 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Improving In-Context Learning in Diffusion Models with Visual Context-Modulated Prompts
Dec 03, 2023
In light of the remarkable success of in-context learning in large language models, its potential extension to the vision domain, particularly with visual foundation models like Stable Diffusion, has sparked considerable interest. Existing approaches in visual in-context learning frequently face hurdles such as expensive pretraining, limiting frameworks, inadequate visual comprehension, and limited adaptability to new tasks. In response to these challenges, we introduce improved Prompt Diffusion (iPromptDiff) in this study. iPromptDiff integrates an end-to-end trained vision encoder that converts visual context into an embedding vector. This vector is subsequently used to modulate the token embeddings of text prompts. We show that a diffusion-based vision foundation model, when equipped with this visual context-modulated text guidance and a standard ControlNet structure, exhibits versatility and robustness across a variety of training tasks and excels in in-context learning for novel vision tasks, such as normal-to-image or image-to-line transformations. The effectiveness of these capabilities relies heavily on a deep visual understanding, which is achieved through relevant visual demonstrations processed by our proposed in-context learning architecture.
Re-Scoring Using Image-Language Similarity for Few-Shot Object Detection
Nov 01, 2023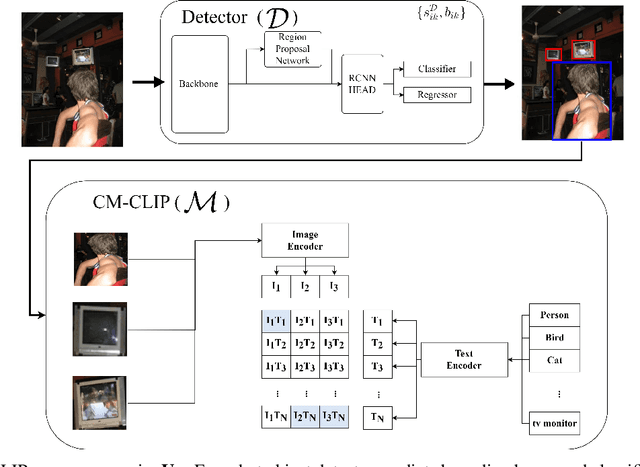
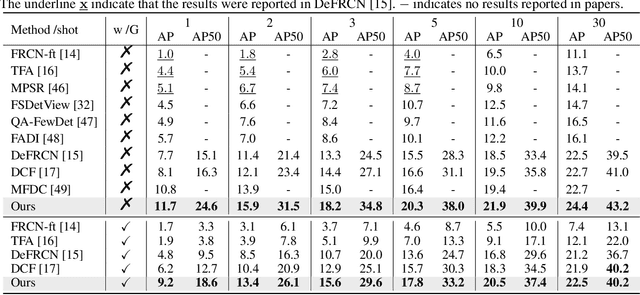
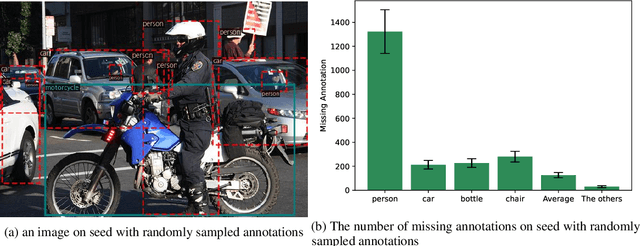
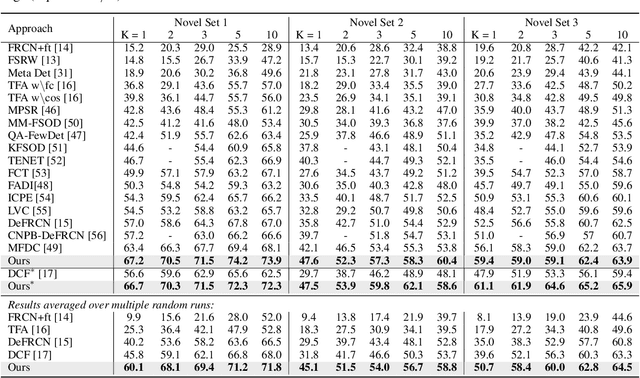
Few-shot object detection, which focuses on detecting novel objects with few labels, is an emerging challenge in the community. Recent studies show that adapting a pre-trained model or modified loss function can improve performance. In this paper, we explore leveraging the power of Contrastive Language-Image Pre-training (CLIP) and hard negative classification loss in low data setting. Specifically, we propose Re-scoring using Image-language Similarity for Few-shot object detection (RISF) which extends Faster R-CNN by introducing Calibration Module using CLIP (CM-CLIP) and Background Negative Re-scale Loss (BNRL). The former adapts CLIP, which performs zero-shot classification, to re-score the classification scores of a detector using image-class similarities, the latter is modified classification loss considering the punishment for fake backgrounds as well as confusing categories on a generalized few-shot object detection dataset. Extensive experiments on MS-COCO and PASCAL VOC show that the proposed RISF substantially outperforms the state-of-the-art approaches. The code will be available.
MagicStick: Controllable Video Editing via Control Handle Transformations
Dec 05, 2023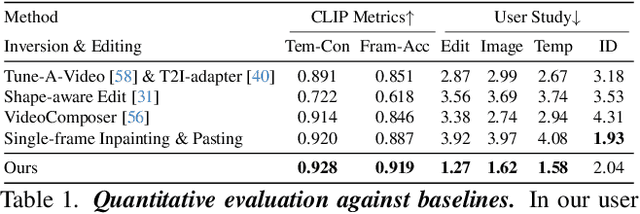
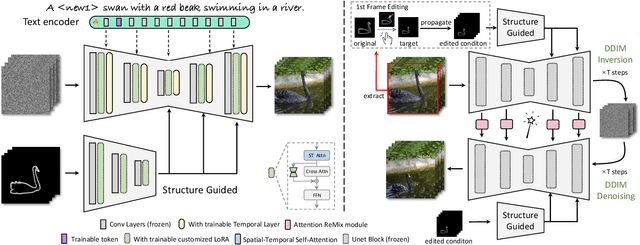
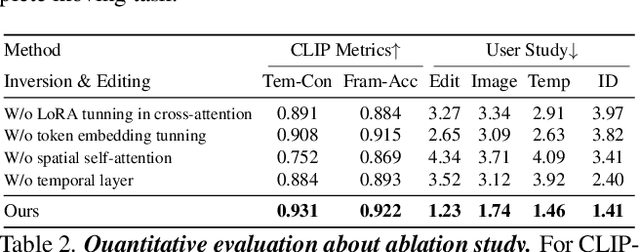
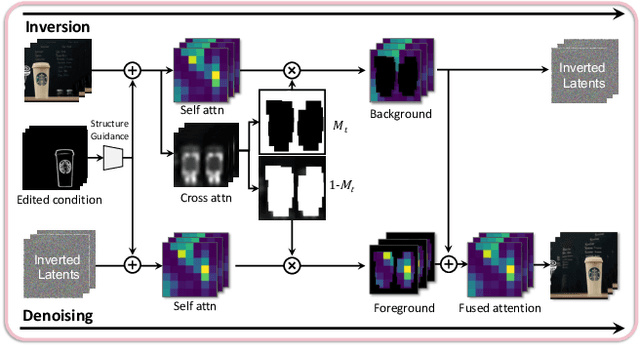
Text-based video editing has recently attracted considerable interest in changing the style or replacing the objects with a similar structure. Beyond this, we demonstrate that properties such as shape, size, location, motion, etc., can also be edited in videos. Our key insight is that the keyframe transformations of the specific internal feature (e.g., edge maps of objects or human pose), can easily propagate to other frames to provide generation guidance. We thus propose MagicStick, a controllable video editing method that edits the video properties by utilizing the transformation on the extracted internal control signals. In detail, to keep the appearance, we inflate both the pretrained image diffusion model and ControlNet to the temporal dimension and train low-rank adaptions (LORA) layers to fit the specific scenes. Then, in editing, we perform an inversion and editing framework. Differently, finetuned ControlNet is introduced in both inversion and generation for attention guidance with the proposed attention remix between the spatial attention maps of inversion and editing. Yet succinct, our method is the first method to show the ability of video property editing from the pre-trained text-to-image model. We present experiments on numerous examples within our unified framework. We also compare with shape-aware text-based editing and handcrafted motion video generation, demonstrating our superior temporal consistency and editing capability than previous works. The code and models will be made publicly available.
Double Integral Enhanced Zeroing Neural Network Optimized with ALSOA fostered Lung Cancer Classification using CT Images
Dec 05, 2023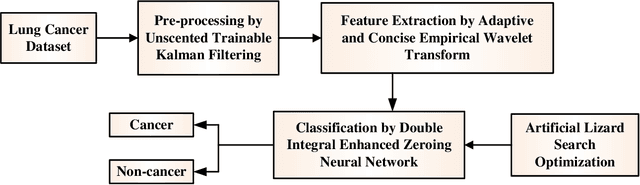
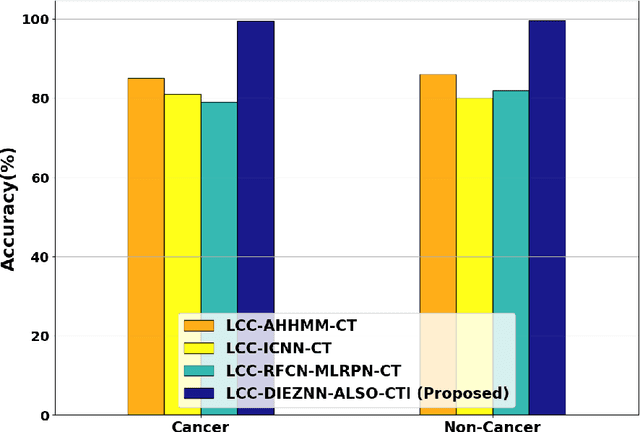
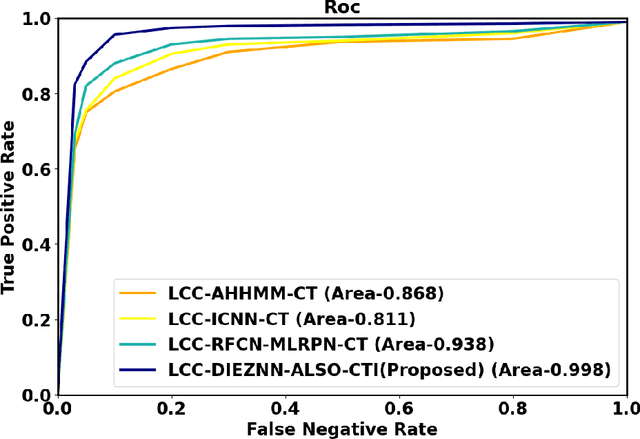
Lung cancer is one of the deadliest diseases and the leading cause of illness and death. Since lung cancer cannot predicted at premature stage, it able to only be discovered more broadly once it has spread to other lung parts. The risk grows when radiologists and other specialists determine whether lung cancer is current. Owing to significance of determining type of treatment and its depth based on severity of the illness, critical to develop smart and automatic cancer prediction scheme is precise, at which stage of cancer. In this paper, Double Integral Enhanced Zeroing Neural Network Optimized with ALSOA fostered Lung Cancer Classification using CT Images (LCC-DIEZNN-ALSO-CTI) is proposed. Initially, input CT image is amassed from lung cancer dataset. The input CT image is pre-processing via Unscented Trainable Kalman Filtering (UTKF) technique. In pre-processing stage unwanted noise are removed from CT images. Afterwards, grayscale statistic features and Haralick texture features extracted by Adaptive and Concise Empirical Wavelet Transform (ACEWT). The proposed model is implemented on MATLAB. The performance of the proposed method is analyzed through existing techniques. The proposed method attains 18.32%, 27.20%, and 34.32% higher accuracy analyzed with existing method likes Deep Learning Assisted Predict of Lung Cancer on Computed Tomography Images Utilizing AHHMM (LCC-AHHMM-CT), Convolutional neural networks based pulmonary nodule malignancy assessment in pipeline for classifying lung cancer (LCC-ICNN-CT), Automated Decision Support Scheme for Lung Cancer Identification with Categorization (LCC-RFCN-MLRPN-CT) methods respectively.
X-Adapter: Adding Universal Compatibility of Plugins for Upgraded Diffusion Model
Dec 04, 2023We introduce X-Adapter, a universal upgrader to enable the pretrained plug-and-play modules (e.g., ControlNet, LoRA) to work directly with the upgraded text-to-image diffusion model (e.g., SDXL) without further retraining. We achieve this goal by training an additional network to control the frozen upgraded model with the new text-image data pairs. In detail, X-Adapter keeps a frozen copy of the old model to preserve the connectors of different plugins. Additionally, X-Adapter adds trainable mapping layers that bridge the decoders from models of different versions for feature remapping. The remapped features will be used as guidance for the upgraded model. To enhance the guidance ability of X-Adapter, we employ a null-text training strategy for the upgraded model. After training, we also introduce a two-stage denoising strategy to align the initial latents of X-Adapter and the upgraded model. Thanks to our strategies, X-Adapter demonstrates universal compatibility with various plugins and also enables plugins of different versions to work together, thereby expanding the functionalities of diffusion community. To verify the effectiveness of the proposed method, we conduct extensive experiments and the results show that X-Adapter may facilitate wider application in the upgraded foundational diffusion model.
Effective Adapter for Face Recognition in the Wild
Dec 04, 2023In this paper, we tackle the challenge of face recognition in the wild, where images often suffer from low quality and real-world distortions. Traditional heuristic approaches-either training models directly on these degraded images or their enhanced counterparts using face restoration techniques-have proven ineffective, primarily due to the degradation of facial features and the discrepancy in image domains. To overcome these issues, we propose an effective adapter for augmenting existing face recognition models trained on high-quality facial datasets. The key of our adapter is to process both the unrefined and the enhanced images by two similar structures where one is fixed and the other trainable. Such design can confer two benefits. First, the dual-input system minimizes the domain gap while providing varied perspectives for the face recognition model, where the enhanced image can be regarded as a complex non-linear transformation of the original one by the restoration model. Second, both two similar structures can be initialized by the pre-trained models without dropping the past knowledge. The extensive experiments in zero-shot settings show the effectiveness of our method by surpassing baselines of about 3%, 4%, and 7% in three datasets. Our code will be publicly available at https://github.com/liuyunhaozz/FaceAdapter/.
Mixture of Gaussian-distributed Prototypes with Generative Modelling for Interpretable Image Classification
Nov 30, 2023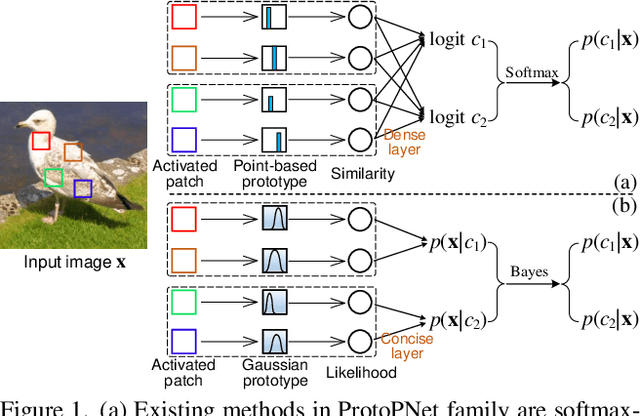
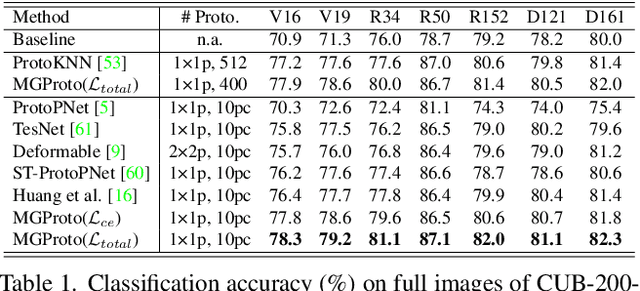
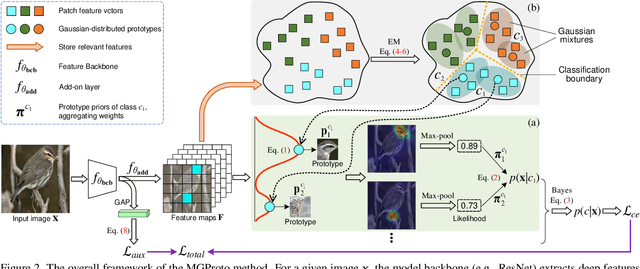

Prototypical-part interpretable methods, e.g., ProtoPNet, enhance interpretability by connecting classification predictions to class-specific training prototypes, thereby offering an intuitive insight into their decision-making. Current methods rely on a discriminative classifier trained with point-based learning techniques that provide specific values for prototypes. Such prototypes have relatively low representation power due to their sparsity and potential redundancy, with each prototype containing no variability measure. In this paper, we present a new generative learning of prototype distributions, named Mixture of Gaussian-distributed Prototypes (MGProto), which are represented by Gaussian mixture models (GMM). Such an approach enables the learning of more powerful prototype representations since each learned prototype will own a measure of variability, which naturally reduces the sparsity given the spread of the distribution around each prototype, and we also integrate a prototype diversity objective function into the GMM optimisation to reduce redundancy. Incidentally, the generative nature of MGProto offers a new and effective way for detecting out-of-distribution samples. To improve the compactness of MGProto, we further propose to prune Gaussian-distributed prototypes with a low prior. Experiments on CUB-200-2011, Stanford Cars, Stanford Dogs, and Oxford-IIIT Pets datasets show that MGProto achieves state-of-the-art classification and OoD detection performances with encouraging interpretability results.
Visible to Thermal image Translation for improving visual task in low light conditions
Oct 31, 2023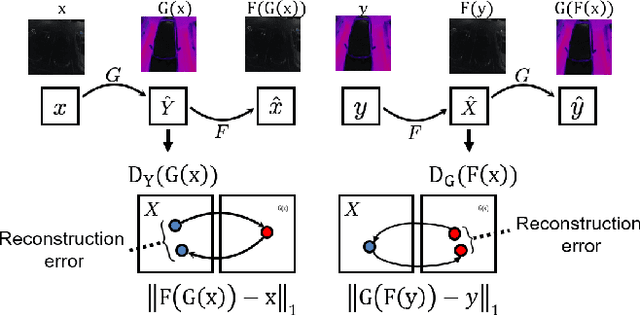
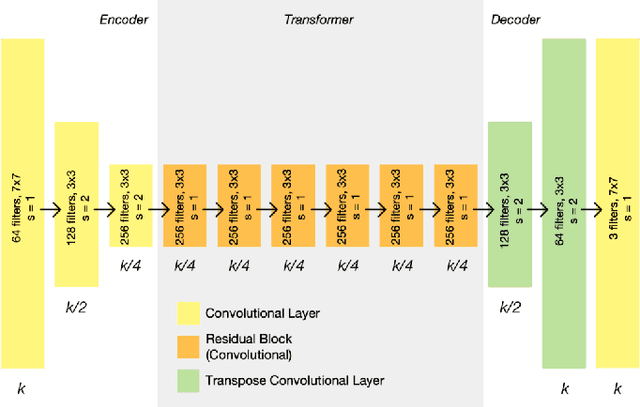
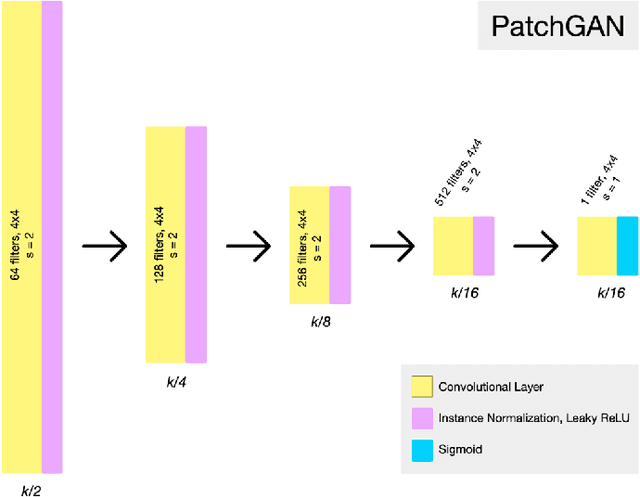
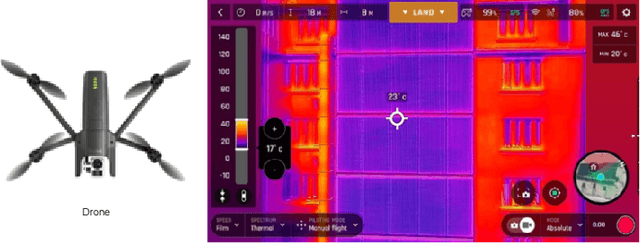
Several visual tasks, such as pedestrian detection and image-to-image translation, are challenging to accomplish in low light using RGB images. Heat variation of objects in thermal images can be used to overcome this. In this work, an end-to-end framework, which consists of a generative network and a detector network, is proposed to translate RGB image into Thermal ones and compare generated thermal images with real data. We have collected images from two different locations using the Parrot Anafi Thermal drone. After that, we created a two-stream network, preprocessed, augmented, the image data, and trained the generator and discriminator models from scratch. The findings demonstrate that it is feasible to translate RGB training data to thermal data using GAN. As a result, thermal data can now be produced more quickly and affordably, which is useful for security and surveillance applications.
DARNet: Bridging Domain Gaps in Cross-Domain Few-Shot Segmentation with Dynamic Adaptation
Dec 08, 2023
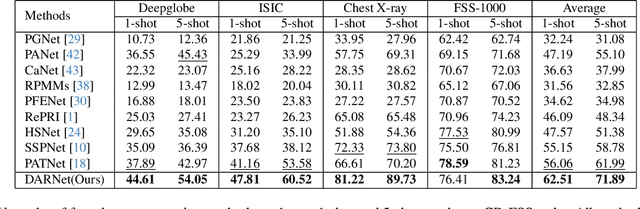
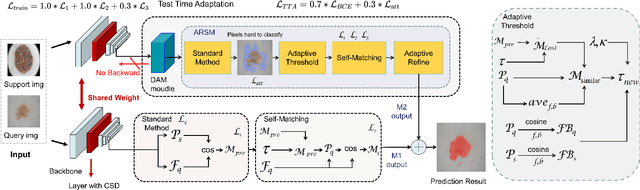
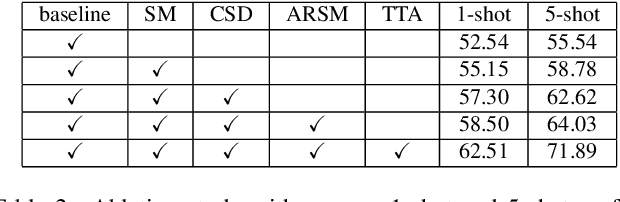
Few-shot segmentation (FSS) aims to segment novel classes in a query image by using only a small number of supporting images from base classes. However, in cross-domain few-shot segmentation (CD-FSS), leveraging features from label-rich domains for resource-constrained domains poses challenges due to domain discrepancies. This work presents a Dynamically Adaptive Refine (DARNet) method that aims to balance generalization and specificity for CD-FSS. Our method includes the Channel Statistics Disruption (CSD) strategy, which perturbs feature channel statistics in the source domain, bolstering generalization to unknown target domains. Moreover, recognizing the variability across target domains, an Adaptive Refine Self-Matching (ARSM) method is also proposed to adjust the matching threshold and dynamically refine the prediction result with the self-matching method, enhancing accuracy. We also present a Test-Time Adaptation (TTA) method to refine the model's adaptability to diverse feature distributions. Our approach demonstrates superior performance against state-of-the-art methods in CD-FSS tasks.
ET3D: Efficient Text-to-3D Generation via Multi-View Distillation
Nov 27, 2023Recent breakthroughs in text-to-image generation has shown encouraging results via large generative models. Due to the scarcity of 3D assets, it is hardly to transfer the success of text-to-image generation to that of text-to-3D generation. Existing text-to-3D generation methods usually adopt the paradigm of DreamFusion, which conducts per-asset optimization by distilling a pretrained text-to-image diffusion model. The generation speed usually ranges from several minutes to tens of minutes per 3D asset, which degrades the user experience and also imposes a burden to the service providers due to the high computational budget. In this work, we present an efficient text-to-3D generation method, which requires only around 8 $ms$ to generate a 3D asset given the text prompt on a consumer graphic card. The main insight is that we exploit the images generated by a large pre-trained text-to-image diffusion model, to supervise the training of a text conditioned 3D generative adversarial network. Once the network is trained, we are able to efficiently generate a 3D asset via a single forward pass. Our method requires no 3D training data and provides an alternative approach for efficient text-to-3D generation by distilling pre-trained image diffusion models.