 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving Medical Report Generation with Adapter Tuning and Knowledge Enhancement in Vision-Language Foundation Models
Dec 07, 2023
Medical report generation demands automatic creation of coherent and precise descriptions for medical images. However, the scarcity of labelled medical image-report pairs poses formidable challenges in developing large-scale neural networks capable of harnessing the potential of artificial intelligence, exemplified by large language models. This study builds upon the state-of-the-art vision-language pre-training and fine-tuning approach, BLIP-2, to customize general large-scale foundation models. Integrating adapter tuning and a medical knowledge enhancement loss, our model significantly improves accuracy and coherence. Validation on the dataset of ImageCLEFmedical 2023 demonstrates our model's prowess, achieving the best-averaged results against several state-of-the-art methods. Significant improvements in ROUGE and CIDEr underscore our method's efficacy, highlighting promising outcomes for the rapid medical-domain adaptation of the vision-language foundation models in addressing challenges posed by data scarcity.
Dream2Real: Zero-Shot 3D Object Rearrangement with Vision-Language Models
Dec 07, 2023We introduce Dream2Real, a robotics framework which integrates vision-language models (VLMs) trained on 2D data into a 3D object rearrangement pipeline. This is achieved by the robot autonomously constructing a 3D representation of the scene, where objects can be rearranged virtually and an image of the resulting arrangement rendered. These renders are evaluated by a VLM, so that the arrangement which best satisfies the user instruction is selected and recreated in the real world with pick-and-place. This enables language-conditioned rearrangement to be performed zero-shot, without needing to collect a training dataset of example arrangements. Results on a series of real-world tasks show that this framework is robust to distractors, controllable by language, capable of understanding complex multi-object relations, and readily applicable to both tabletop and 6-DoF rearrangement tasks.
Guided Flows for Generative Modeling and Decision Making
Dec 07, 2023Classifier-free guidance is a key component for enhancing the performance of conditional generative models across diverse tasks. While it has previously demonstrated remarkable improvements for the sample quality, it has only been exclusively employed for diffusion models. In this paper, we integrate classifier-free guidance into Flow Matching (FM) models, an alternative simulation-free approach that trains Continuous Normalizing Flows (CNFs) based on regressing vector fields. We explore the usage of \emph{Guided Flows} for a variety of downstream applications. We show that Guided Flows significantly improves the sample quality in conditional image generation and zero-shot text-to-speech synthesis, boasting state-of-the-art performance. Notably, we are the first to apply flow models for plan generation in the offline reinforcement learning setting, showcasing a 10x speedup in computation compared to diffusion models while maintaining comparable performance.
Disentangled Interaction Representation for One-Stage Human-Object Interaction Detection
Dec 04, 2023

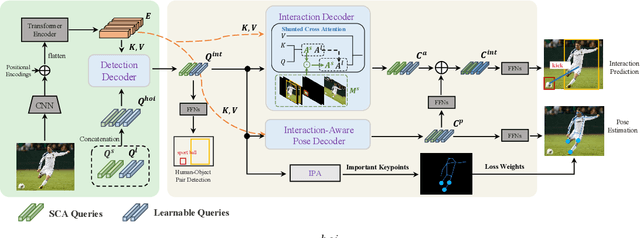
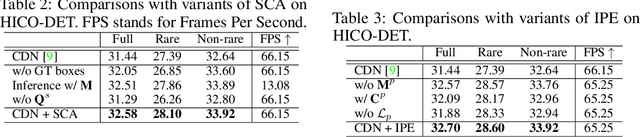
Human-Object Interaction (HOI) detection is a core task for human-centric image understanding. Recent one-stage methods adopt a transformer decoder to collect image-wide cues that are useful for interaction prediction; however, the interaction representations obtained using this method are entangled and lack interpretability. In contrast, traditional two-stage methods benefit significantly from their ability to compose interaction features in a disentangled and explainable manner. In this paper, we improve the performance of one-stage methods by enabling them to extract disentangled interaction representations. First, we propose Shunted Cross-Attention (SCA) to extract human appearance, object appearance, and global context features using different cross-attention heads. This is achieved by imposing different masks on the cross-attention maps produced by the different heads. Second, we introduce the Interaction-aware Pose Estimation (IPE) task to learn interaction-relevant human pose features using a disentangled decoder. This is achieved with a novel attention module that accurately captures the human keypoints relevant to the current interaction category. Finally, our approach fuses the appearance feature and pose feature via element-wise addition to form the interaction representation. Experimental results show that our approach can be readily applied to existing one-stage HOI detectors. Moreover, we achieve state-of-the-art performance on two benchmarks: HICO-DET and V-COCO.
Can SAM recognize crops? Quantifying the zero-shot performance of a semantic segmentation foundation model on generating crop-type maps using satellite imagery for precision agriculture
Dec 04, 2023Climate change is increasingly disrupting worldwide agriculture, making global food production less reliable. To tackle the growing challenges in feeding the planet, cutting-edge management strategies, such as precision agriculture, empower farmers and decision-makers with rich and actionable information to increase the efficiency and sustainability of their farming practices. Crop-type maps are key information for decision-support tools but are challenging and costly to generate. We investigate the capabilities of Meta AI's Segment Anything Model (SAM) for crop-map prediction task, acknowledging its recent successes at zero-shot image segmentation. However, SAM being limited to up-to 3 channel inputs and its zero-shot usage being class-agnostic in nature pose unique challenges in using it directly for crop-type mapping. We propose using clustering consensus metrics to assess SAM's zero-shot performance in segmenting satellite imagery and producing crop-type maps. Although direct crop-type mapping is challenging using SAM in zero-shot setting, experiments reveal SAM's potential for swiftly and accurately outlining fields in satellite images, serving as a foundation for subsequent crop classification. This paper attempts to highlight a use-case of state-of-the-art image segmentation models like SAM for crop-type mapping and related specific needs of the agriculture industry, offering a potential avenue for automatic, efficient, and cost-effective data products for precision agriculture practices.
Sam-Guided Enhanced Fine-Grained Encoding with Mixed Semantic Learning for Medical Image Captioning
Nov 02, 2023With the development of multimodality and large language models, the deep learning-based technique for medical image captioning holds the potential to offer valuable diagnostic recommendations. However, current generic text and image pre-trained models do not yield satisfactory results when it comes to describing intricate details within medical images. In this paper, we present a novel medical image captioning method guided by the segment anything model (SAM) to enable enhanced encoding with both general and detailed feature extraction. In addition, our approach employs a distinctive pre-training strategy with mixed semantic learning to simultaneously capture both the overall information and finer details within medical images. We demonstrate the effectiveness of this approach, as it outperforms the pre-trained BLIP2 model on various evaluation metrics for generating descriptions of medical images.
Distance Weighted Trans Network for Image Completion
Oct 25, 2023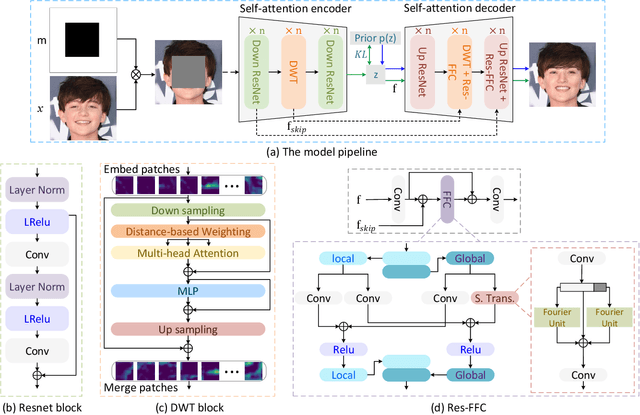
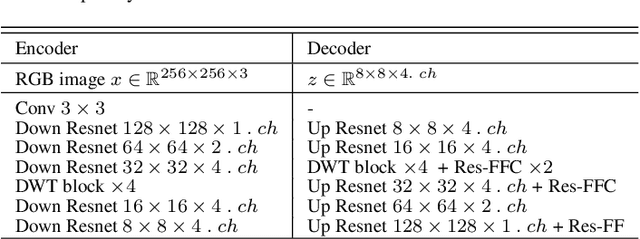

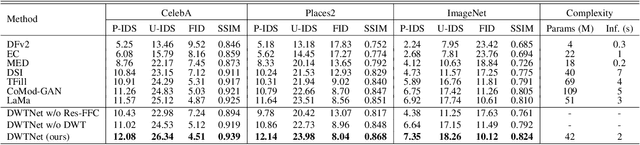
The challenge of image generation has been effectively modeled as a problem of structure priors or transformation. However, existing models have unsatisfactory performance in understanding the global input image structures because of particular inherent features (for example, local inductive prior). Recent studies have shown that self-attention is an efficient modeling technique for image completion problems. In this paper, we propose a new architecture that relies on Distance-based Weighted Transformer (DWT) to better understand the relationships between an image's components. In our model, we leverage the strengths of both Convolutional Neural Networks (CNNs) and DWT blocks to enhance the image completion process. Specifically, CNNs are used to augment the local texture information of coarse priors and DWT blocks are used to recover certain coarse textures and coherent visual structures. Unlike current approaches that generally use CNNs to create feature maps, we use the DWT to encode global dependencies and compute distance-based weighted feature maps, which substantially minimizes the problem of visual ambiguities. Meanwhile, to better produce repeated textures, we introduce Residual Fast Fourier Convolution (Res-FFC) blocks to combine the encoder's skip features with the coarse features provided by our generator. Furthermore, a simple yet effective technique is proposed to normalize the non-zero values of convolutions, and fine-tune the network layers for regularization of the gradient norms to provide an efficient training stabiliser. Extensive quantitative and qualitative experiments on three challenging datasets demonstrate the superiority of our proposed model compared to existing approaches.
High-Resolution Reference Image Assisted Volumetric Super-Resolution of Cardiac Diffusion Weighted Imaging
Oct 31, 2023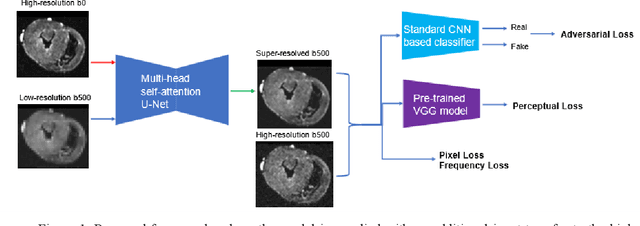

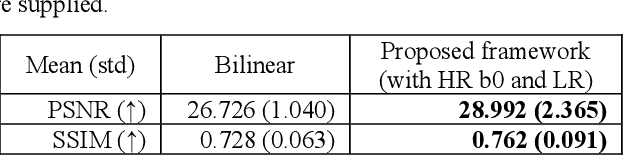
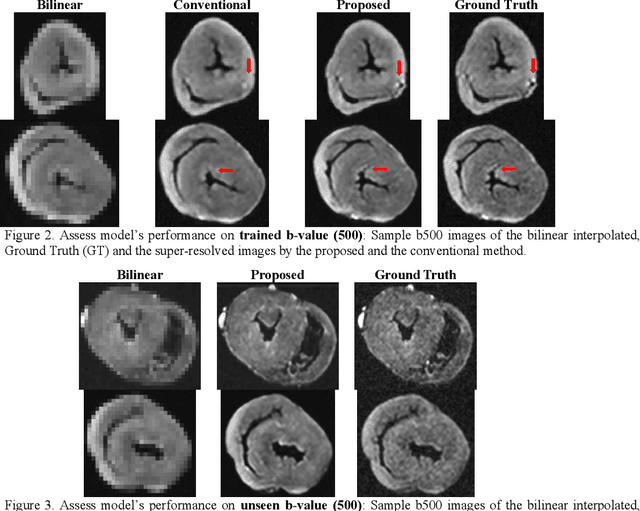
Diffusion Tensor Cardiac Magnetic Resonance (DT-CMR) is the only in vivo method to non-invasively examine the microstructure of the human heart. Current research in DT-CMR aims to improve the understanding of how the cardiac microstructure relates to the macroscopic function of the healthy heart as well as how microstructural dysfunction contributes to disease. To get the final DT-CMR metrics, we need to acquire diffusion weighted images of at least 6 directions. However, due to DWI's low signal-to-noise ratio, the standard voxel size is quite big on the scale for microstructures. In this study, we explored the potential of deep-learning-based methods in improving the image quality volumetrically (x4 in all dimensions). This study proposed a novel framework to enable volumetric super-resolution, with an additional model input of high-resolution b0 DWI. We demonstrated that the additional input could offer higher super-resolved image quality. Going beyond, the model is also able to super-resolve DWIs of unseen b-values, proving the model framework's generalizability for cardiac DWI superresolution. In conclusion, we would then recommend giving the model a high-resolution reference image as an additional input to the low-resolution image for training and inference to guide all super-resolution frameworks for parametric imaging where a reference image is available.
Augment the Pairs: Semantics-Preserving Image-Caption Pair Augmentation for Grounding-Based Vision and Language Models
Nov 05, 2023Grounding-based vision and language models have been successfully applied to low-level vision tasks, aiming to precisely locate objects referred in captions. The effectiveness of grounding representation learning heavily relies on the scale of the training dataset. Despite being a useful data enrichment strategy, data augmentation has received minimal attention in existing vision and language tasks as augmentation for image-caption pairs is non-trivial. In this study, we propose a robust phrase grounding model trained with text-conditioned and text-unconditioned data augmentations. Specifically, we apply text-conditioned color jittering and horizontal flipping to ensure semantic consistency between images and captions. To guarantee image-caption correspondence in the training samples, we modify the captions according to pre-defined keywords when applying horizontal flipping. Additionally, inspired by recent masked signal reconstruction, we propose to use pixel-level masking as a novel form of data augmentation. While we demonstrate our data augmentation method with MDETR framework, the proposed approach is applicable to common grounding-based vision and language tasks with other frameworks. Finally, we show that image encoder pretrained on large-scale image and language datasets (such as CLIP) can further improve the results. Through extensive experiments on three commonly applied datasets: Flickr30k, referring expressions and GQA, our method demonstrates advanced performance over the state-of-the-arts with various metrics. Code can be found in https://github.com/amzn/augment-the-pairs-wacv2024.
Learning Anatomically Consistent Embedding for Chest Radiography
Dec 01, 2023Self-supervised learning (SSL) approaches have recently shown substantial success in learning visual representations from unannotated images. Compared with photographic images, medical images acquired with the same imaging protocol exhibit high consistency in anatomy. To exploit this anatomical consistency, this paper introduces a novel SSL approach, called PEAC (patch embedding of anatomical consistency), for medical image analysis. Specifically, in this paper, we propose to learn global and local consistencies via stable grid-based matching, transfer pre-trained PEAC models to diverse downstream tasks, and extensively demonstrate that (1) PEAC achieves significantly better performance than the existing state-of-the-art fully/self-supervised methods, and (2) PEAC captures the anatomical structure consistency across views of the same patient and across patients of different genders, weights, and healthy statuses, which enhances the interpretability of our method for medical image analysis.