 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Latent Diffusion Prior Enhanced Deep Unfolding for Spectral Image Reconstruction
Nov 24, 2023
Snapshot compressive spectral imaging reconstruction aims to reconstruct three-dimensional spatial-spectral images from a single-shot two-dimensional compressed measurement. Existing state-of-the-art methods are mostly based on deep unfolding structures but have intrinsic performance bottlenecks: $i$) the ill-posed problem of dealing with heavily degraded measurement, and $ii$) the regression loss-based reconstruction models being prone to recover images with few details. In this paper, we introduce a generative model, namely the latent diffusion model (LDM), to generate degradation-free prior to enhance the regression-based deep unfolding method. Furthermore, to overcome the large computational cost challenge in LDM, we propose a lightweight model to generate knowledge priors in deep unfolding denoiser, and integrate these priors to guide the reconstruction process for compensating high-quality spectral signal details. Numeric and visual comparisons on synthetic and real-world datasets illustrate the superiority of our proposed method in both reconstruction quality and computational efficiency. Code will be released.
Osteoporosis Prediction from Hand and Wrist X-rays using Image Segmentation and Self-Supervised Learning
Nov 12, 2023Osteoporosis is a widespread and chronic metabolic bone disease that often remains undiagnosed and untreated due to limited access to bone mineral density (BMD) tests like Dual-energy X-ray absorptiometry (DXA). In response to this challenge, current advancements are pivoting towards detecting osteoporosis by examining alternative indicators from peripheral bone areas, with the goal of increasing screening rates without added expenses or time. In this paper, we present a method to predict osteoporosis using hand and wrist X-ray images, which are both widely accessible and affordable, though their link to DXA-based data is not thoroughly explored. Initially, our method segments the ulnar, radius, and metacarpal bones using a foundational model for image segmentation. Then, we use a self-supervised learning approach to extract meaningful representations without the need for explicit labels, and move on to classify osteoporosis in a supervised manner. Our method is evaluated on a dataset with 192 individuals, cross-referencing their verified osteoporosis conditions against the standard DXA test. With a notable classification score (AUC=0.83), our model represents a pioneering effort in leveraging vision-based techniques for osteoporosis identification from the peripheral skeleton sites.
DiffusionAtlas: High-Fidelity Consistent Diffusion Video Editing
Dec 05, 2023We present a diffusion-based video editing framework, namely DiffusionAtlas, which can achieve both frame consistency and high fidelity in editing video object appearance. Despite the success in image editing, diffusion models still encounter significant hindrances when it comes to video editing due to the challenge of maintaining spatiotemporal consistency in the object's appearance across frames. On the other hand, atlas-based techniques allow propagating edits on the layered representations consistently back to frames. However, they often struggle to create editing effects that adhere correctly to the user-provided textual or visual conditions due to the limitation of editing the texture atlas on a fixed UV mapping field. Our method leverages a visual-textual diffusion model to edit objects directly on the diffusion atlases, ensuring coherent object identity across frames. We design a loss term with atlas-based constraints and build a pretrained text-driven diffusion model as pixel-wise guidance for refining shape distortions and correcting texture deviations. Qualitative and quantitative experiments show that our method outperforms state-of-the-art methods in achieving consistent high-fidelity video-object editing.
Breast Ultrasound Report Generation using LangChain
Dec 05, 2023Breast ultrasound (BUS) is a critical diagnostic tool in the field of breast imaging, aiding in the early detection and characterization of breast abnormalities. Interpreting breast ultrasound images commonly involves creating comprehensive medical reports, containing vital information to promptly assess the patient's condition. However, the ultrasound imaging system necessitates capturing multiple images of various parts to compile a single report, presenting a time-consuming challenge. To address this problem, we propose the integration of multiple image analysis tools through a LangChain using Large Language Models (LLM), into the breast reporting process. Through a combination of designated tools and text generation through LangChain, our method can accurately extract relevant features from ultrasound images, interpret them in a clinical context, and produce comprehensive and standardized reports. This approach not only reduces the burden on radiologists and healthcare professionals but also enhances the consistency and quality of reports. The extensive experiments shows that each tools involved in the proposed method can offer qualitatively and quantitatively significant results. Furthermore, clinical evaluation on the generated reports demonstrates that the proposed method can make report in clinically meaningful way.
Imitating Shortest Paths in Simulation Enables Effective Navigation and Manipulation in the Real World
Dec 05, 2023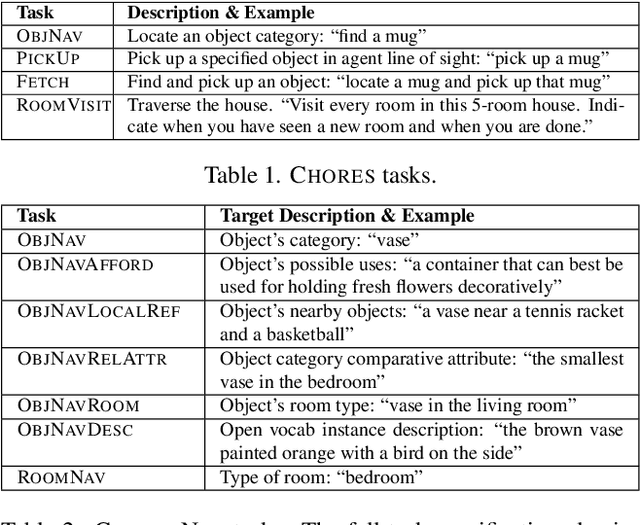
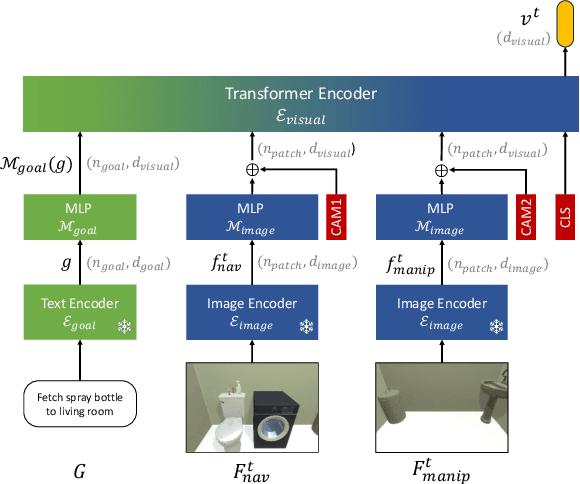
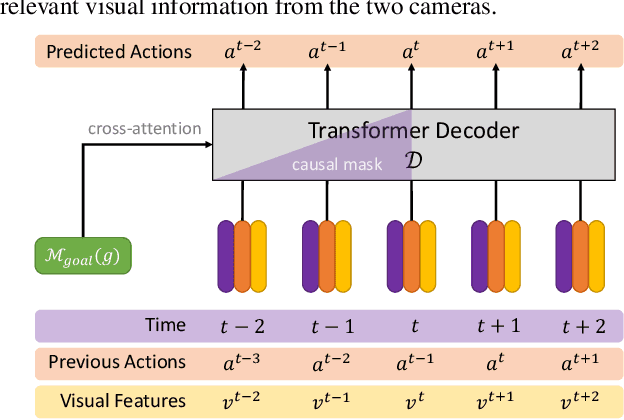

Reinforcement learning (RL) with dense rewards and imitation learning (IL) with human-generated trajectories are the most widely used approaches for training modern embodied agents. RL requires extensive reward shaping and auxiliary losses and is often too slow and ineffective for long-horizon tasks. While IL with human supervision is effective, collecting human trajectories at scale is extremely expensive. In this work, we show that imitating shortest-path planners in simulation produces agents that, given a language instruction, can proficiently navigate, explore, and manipulate objects in both simulation and in the real world using only RGB sensors (no depth map or GPS coordinates). This surprising result is enabled by our end-to-end, transformer-based, SPOC architecture, powerful visual encoders paired with extensive image augmentation, and the dramatic scale and diversity of our training data: millions of frames of shortest-path-expert trajectories collected inside approximately 200,000 procedurally generated houses containing 40,000 unique 3D assets. Our models, data, training code, and newly proposed 10-task benchmarking suite CHORES will be open-sourced.
BEDD: The MineRL BASALT Evaluation and Demonstrations Dataset for Training and Benchmarking Agents that Solve Fuzzy Tasks
Dec 05, 2023The MineRL BASALT competition has served to catalyze advances in learning from human feedback through four hard-to-specify tasks in Minecraft, such as create and photograph a waterfall. Given the completion of two years of BASALT competitions, we offer to the community a formalized benchmark through the BASALT Evaluation and Demonstrations Dataset (BEDD), which serves as a resource for algorithm development and performance assessment. BEDD consists of a collection of 26 million image-action pairs from nearly 14,000 videos of human players completing the BASALT tasks in Minecraft. It also includes over 3,000 dense pairwise human evaluations of human and algorithmic agents. These comparisons serve as a fixed, preliminary leaderboard for evaluating newly-developed algorithms. To enable this comparison, we present a streamlined codebase for benchmarking new algorithms against the leaderboard. In addition to presenting these datasets, we conduct a detailed analysis of the data from both datasets to guide algorithm development and evaluation. The released code and data are available at https://github.com/minerllabs/basalt-benchmark .
Analyzing and Improving the Training Dynamics of Diffusion Models
Dec 05, 2023Diffusion models currently dominate the field of data-driven image synthesis with their unparalleled scaling to large datasets. In this paper, we identify and rectify several causes for uneven and ineffective training in the popular ADM diffusion model architecture, without altering its high-level structure. Observing uncontrolled magnitude changes and imbalances in both the network activations and weights over the course of training, we redesign the network layers to preserve activation, weight, and update magnitudes on expectation. We find that systematic application of this philosophy eliminates the observed drifts and imbalances, resulting in considerably better networks at equal computational complexity. Our modifications improve the previous record FID of 2.41 in ImageNet-512 synthesis to 1.81, achieved using fast deterministic sampling. As an independent contribution, we present a method for setting the exponential moving average (EMA) parameters post-hoc, i.e., after completing the training run. This allows precise tuning of EMA length without the cost of performing several training runs, and reveals its surprising interactions with network architecture, training time, and guidance.
Towards More Unified In-context Visual Understanding
Dec 05, 2023The rapid advancement of large language models (LLMs) has accelerated the emergence of in-context learning (ICL) as a cutting-edge approach in the natural language processing domain. Recently, ICL has been employed in visual understanding tasks, such as semantic segmentation and image captioning, yielding promising results. However, existing visual ICL framework can not enable producing content across multiple modalities, which limits their potential usage scenarios. To address this issue, we present a new ICL framework for visual understanding with multi-modal output enabled. First, we quantize and embed both text and visual prompt into a unified representational space, structured as interleaved in-context sequences. Then a decoder-only sparse transformer architecture is employed to perform generative modeling on them, facilitating in-context learning. Thanks to this design, the model is capable of handling in-context vision understanding tasks with multimodal output in a unified pipeline. Experimental results demonstrate that our model achieves competitive performance compared with specialized models and previous ICL baselines. Overall, our research takes a further step toward unified multimodal in-context learning.
Towards Real-World Focus Stacking with Deep Learning
Nov 29, 2023Focus stacking is widely used in micro, macro, and landscape photography to reconstruct all-in-focus images from multiple frames obtained with focus bracketing, that is, with shallow depth of field and different focus planes. Existing deep learning approaches to the underlying multi-focus image fusion problem have limited applicability to real-world imagery since they are designed for very short image sequences (two to four images), and are typically trained on small, low-resolution datasets either acquired by light-field cameras or generated synthetically. We introduce a new dataset consisting of 94 high-resolution bursts of raw images with focus bracketing, with pseudo ground truth computed from the data using state-of-the-art commercial software. This dataset is used to train the first deep learning algorithm for focus stacking capable of handling bursts of sufficient length for real-world applications. Qualitative experiments demonstrate that it is on par with existing commercial solutions in the long-burst, realistic regime while being significantly more tolerant to noise. The code and dataset are available at https://github.com/araujoalexandre/FocusStackingDataset.
LiveNVS: Neural View Synthesis on Live RGB-D Streams
Nov 29, 2023Existing real-time RGB-D reconstruction approaches, like Kinect Fusion, lack real-time photo-realistic visualization. This is due to noisy, oversmoothed or incomplete geometry and blurry textures which are fused from imperfect depth maps and camera poses. Recent neural rendering methods can overcome many of such artifacts but are mostly optimized for offline usage, hindering the integration into a live reconstruction pipeline. In this paper, we present LiveNVS, a system that allows for neural novel view synthesis on a live RGB-D input stream with very low latency and real-time rendering. Based on the RGB-D input stream, novel views are rendered by projecting neural features into the target view via a densely fused depth map and aggregating the features in image-space to a target feature map. A generalizable neural network then translates the target feature map into a high-quality RGB image. LiveNVS achieves state-of-the-art neural rendering quality of unknown scenes during capturing, allowing users to virtually explore the scene and assess reconstruction quality in real-time.