 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Instance-guided Cartoon Editing with a Large-scale Dataset
Dec 04, 2023
Cartoon editing, appreciated by both professional illustrators and hobbyists, allows extensive creative freedom and the development of original narratives within the cartoon domain. However, the existing literature on cartoon editing is complex and leans heavily on manual operations, owing to the challenge of automatic identification of individual character instances. Therefore, an automated segmentation of these elements becomes imperative to facilitate a variety of cartoon editing applications such as visual style editing, motion decomposition and transfer, and the computation of stereoscopic depths for an enriched visual experience. Unfortunately, most current segmentation methods are designed for natural photographs, failing to recognize from the intricate aesthetics of cartoon subjects, thus lowering segmentation quality. The major challenge stems from two key shortcomings: the rarity of high-quality cartoon dedicated datasets and the absence of competent models for high-resolution instance extraction on cartoons. To address this, we introduce a high-quality dataset of over 100k paired high-resolution cartoon images and their instance labeling masks. We also present an instance-aware image segmentation model that can generate accurate, high-resolution segmentation masks for characters in cartoon images. We present that the proposed approach enables a range of segmentation-dependent cartoon editing applications like 3D Ken Burns parallax effects, text-guided cartoon style editing, and puppet animation from illustrations and manga.
Tell Me What Is Good About This Property: Leveraging Reviews For Segment-Personalized Image Collection Summarization
Oct 30, 2023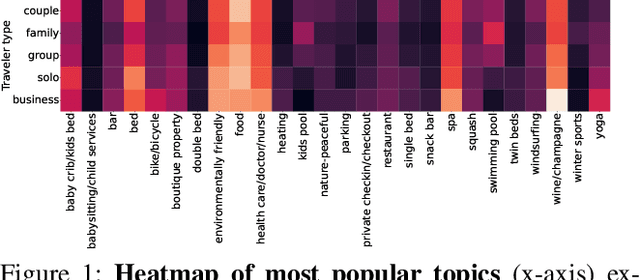

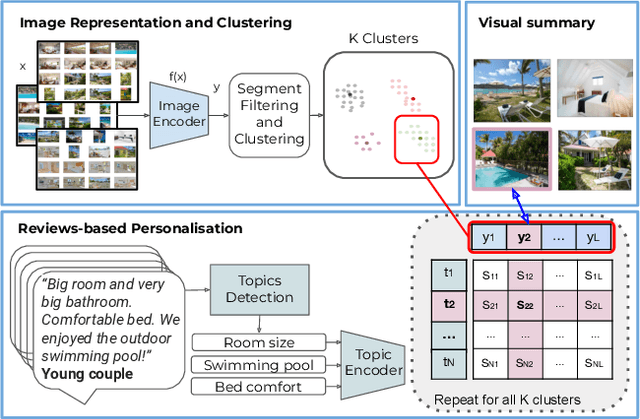
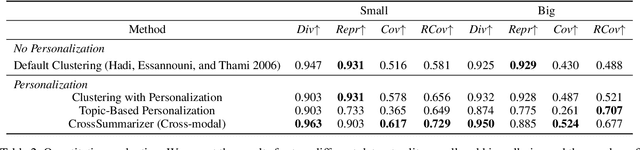
Image collection summarization techniques aim to present a compact representation of an image gallery through a carefully selected subset of images that captures its semantic content. When it comes to web content, however, the ideal selection can vary based on the user's specific intentions and preferences. This is particularly relevant at Booking.com, where presenting properties and their visual summaries that align with users' expectations is crucial. To address this challenge, we consider user intentions in the summarization of property visuals by analyzing property reviews and extracting the most significant aspects mentioned by users. By incorporating the insights from reviews in our visual summaries, we enhance the summaries by presenting the relevant content to a user. Moreover, we achieve it without the need for costly annotations. Our experiments, including human perceptual studies, demonstrate the superiority of our cross-modal approach, which we coin as CrossSummarizer over the no-personalization and image-based clustering baselines.
Enhanced Information Extraction from Cylindrical Visual-Tactile Sensors via Image Fusion
Nov 07, 2023Vision-based tactile sensors equipped with planar contact structures acquire the shape, force, and motion states of objects in contact. The limited planar contact area presents a challenge in acquiring information about larger target objects. In contrast, vision-based tactile sensors with cylindrical contact structures could extend the contact area by rolling, which can acquire much tactile information that exceeds the sensing projection area in a single contact. However, the tactile data acquired by cylindrical structures does not consistently correspond to the same depth level. Therefore, stitching and analyzing the data in an extended contact area is a challenging problem. In this work, we propose an image fusion method based on cylindrical vision-based tactile sensors. The method takes advantage of the changing characteristics of the contact depth of cylindrical structures, extracts the effective information of different contact depths in the frequency domain, and performs differential fusion for the information characteristics. The results show that in object contact confronting an area larger than single sensing, the images fused with our proposed method have higher information and structural similarity compared with the method of stitching based on motion distance sampling. Meanwhile, it is robust to sampling time. We complement this method with a deep neural network to illustrate its potential for fusing and recognizing object contact information using cylindrical vision-based tactile sensors.
A Picture is Worth a Thousand Words: Principled Recaptioning Improves Image Generation
Oct 25, 2023Text-to-image diffusion models achieved a remarkable leap in capabilities over the last few years, enabling high-quality and diverse synthesis of images from a textual prompt. However, even the most advanced models often struggle to precisely follow all of the directions in their prompts. The vast majority of these models are trained on datasets consisting of (image, caption) pairs where the images often come from the web, and the captions are their HTML alternate text. A notable example is the LAION dataset, used by Stable Diffusion and other models. In this work we observe that these captions are often of low quality, and argue that this significantly affects the model's capability to understand nuanced semantics in the textual prompts. We show that by relabeling the corpus with a specialized automatic captioning model and training a text-to-image model on the recaptioned dataset, the model benefits substantially across the board. First, in overall image quality: e.g. FID 14.84 vs. the baseline of 17.87, and 64.3% improvement in faithful image generation according to human evaluation. Second, in semantic alignment, e.g. semantic object accuracy 84.34 vs. 78.90, counting alignment errors 1.32 vs. 1.44 and positional alignment 62.42 vs. 57.60. We analyze various ways to relabel the corpus and provide evidence that this technique, which we call RECAP, both reduces the train-inference discrepancy and provides the model with more information per example, increasing sample efficiency and allowing the model to better understand the relations between captions and images.
Recaptured Raw Screen Image and Video Demoiréing via Channel and Spatial Modulations
Oct 31, 2023Capturing screen contents by smartphone cameras has become a common way for information sharing. However, these images and videos are often degraded by moir\'e patterns, which are caused by frequency aliasing between the camera filter array and digital display grids. We observe that the moir\'e patterns in raw domain is simpler than those in sRGB domain, and the moir\'e patterns in raw color channels have different properties. Therefore, we propose an image and video demoir\'eing network tailored for raw inputs. We introduce a color-separated feature branch, and it is fused with the traditional feature-mixed branch via channel and spatial modulations. Specifically, the channel modulation utilizes modulated color-separated features to enhance the color-mixed features. The spatial modulation utilizes the feature with large receptive field to modulate the feature with small receptive field. In addition, we build the first well-aligned raw video demoir\'eing (RawVDemoir\'e) dataset and propose an efficient temporal alignment method by inserting alternating patterns. Experiments demonstrate that our method achieves state-of-the-art performance for both image and video demori\'eing. We have released the code and dataset in https://github.com/tju-chengyijia/VD_raw.
GELDA: A generative language annotation framework to reveal visual biases in datasets
Nov 29, 2023Bias analysis is a crucial step in the process of creating fair datasets for training and evaluating computer vision models. The bottleneck in dataset analysis is annotation, which typically requires: (1) specifying a list of attributes relevant to the dataset domain, and (2) classifying each image-attribute pair. While the second step has made rapid progress in automation, the first has remained human-centered, requiring an experimenter to compile lists of in-domain attributes. However, an experimenter may have limited foresight leading to annotation "blind spots," which in turn can lead to flawed downstream dataset analyses. To combat this, we propose GELDA, a nearly automatic framework that leverages large generative language models (LLMs) to propose and label various attributes for a domain. GELDA takes a user-defined domain caption (e.g., "a photo of a bird," "a photo of a living room") and uses an LLM to hierarchically generate attributes. In addition, GELDA uses the LLM to decide which of a set of vision-language models (VLMs) to use to classify each attribute in images. Results on real datasets show that GELDA can generate accurate and diverse visual attribute suggestions, and uncover biases such as confounding between class labels and background features. Results on synthetic datasets demonstrate that GELDA can be used to evaluate the biases of text-to-image diffusion models and generative adversarial networks. Overall, we show that while GELDA is not accurate enough to replace human annotators, it can serve as a complementary tool to help humans analyze datasets in a cheap, low-effort, and flexible manner.
Non-Visible Light Data Synthesis and Application: A Case Study for Synthetic Aperture Radar Imagery
Nov 29, 2023We explore the "hidden" ability of large-scale pre-trained image generation models, such as Stable Diffusion and Imagen, in non-visible light domains, taking Synthetic Aperture Radar (SAR) data for a case study. Due to the inherent challenges in capturing satellite data, acquiring ample SAR training samples is infeasible. For instance, for a particular category of ship in the open sea, we can collect only few-shot SAR images which are too limited to derive effective ship recognition models. If large-scale models pre-trained with regular images can be adapted to generating novel SAR images, the problem is solved. In preliminary study, we found that fine-tuning these models with few-shot SAR images is not working, as the models can not capture the two primary differences between SAR and regular images: structure and modality. To address this, we propose a 2-stage low-rank adaptation method, and we call it 2LoRA. In the first stage, the model is adapted using aerial-view regular image data (whose structure matches SAR), followed by the second stage where the base model from the first stage is further adapted using SAR modality data. Particularly in the second stage, we introduce a novel prototype LoRA (pLoRA), as an improved version of 2LoRA, to resolve the class imbalance problem in SAR datasets. For evaluation, we employ the resulting generation model to synthesize additional SAR data. This augmentation, when integrated into the training process of SAR classification as well as segmentation models, yields notably improved performance for minor classes
PaintNeSF: Artistic Creation of Stylized Scenes with Vectorized 3D Strokes
Nov 27, 2023We present Paint Neural Stroke Field (PaintNeSF), a novel technique to generate stylized images of a 3D scene at arbitrary novel views from multi-view 2D images. Different from existing methods which apply stylization to trained neural radiance fields at the voxel level, our approach draws inspiration from image-to-painting methods, simulating the progressive painting process of human artwork with vector strokes. We develop a palette of stylized 3D strokes from basic primitives and splines, and consider the 3D scene stylization task as a multi-view reconstruction process based on these 3D stroke primitives. Instead of directly searching for the parameters of these 3D strokes, which would be too costly, we introduce a differentiable renderer that allows optimizing stroke parameters using gradient descent, and propose a training scheme to alleviate the vanishing gradient issue. The extensive evaluation demonstrates that our approach effectively synthesizes 3D scenes with significant geometric and aesthetic stylization while maintaining a consistent appearance across different views. Our method can be further integrated with style loss and image-text contrastive models to extend its applications, including color transfer and text-driven 3D scene drawing.
Improving Denoising Diffusion Models via Simultaneous Estimation of Image and Noise
Oct 26, 2023This paper introduces two key contributions aimed at improving the speed and quality of images generated through inverse diffusion processes. The first contribution involves reparameterizing the diffusion process in terms of the angle on a quarter-circular arc between the image and noise, specifically setting the conventional $\displaystyle \sqrt{\bar{\alpha}}=\cos(\eta)$. This reparameterization eliminates two singularities and allows for the expression of diffusion evolution as a well-behaved ordinary differential equation (ODE). In turn, this allows higher order ODE solvers such as Runge-Kutta methods to be used effectively. The second contribution is to directly estimate both the image ($\mathbf{x}_0$) and noise ($\mathbf{\epsilon}$) using our network, which enables more stable calculations of the update step in the inverse diffusion steps, as accurate estimation of both the image and noise are crucial at different stages of the process. Together with these changes, our model achieves faster generation, with the ability to converge on high-quality images more quickly, and higher quality of the generated images, as measured by metrics such as Frechet Inception Distance (FID), spatial Frechet Inception Distance (sFID), precision, and recall.
Video Summarization: Towards Entity-Aware Captions
Dec 01, 2023Existing popular video captioning benchmarks and models deal with generic captions devoid of specific person, place or organization named entities. In contrast, news videos present a challenging setting where the caption requires such named entities for meaningful summarization. As such, we propose the task of summarizing news video directly to entity-aware captions. We also release a large-scale dataset, VIEWS (VIdeo NEWS), to support research on this task. Further, we propose a method that augments visual information from videos with context retrieved from external world knowledge to generate entity-aware captions. We demonstrate the effectiveness of our approach on three video captioning models. We also show that our approach generalizes to existing news image captions dataset. With all the extensive experiments and insights, we believe we establish a solid basis for future research on this challenging task.