 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Parameterized Generative Adversarial Network Using Cyclic Projection for Explainable Medical Image Classification
Nov 24, 2023
Although current data augmentation methods are successful to alleviate the data insufficiency, conventional augmentation are primarily intra-domain while advanced generative adversarial networks (GANs) generate images remaining uncertain, particularly in small-scale datasets. In this paper, we propose a parameterized GAN (ParaGAN) that effectively controls the changes of synthetic samples among domains and highlights the attention regions for downstream classification. Specifically, ParaGAN incorporates projection distance parameters in cyclic projection and projects the source images to the decision boundary to obtain the class-difference maps. Our experiments show that ParaGAN can consistently outperform the existing augmentation methods with explainable classification on two small-scale medical datasets.
Choroidalyzer: An open-source, end-to-end pipeline for choroidal analysis in optical coherence tomography
Dec 05, 2023Purpose: To develop Choroidalyzer, an open-source, end-to-end pipeline for segmenting the choroid region, vessels, and fovea, and deriving choroidal thickness, area, and vascular index. Methods: We used 5,600 OCT B-scans (233 subjects, 6 systemic disease cohorts, 3 device types, 2 manufacturers). To generate region and vessel ground-truths, we used state-of-the-art automatic methods following manual correction of inaccurate segmentations, with foveal positions manually annotated. We trained a U-Net deep-learning model to detect the region, vessels, and fovea to calculate choroid thickness, area, and vascular index in a fovea-centred region of interest. We analysed segmentation agreement (AUC, Dice) and choroid metrics agreement (Pearson, Spearman, mean absolute error (MAE)) in internal and external test sets. We compared Choroidalyzer to two manual graders on a small subset of external test images and examined cases of high error. Results: Choroidalyzer took 0.299 seconds per image on a standard laptop and achieved excellent region (Dice: internal 0.9789, external 0.9749), very good vessel segmentation performance (Dice: internal 0.8817, external 0.8703) and excellent fovea location prediction (MAE: internal 3.9 pixels, external 3.4 pixels). For thickness, area, and vascular index, Pearson correlations were 0.9754, 0.9815, and 0.8285 (internal) / 0.9831, 0.9779, 0.7948 (external), respectively (all p<0.0001). Choroidalyzer's agreement with graders was comparable to the inter-grader agreement across all metrics. Conclusions: Choroidalyzer is an open-source, end-to-end pipeline that accurately segments the choroid and reliably extracts thickness, area, and vascular index. Especially choroidal vessel segmentation is a difficult and subjective task, and fully-automatic methods like Choroidalyzer could provide objectivity and standardisation.
Volumetric Rendering with Baked Quadrature Fields
Dec 02, 2023We propose a novel Neural Radiance Field (NeRF) representation for non-opaque scenes that allows fast inference by utilizing textured polygons. Despite the high-quality novel view rendering that NeRF provides, a critical limitation is that it relies on volume rendering that can be computationally expensive and does not utilize the advancements in modern graphics hardware. Existing methods for this problem fall short when it comes to modelling volumetric effects as they rely purely on surface rendering. We thus propose to model the scene with polygons, which can then be used to obtain the quadrature points required to model volumetric effects, and also their opacity and colour from the texture. To obtain such polygonal mesh, we train a specialized field whose zero-crossings would correspond to the quadrature points when volume rendering, and perform marching cubes on this field. We then rasterize the polygons and utilize the fragment shaders to obtain the final colour image. Our method allows rendering on various devices and easy integration with existing graphics frameworks while keeping the benefits of volume rendering alive.
SASSL: Enhancing Self-Supervised Learning via Neural Style Transfer
Dec 02, 2023Self-supervised learning relies heavily on data augmentation to extract meaningful representations from unlabeled images. While existing state-of-the-art augmentation pipelines incorporate a wide range of primitive transformations, these often disregard natural image structure. Thus, augmented samples can exhibit degraded semantic information and low stylistic diversity, affecting downstream performance of self-supervised representations. To overcome this, we propose SASSL: Style Augmentations for Self Supervised Learning, a novel augmentation technique based on Neural Style Transfer. The method decouples semantic and stylistic attributes in images and applies transformations exclusively to the style while preserving content, generating diverse augmented samples that better retain their semantic properties. Experimental results show our technique achieves a top-1 classification performance improvement of more than 2% on ImageNet compared to the well-established MoCo v2. We also measure transfer learning performance across five diverse datasets, observing significant improvements of up to 3.75%. Our experiments indicate that decoupling style from content information and transferring style across datasets to diversify augmentations can significantly improve downstream performance of self-supervised representations.
Token Fusion: Bridging the Gap between Token Pruning and Token Merging
Dec 02, 2023Vision Transformers (ViTs) have emerged as powerful backbones in computer vision, outperforming many traditional CNNs. However, their computational overhead, largely attributed to the self-attention mechanism, makes deployment on resource-constrained edge devices challenging. Multiple solutions rely on token pruning or token merging. In this paper, we introduce "Token Fusion" (ToFu), a method that amalgamates the benefits of both token pruning and token merging. Token pruning proves advantageous when the model exhibits sensitivity to input interpolations, while token merging is effective when the model manifests close to linear responses to inputs. We combine this to propose a new scheme called Token Fusion. Moreover, we tackle the limitations of average merging, which doesn't preserve the intrinsic feature norm, resulting in distributional shifts. To mitigate this, we introduce MLERP merging, a variant of the SLERP technique, tailored to merge multiple tokens while maintaining the norm distribution. ToFu is versatile, applicable to ViTs with or without additional training. Our empirical evaluations indicate that ToFu establishes new benchmarks in both classification and image generation tasks concerning computational efficiency and model accuracy.
Egocentric Whole-Body Motion Capture with FisheyeViT and Diffusion-Based Motion Refinement
Dec 02, 2023In this work, we explore egocentric whole-body motion capture using a single fisheye camera, which simultaneously estimates human body and hand motion. This task presents significant challenges due to three factors: the lack of high-quality datasets, fisheye camera distortion, and human body self-occlusion. To address these challenges, we propose a novel approach that leverages FisheyeViT to extract fisheye image features, which are subsequently converted into pixel-aligned 3D heatmap representations for 3D human body pose prediction. For hand tracking, we incorporate dedicated hand detection and hand pose estimation networks for regressing 3D hand poses. Finally, we develop a diffusion-based whole-body motion prior model to refine the estimated whole-body motion while accounting for joint uncertainties. To train these networks, we collect a large synthetic dataset, EgoWholeBody, comprising 840,000 high-quality egocentric images captured across a diverse range of whole-body motion sequences. Quantitative and qualitative evaluations demonstrate the effectiveness of our method in producing high-quality whole-body motion estimates from a single egocentric camera.
Image Prior and Posterior Conditional Probability Representation for Efficient Damage Assessment
Oct 26, 2023It is important to quantify Damage Assessment (DA) for Human Assistance and Disaster Response (HADR) applications. In this paper, to achieve efficient and scalable DA in HADR, an image prior and posterior conditional probability (IP2CP) is developed as an effective computational imaging representation. Equipped with the IP2CP representation, the matching pre- and post-disaster images are effectively encoded into one image that is then processed using deep learning approaches to determine the damage levels. Two scenarios of crucial importance for the practical use of DA in HADR applications are examined: pixel-wise semantic segmentation and patch-based contrastive learning-based global damage classification. Results achieved by IP2CP in both scenarios demonstrate promising performances, showing that our IP2CP-based methods within the deep learning framework can effectively achieve data and computational efficiency, which is of utmost importance for the DA in HADR applications.
CellMixer: Annotation-free Semantic Cell Segmentation of Heterogeneous Cell Populations
Dec 01, 2023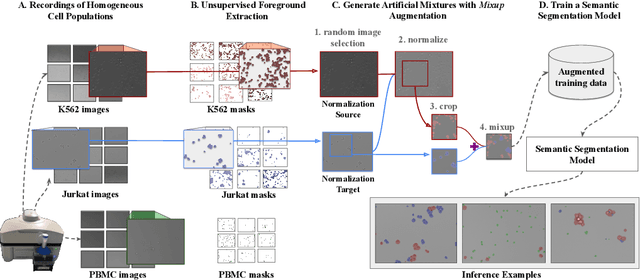
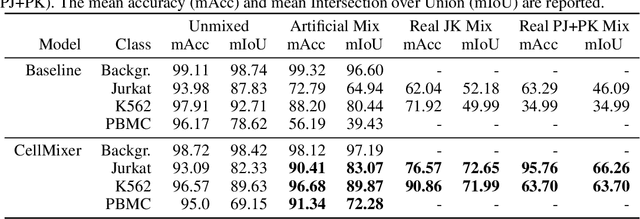

In recent years, several unsupervised cell segmentation methods have been presented, trying to omit the requirement of laborious pixel-level annotations for the training of a cell segmentation model. Most if not all of these methods handle the instance segmentation task by focusing on the detection of different cell instances ignoring their type. While such models prove adequate for certain tasks, like cell counting, other applications require the identification of each cell's type. In this paper, we present CellMixer, an innovative annotation-free approach for the semantic segmentation of heterogeneous cell populations. Our augmentation-based method enables the training of a segmentation model from image-level labels of homogeneous cell populations. Our results show that CellMixer can achieve competitive segmentation performance across multiple cell types and imaging modalities, demonstrating the method's scalability and potential for broader applications in medical imaging, cellular biology, and diagnostics.
DeepDR: Deep Structure-Aware RGB-D Inpainting for Diminished Reality
Dec 01, 2023Diminished reality (DR) refers to the removal of real objects from the environment by virtually replacing them with their background. Modern DR frameworks use inpainting to hallucinate unobserved regions. While recent deep learning-based inpainting is promising, the DR use case is complicated by the need to generate coherent structure and 3D geometry (i.e., depth), in particular for advanced applications, such as 3D scene editing. In this paper, we propose DeepDR, a first RGB-D inpainting framework fulfilling all requirements of DR: Plausible image and geometry inpainting with coherent structure, running at real-time frame rates, with minimal temporal artifacts. Our structure-aware generative network allows us to explicitly condition color and depth outputs on the scene semantics, overcoming the difficulty of reconstructing sharp and consistent boundaries in regions with complex backgrounds. Experimental results show that the proposed framework can outperform related work qualitatively and quantitatively.
REDUCR: Robust Data Downsampling Using Class Priority Reweighting
Dec 01, 2023Modern machine learning models are becoming increasingly expensive to train for real-world image and text classification tasks, where massive web-scale data is collected in a streaming fashion. To reduce the training cost, online batch selection techniques have been developed to choose the most informative datapoints. However, these techniques can suffer from poor worst-class generalization performance due to class imbalance and distributional shifts. This work introduces REDUCR, a robust and efficient data downsampling method that uses class priority reweighting. REDUCR reduces the training data while preserving worst-class generalization performance. REDUCR assigns priority weights to datapoints in a class-aware manner using an online learning algorithm. We demonstrate the data efficiency and robust performance of REDUCR on vision and text classification tasks. On web-scraped datasets with imbalanced class distributions, REDUCR significantly improves worst-class test accuracy (and average accuracy), surpassing state-of-the-art methods by around 15%.