 3.76 times smaller architecture. Our source code is provided in the supplementary material and will be publicly accessible.
Robust Source-Free Domain Adaptation for Fundus Image Segmentation
Oct 25, 2023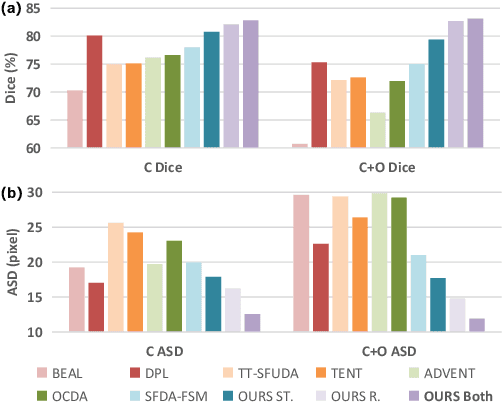
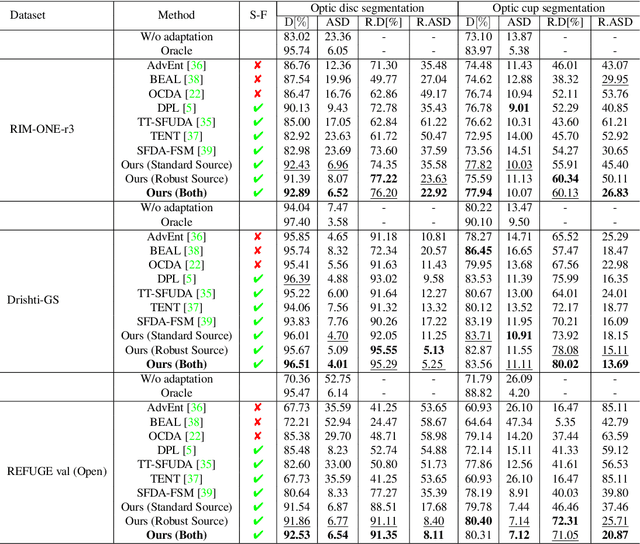
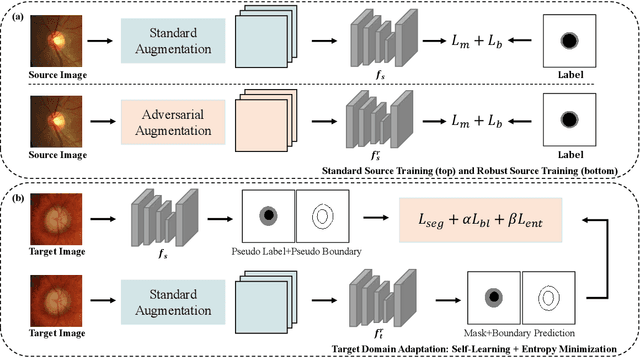
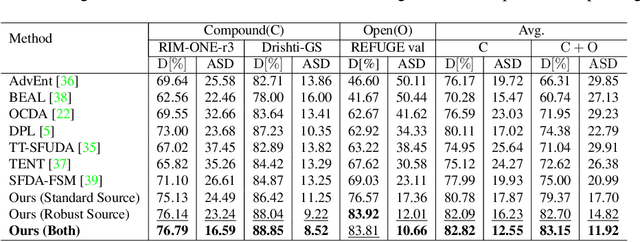
Unsupervised Domain Adaptation (UDA) is a learning technique that transfers knowledge learned in the source domain from labelled training data to the target domain with only unlabelled data. It is of significant importance to medical image segmentation because of the usual lack of labelled training data. Although extensive efforts have been made to optimize UDA techniques to improve the accuracy of segmentation models in the target domain, few studies have addressed the robustness of these models under UDA. In this study, we propose a two-stage training strategy for robust domain adaptation. In the source training stage, we utilize adversarial sample augmentation to enhance the robustness and generalization capability of the source model. And in the target training stage, we propose a novel robust pseudo-label and pseudo-boundary (PLPB) method, which effectively utilizes unlabeled target data to generate pseudo labels and pseudo boundaries that enable model self-adaptation without requiring source data. Extensive experimental results on cross-domain fundus image segmentation confirm the effectiveness and versatility of our method. Source code of this study is openly accessible at https://github.com/LinGrayy/PLPB.
Deep Unlearning: Fast and Efficient Training-free Approach to Controlled Forgetting
Dec 04, 2023Machine unlearning has emerged as a prominent and challenging area of interest, driven in large part by the rising regulatory demands for industries to delete user data upon request and the heightened awareness of privacy. Existing approaches either retrain models from scratch or use several finetuning steps for every deletion request, often constrained by computational resource limitations and restricted access to the original training data. In this work, we introduce a novel class unlearning algorithm designed to strategically eliminate an entire class or a group of classes from the learned model. To that end, our algorithm first estimates the Retain Space and the Forget Space, representing the feature or activation spaces for samples from classes to be retained and unlearned, respectively. To obtain these spaces, we propose a novel singular value decomposition-based technique that requires layer wise collection of network activations from a few forward passes through the network. We then compute the shared information between these spaces and remove it from the forget space to isolate class-discriminatory feature space for unlearning. Finally, we project the model weights in the orthogonal direction of the class-discriminatory space to obtain the unlearned model. We demonstrate our algorithm's efficacy on ImageNet using a Vision Transformer with only $\sim$1.5% drop in retain accuracy compared to the original model while maintaining under 1% accuracy on the unlearned class samples. Further, our algorithm consistently performs well when subject to Membership Inference Attacks showing 7.8% improvement on average across a variety of image classification datasets and network architectures, as compared to other baselines while being $\sim$6x more computationally efficient.
From Text to Image: Exploring GPT-4Vision's Potential in Advanced Radiological Analysis across Subspecialties
Nov 24, 2023The study evaluates and compares GPT-4 and GPT-4Vision for radiological tasks, suggesting GPT-4Vision may recognize radiological features from images, thereby enhancing its diagnostic potential over text-based descriptions.
Calibration and evaluation of a motion measurement system for PET imaging studies
Nov 29, 2023Positron Emission Tomography (PET) enables functional imaging of deep brain structures, but the bulk and weight of current systems preclude their use during many natural human activities, such as locomotion. The proposed long-term solution is to construct a robotic system that can support an imaging system surrounding the subject's head, and then move the system to accommodate natural motion. This requires a system to measure the motion of the head with respect to the imaging ring, for use by both the robotic system and the image reconstruction software. We report here the design, calibration, and experimental evaluation of a parallel string encoder mechanism for sensing this motion. Our results indicate that with kinematic calibration, the measurement system can achieve accuracy within 0.5mm, especially for small motions.
* arXiv admin note: text overlap with arXiv:2311.17863
Enhancing Diffusion Models with 3D Perspective Geometry Constraints
Dec 01, 2023While perspective is a well-studied topic in art, it is generally taken for granted in images. However, for the recent wave of high-quality image synthesis methods such as latent diffusion models, perspective accuracy is not an explicit requirement. Since these methods are capable of outputting a wide gamut of possible images, it is difficult for these synthesized images to adhere to the principles of linear perspective. We introduce a novel geometric constraint in the training process of generative models to enforce perspective accuracy. We show that outputs of models trained with this constraint both appear more realistic and improve performance of downstream models trained on generated images. Subjective human trials show that images generated with latent diffusion models trained with our constraint are preferred over images from the Stable Diffusion V2 model 70% of the time. SOTA monocular depth estimation models such as DPT and PixelFormer, fine-tuned on our images, outperform the original models trained on real images by up to 7.03% in RMSE and 19.3% in SqRel on the KITTI test set for zero-shot transfer.
Student Activity Recognition in Classroom Environments using Transfer Learning
Dec 01, 2023The recent advances in artificial intelligence and deep learning facilitate automation in various applications including home automation, smart surveillance systems, and healthcare among others. Human Activity Recognition is one of its emerging applications, which can be implemented in a classroom environment to enhance safety, efficiency, and overall educational quality. This paper proposes a system for detecting and recognizing the activities of students in a classroom environment. The dataset has been structured and recorded by the authors since a standard dataset for this task was not available at the time of this study. Transfer learning, a widely adopted method within the field of deep learning, has proven to be helpful in complex tasks like image and video processing. Pretrained models including VGG-16, ResNet-50, InceptionV3, and Xception are used for feature extraction and classification tasks. Xception achieved an accuracy of 93%, on the novel classroom dataset, outperforming the other three models in consideration. The system proposed in this study aims to introduce a safer and more productive learning environment for students and educators.