 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Generating Action-conditioned Prompts for Open-vocabulary Video Action Recognition
Dec 04, 2023
Exploring open-vocabulary video action recognition is a promising venture, which aims to recognize previously unseen actions within any arbitrary set of categories. Existing methods typically adapt pretrained image-text models to the video domain, capitalizing on their inherent strengths in generalization. A common thread among such methods is the augmentation of visual embeddings with temporal information to improve the recognition of seen actions. Yet, they compromise with standard less-informative action descriptions, thus faltering when confronted with novel actions. Drawing inspiration from human cognitive processes, we argue that augmenting text embeddings with human prior knowledge is pivotal for open-vocabulary video action recognition. To realize this, we innovatively blend video models with Large Language Models (LLMs) to devise Action-conditioned Prompts. Specifically, we harness the knowledge in LLMs to produce a set of descriptive sentences that contain distinctive features for identifying given actions. Building upon this foundation, we further introduce a multi-modal action knowledge alignment mechanism to align concepts in video and textual knowledge encapsulated within the prompts. Extensive experiments on various video benchmarks, including zero-shot, few-shot, and base-to-novel generalization settings, demonstrate that our method not only sets new SOTA performance but also possesses excellent interpretability.
Typhoon Intensity Prediction with Vision Transformer
Dec 04, 2023Predicting typhoon intensity accurately across space and time is crucial for issuing timely disaster warnings and facilitating emergency response. This has vast potential for minimizing life losses and property damages as well as reducing economic and environmental impacts. Leveraging satellite imagery for scenario analysis is effective but also introduces additional challenges due to the complex relations among clouds and the highly dynamic context. Existing deep learning methods in this domain rely on convolutional neural networks (CNNs), which suffer from limited per-layer receptive fields. This limitation hinders their ability to capture long-range dependencies and global contextual knowledge during inference. In response, we introduce a novel approach, namely "Typhoon Intensity Transformer" (Tint), which leverages self-attention mechanisms with global receptive fields per layer. Tint adopts a sequence-to-sequence feature representation learning perspective. It begins by cutting a given satellite image into a sequence of patches and recursively employs self-attention operations to extract both local and global contextual relations between all patch pairs simultaneously, thereby enhancing per-patch feature representation learning. Extensive experiments on a publicly available typhoon benchmark validate the efficacy of Tint in comparison with both state-of-the-art deep learning and conventional meteorological methods. Our code is available at https://github.com/chen-huanxin/Tint.
Optimal Transport Aggregation for Visual Place Recognition
Nov 27, 2023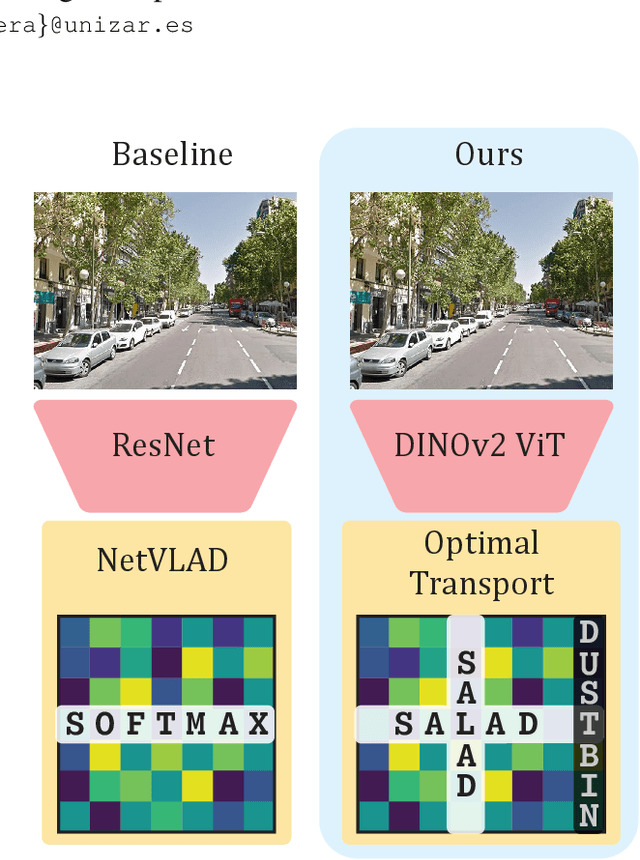

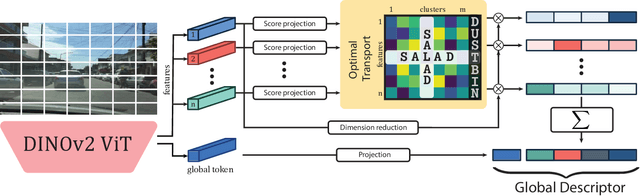

The task of Visual Place Recognition (VPR) aims to match a query image against references from an extensive database of images from different places, relying solely on visual cues. State-of-the-art pipelines focus on the aggregation of features extracted from a deep backbone, in order to form a global descriptor for each image. In this context, we introduce SALAD (Sinkhorn Algorithm for Locally Aggregated Descriptors), which reformulates NetVLAD's soft-assignment of local features to clusters as an optimal transport problem. In SALAD, we consider both feature-to-cluster and cluster-to-feature relations and we also introduce a 'dustbin' cluster, designed to selectively discard features deemed non-informative, enhancing the overall descriptor quality. Additionally, we leverage and fine-tune DINOv2 as a backbone, which provides enhanced description power for the local features, and dramatically reduces the required training time. As a result, our single-stage method not only surpasses single-stage baselines in public VPR datasets, but also surpasses two-stage methods that add a re-ranking with significantly higher cost. Code and models are available at https://github.com/serizba/salad.
FlowZero: Zero-Shot Text-to-Video Synthesis with LLM-Driven Dynamic Scene Syntax
Nov 27, 2023Text-to-video (T2V) generation is a rapidly growing research area that aims to translate the scenes, objects, and actions within complex video text into a sequence of coherent visual frames. We present FlowZero, a novel framework that combines Large Language Models (LLMs) with image diffusion models to generate temporally-coherent videos. FlowZero uses LLMs to understand complex spatio-temporal dynamics from text, where LLMs can generate a comprehensive dynamic scene syntax (DSS) containing scene descriptions, object layouts, and background motion patterns. These elements in DSS are then used to guide the image diffusion model for video generation with smooth object motions and frame-to-frame coherence. Moreover, FlowZero incorporates an iterative self-refinement process, enhancing the alignment between the spatio-temporal layouts and the textual prompts for the videos. To enhance global coherence, we propose enriching the initial noise of each frame with motion dynamics to control the background movement and camera motion adaptively. By using spatio-temporal syntaxes to guide the diffusion process, FlowZero achieves improvement in zero-shot video synthesis, generating coherent videos with vivid motion.
Concept Sliders: LoRA Adaptors for Precise Control in Diffusion Models
Nov 27, 2023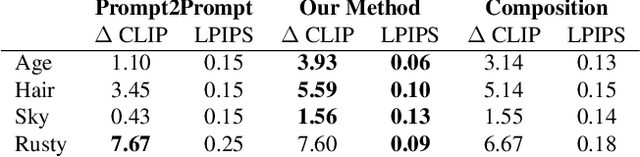
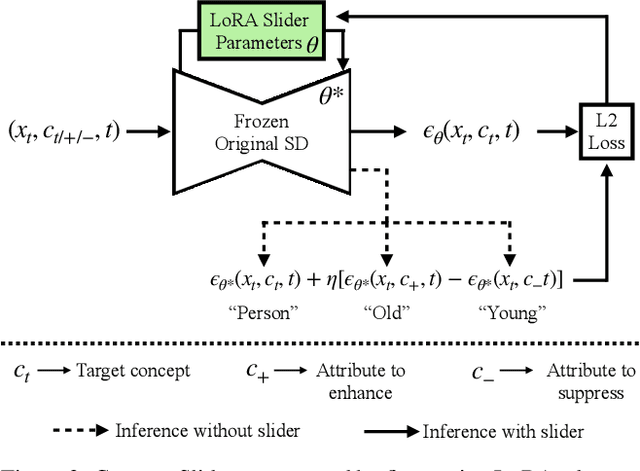


We present a method to create interpretable concept sliders that enable precise control over attributes in image generations from diffusion models. Our approach identifies a low-rank parameter direction corresponding to one concept while minimizing interference with other attributes. A slider is created using a small set of prompts or sample images; thus slider directions can be created for either textual or visual concepts. Concept Sliders are plug-and-play: they can be composed efficiently and continuously modulated, enabling precise control over image generation. In quantitative experiments comparing to previous editing techniques, our sliders exhibit stronger targeted edits with lower interference. We showcase sliders for weather, age, styles, and expressions, as well as slider compositions. We show how sliders can transfer latents from StyleGAN for intuitive editing of visual concepts for which textual description is difficult. We also find that our method can help address persistent quality issues in Stable Diffusion XL including repair of object deformations and fixing distorted hands. Our code, data, and trained sliders are available at https://sliders.baulab.info/
ImagenHub: Standardizing the evaluation of conditional image generation models
Oct 17, 2023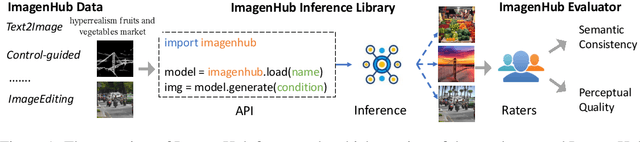
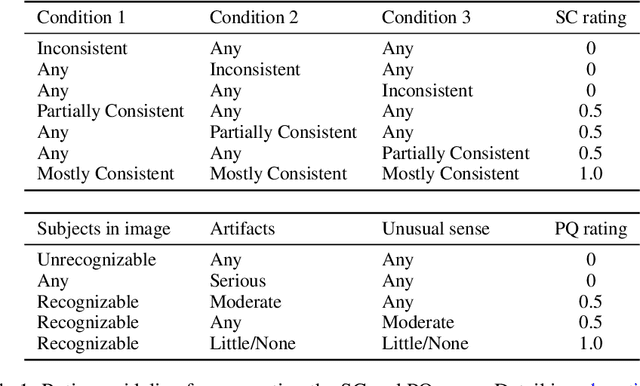
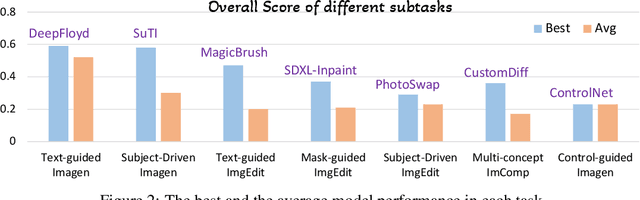
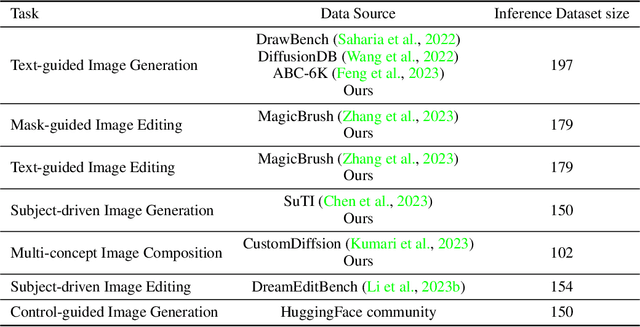
Recently, a myriad of conditional image generation and editing models have been developed to serve different downstream tasks, including text-to-image generation, text-guided image editing, subject-driven image generation, control-guided image generation, etc. However, we observe huge inconsistencies in experimental conditions: datasets, inference, and evaluation metrics - render fair comparisons difficult. This paper proposes ImagenHub, which is a one-stop library to standardize the inference and evaluation of all the conditional image generation models. Firstly, we define seven prominent tasks and curate high-quality evaluation datasets for them. Secondly, we built a unified inference pipeline to ensure fair comparison. Thirdly, we design two human evaluation scores, i.e. Semantic Consistency and Perceptual Quality, along with comprehensive guidelines to evaluate generated images. We train expert raters to evaluate the model outputs based on the proposed metrics. Our human evaluation achieves a high inter-worker agreement of Krippendorff's alpha on 76% models with a value higher than 0.4. We comprehensively evaluated a total of around 30 models and observed three key takeaways: (1) the existing models' performance is generally unsatisfying except for Text-guided Image Generation and Subject-driven Image Generation, with 74% models achieving an overall score lower than 0.5. (2) we examined the claims from published papers and found 83% of them hold with a few exceptions. (3) None of the existing automatic metrics has a Spearman's correlation higher than 0.2 except subject-driven image generation. Moving forward, we will continue our efforts to evaluate newly published models and update our leaderboard to keep track of the progress in conditional image generation.
FuseNet: Self-Supervised Dual-Path Network for Medical Image Segmentation
Nov 22, 2023Semantic segmentation, a crucial task in computer vision, often relies on labor-intensive and costly annotated datasets for training. In response to this challenge, we introduce FuseNet, a dual-stream framework for self-supervised semantic segmentation that eliminates the need for manual annotation. FuseNet leverages the shared semantic dependencies between the original and augmented images to create a clustering space, effectively assigning pixels to semantically related clusters, and ultimately generating the segmentation map. Additionally, FuseNet incorporates a cross-modal fusion technique that extends the principles of CLIP by replacing textual data with augmented images. This approach enables the model to learn complex visual representations, enhancing robustness against variations similar to CLIP's text invariance. To further improve edge alignment and spatial consistency between neighboring pixels, we introduce an edge refinement loss. This loss function considers edge information to enhance spatial coherence, facilitating the grouping of nearby pixels with similar visual features. Extensive experiments on skin lesion and lung segmentation datasets demonstrate the effectiveness of our method. \href{https://github.com/xmindflow/FuseNet}{Codebase.}
Toward a Surgeon-in-the-Loop Ophthalmic Robotic Apprentice using Reinforcement and Imitation Learning
Nov 29, 2023Robotic-assisted surgical systems have demonstrated significant potential in enhancing surgical precision and minimizing human errors. However, existing systems lack the ability to accommodate the unique preferences and requirements of individual surgeons. Additionally, they primarily focus on general surgeries (e.g., laparoscopy) and are not suitable for highly precise microsurgeries, such as ophthalmic procedures. Thus, we propose a simulation-based image-guided approach for surgeon-centered autonomous agents that can adapt to the individual surgeon's skill level and preferred surgical techniques during ophthalmic cataract surgery. Our approach utilizes a simulated environment to train reinforcement and imitation learning agents guided by image data to perform all tasks of the incision phase of cataract surgery. By integrating the surgeon's actions and preferences into the training process with the surgeon-in-the-loop, our approach enables the robot to implicitly learn and adapt to the individual surgeon's unique approach through demonstrations. This results in a more intuitive and personalized surgical experience for the surgeon. Simultaneously, it ensures consistent performance for the autonomous robotic apprentice. We define and evaluate the effectiveness of our approach using our proposed metrics; and highlight the trade-off between a generic agent and a surgeon-centered adapted agent. Moreover, our approach has the potential to extend to other ophthalmic surgical procedures, opening the door to a new generation of surgeon-in-the-loop autonomous surgical robots. We provide an open-source simulation framework for future development and reproducibility.
OPERA: Alleviating Hallucination in Multi-Modal Large Language Models via Over-Trust Penalty and Retrospection-Allocation
Nov 29, 2023Hallucination, posed as a pervasive challenge of multi-modal large language models (MLLMs), has significantly impeded their real-world usage that demands precise judgment. Existing methods mitigate this issue with either training with specific designed data or inferencing with external knowledge from other sources, incurring inevitable additional costs. In this paper, we present OPERA, a novel MLLM decoding method grounded in an Over-trust Penalty and a Retrospection-Allocation strategy, serving as a nearly free lunch to alleviate the hallucination issue without additional data, knowledge, or training. Our approach begins with an interesting observation that, most hallucinations are closely tied to the knowledge aggregation patterns manifested in the self-attention matrix, i.e., MLLMs tend to generate new tokens by focusing on a few summary tokens, but not all the previous tokens. Such partial over-trust inclination results in the neglecting of image tokens and describes the image content with hallucination. Statistically, we observe an 80%$\sim$95% co-currency rate between hallucination contents and such knowledge aggregation patterns. Based on the observation, OPERA introduces a penalty term on the model logits during the beam-search decoding to mitigate the over-trust issue, along with a rollback strategy that retrospects the presence of summary tokens in the previously generated tokens, and re-allocate the token selection if necessary. With extensive experiments, OPERA shows significant hallucination-mitigating performance on different MLLMs and metrics, proving its effectiveness and generality. Our code is available at: https://github.com/shikiw/OPERA.
UC-NeRF: Neural Radiance Field for Under-Calibrated multi-view cameras in autonomous driving
Nov 28, 2023Multi-camera setups find widespread use across various applications, such as autonomous driving, as they greatly expand sensing capabilities. Despite the fast development of Neural radiance field (NeRF) techniques and their wide applications in both indoor and outdoor scenes, applying NeRF to multi-camera systems remains very challenging. This is primarily due to the inherent under-calibration issues in multi-camera setup, including inconsistent imaging effects stemming from separately calibrated image signal processing units in diverse cameras, and system errors arising from mechanical vibrations during driving that affect relative camera poses. In this paper, we present UC-NeRF, a novel method tailored for novel view synthesis in under-calibrated multi-view camera systems. Firstly, we propose a layer-based color correction to rectify the color inconsistency in different image regions. Second, we propose virtual warping to generate more viewpoint-diverse but color-consistent virtual views for color correction and 3D recovery. Finally, a spatiotemporally constrained pose refinement is designed for more robust and accurate pose calibration in multi-camera systems. Our method not only achieves state-of-the-art performance of novel view synthesis in multi-camera setups, but also effectively facilitates depth estimation in large-scale outdoor scenes with the synthesized novel views.