 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Orthogonal Adaptation for Modular Customization of Diffusion Models
Dec 05, 2023
Customization techniques for text-to-image models have paved the way for a wide range of previously unattainable applications, enabling the generation of specific concepts across diverse contexts and styles. While existing methods facilitate high-fidelity customization for individual concepts or a limited, pre-defined set of them, they fall short of achieving scalability, where a single model can seamlessly render countless concepts. In this paper, we address a new problem called Modular Customization, with the goal of efficiently merging customized models that were fine-tuned independently for individual concepts. This allows the merged model to jointly synthesize concepts in one image without compromising fidelity or incurring any additional computational costs. To address this problem, we introduce Orthogonal Adaptation, a method designed to encourage the customized models, which do not have access to each other during fine-tuning, to have orthogonal residual weights. This ensures that during inference time, the customized models can be summed with minimal interference. Our proposed method is both simple and versatile, applicable to nearly all optimizable weights in the model architecture. Through an extensive set of quantitative and qualitative evaluations, our method consistently outperforms relevant baselines in terms of efficiency and identity preservation, demonstrating a significant leap toward scalable customization of diffusion models.
UPOCR: Towards Unified Pixel-Level OCR Interface
Dec 05, 2023In recent years, the optical character recognition (OCR) field has been proliferating with plentiful cutting-edge approaches for a wide spectrum of tasks. However, these approaches are task-specifically designed with divergent paradigms, architectures, and training strategies, which significantly increases the complexity of research and maintenance and hinders the fast deployment in applications. To this end, we propose UPOCR, a simple-yet-effective generalist model for Unified Pixel-level OCR interface. Specifically, the UPOCR unifies the paradigm of diverse OCR tasks as image-to-image transformation and the architecture as a vision Transformer (ViT)-based encoder-decoder. Learnable task prompts are introduced to push the general feature representations extracted by the encoder toward task-specific spaces, endowing the decoder with task awareness. Moreover, the model training is uniformly aimed at minimizing the discrepancy between the generated and ground-truth images regardless of the inhomogeneity among tasks. Experiments are conducted on three pixel-level OCR tasks including text removal, text segmentation, and tampered text detection. Without bells and whistles, the experimental results showcase that the proposed method can simultaneously achieve state-of-the-art performance on three tasks with a unified single model, which provides valuable strategies and insights for future research on generalist OCR models. Code will be publicly available.
PECANN: Parallel Efficient Clustering with Graph-Based Approximate Nearest Neighbor Search
Dec 13, 2023
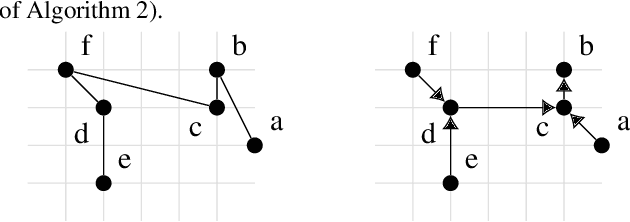
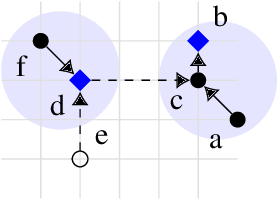
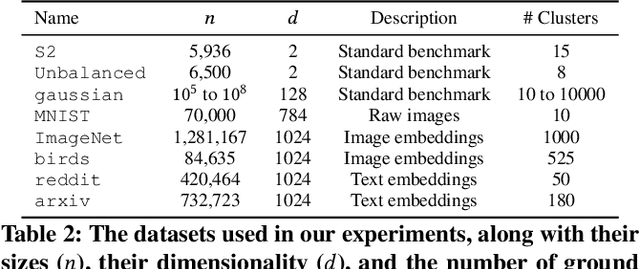
This paper studies density-based clustering of point sets. These methods use dense regions of points to detect clusters of arbitrary shapes. In particular, we study variants of density peaks clustering, a popular type of algorithm that has been shown to work well in practice. Our goal is to cluster large high-dimensional datasets, which are prevalent in practice. Prior solutions are either sequential, and cannot scale to large data, or are specialized for low-dimensional data. This paper unifies the different variants of density peaks clustering into a single framework, PECANN, by abstracting out several key steps common to this class of algorithms. One such key step is to find nearest neighbors that satisfy a predicate function, and one of the main contributions of this paper is an efficient way to do this predicate search using graph-based approximate nearest neighbor search (ANNS). To provide ample parallelism, we propose a doubling search technique that enables points to find an approximate nearest neighbor satisfying the predicate in a small number of rounds. Our technique can be applied to many existing graph-based ANNS algorithms, which can all be plugged into PECANN. We implement five clustering algorithms with PECANN and evaluate them on synthetic and real-world datasets with up to 1.28 million points and up to 1024 dimensions on a 30-core machine with two-way hyper-threading. Compared to the state-of-the-art FASTDP algorithm for high-dimensional density peaks clustering, which is sequential, our best algorithm is 45x-734x faster while achieving competitive ARI scores. Compared to the state-of-the-art parallel DPC-based algorithm, which is optimized for low dimensions, we show that PECANN is two orders of magnitude faster. As far as we know, our work is the first to evaluate DPC variants on large high-dimensional real-world image and text embedding datasets.
MultiScale Spectral-Spatial Convolutional Transformer for Hyperspectral Image Classification
Oct 28, 2023Due to the powerful ability in capturing the global information, Transformer has become an alternative architecture of CNNs for hyperspectral image classification. However, general Transformer mainly considers the global spectral information while ignores the multiscale spatial information of the hyperspectral image. In this paper, we propose a multiscale spectral-spatial convolutional Transformer (MultiscaleFormer) for hyperspectral image classification. First, the developed method utilizes multiscale spatial patches as tokens to formulate the spatial Transformer and generates multiscale spatial representation of each band in each pixel. Second, the spatial representation of all the bands in a given pixel are utilized as tokens to formulate the spectral Transformer and generate the multiscale spectral-spatial representation of each pixel. Besides, a modified spectral-spatial CAF module is constructed in the MultiFormer to fuse cross-layer spectral and spatial information. Therefore, the proposed MultiFormer can capture the multiscale spectral-spatial information and provide better performance than most of other architectures for hyperspectral image classification. Experiments are conducted over commonly used real-world datasets and the comparison results show the superiority of the proposed method.
Classification for everyone : Building geography agnostic models for fairer recognition
Dec 05, 2023In this paper, we analyze different methods to mitigate inherent geographical biases present in state of the art image classification models. We first quantitatively present this bias in two datasets - The Dollar Street Dataset and ImageNet, using images with location information. We then present different methods which can be employed to reduce this bias. Finally, we analyze the effectiveness of the different techniques on making these models more robust to geographical locations of the images.
Diffusion Posterior Sampling for Nonlinear CT Reconstruction
Dec 03, 2023Diffusion models have been demonstrated as powerful deep learning tools for image generation in CT reconstruction and restoration. Recently, diffusion posterior sampling, where a score-based diffusion prior is combined with a likelihood model, has been used to produce high quality CT images given low-quality measurements. This technique is attractive since it permits a one-time, unsupervised training of a CT prior; which can then be incorporated with an arbitrary data model. However, current methods only rely on a linear model of x-ray CT physics to reconstruct or restore images. While it is common to linearize the transmission tomography reconstruction problem, this is an approximation to the true and inherently nonlinear forward model. We propose a new method that solves the inverse problem of nonlinear CT image reconstruction via diffusion posterior sampling. We implement a traditional unconditional diffusion model by training a prior score function estimator, and apply Bayes rule to combine this prior with a measurement likelihood score function derived from the nonlinear physical model to arrive at a posterior score function that can be used to sample the reverse-time diffusion process. This plug-and-play method allows incorporation of a diffusion-based prior with generalized nonlinear CT image reconstruction into multiple CT system designs with different forward models, without the need for any additional training. We develop the algorithm that performs this reconstruction, including an ordered-subsets variant for accelerated processing and demonstrate the technique in both fully sampled low dose data and sparse-view geometries using a single unsupervised training of the prior.
3DMiner: Discovering Shapes from Large-Scale Unannotated Image Datasets
Oct 29, 2023We present 3DMiner -- a pipeline for mining 3D shapes from challenging large-scale unannotated image datasets. Unlike other unsupervised 3D reconstruction methods, we assume that, within a large-enough dataset, there must exist images of objects with similar shapes but varying backgrounds, textures, and viewpoints. Our approach leverages the recent advances in learning self-supervised image representations to cluster images with geometrically similar shapes and find common image correspondences between them. We then exploit these correspondences to obtain rough camera estimates as initialization for bundle-adjustment. Finally, for every image cluster, we apply a progressive bundle-adjusting reconstruction method to learn a neural occupancy field representing the underlying shape. We show that this procedure is robust to several types of errors introduced in previous steps (e.g., wrong camera poses, images containing dissimilar shapes, etc.), allowing us to obtain shape and pose annotations for images in-the-wild. When using images from Pix3D chairs, our method is capable of producing significantly better results than state-of-the-art unsupervised 3D reconstruction techniques, both quantitatively and qualitatively. Furthermore, we show how 3DMiner can be applied to in-the-wild data by reconstructing shapes present in images from the LAION-5B dataset. Project Page: https://ttchengab.github.io/3dminerOfficial
GraphDreamer: Compositional 3D Scene Synthesis from Scene Graphs
Nov 30, 2023As pretrained text-to-image diffusion models become increasingly powerful, recent efforts have been made to distill knowledge from these text-to-image pretrained models for optimizing a text-guided 3D model. Most of the existing methods generate a holistic 3D model from a plain text input. This can be problematic when the text describes a complex scene with multiple objects, because the vectorized text embeddings are inherently unable to capture a complex description with multiple entities and relationships. Holistic 3D modeling of the entire scene further prevents accurate grounding of text entities and concepts. To address this limitation, we propose GraphDreamer, a novel framework to generate compositional 3D scenes from scene graphs, where objects are represented as nodes and their interactions as edges. By exploiting node and edge information in scene graphs, our method makes better use of the pretrained text-to-image diffusion model and is able to fully disentangle different objects without image-level supervision. To facilitate modeling of object-wise relationships, we use signed distance fields as representation and impose a constraint to avoid inter-penetration of objects. To avoid manual scene graph creation, we design a text prompt for ChatGPT to generate scene graphs based on text inputs. We conduct both qualitative and quantitative experiments to validate the effectiveness of GraphDreamer in generating high-fidelity compositional 3D scenes with disentangled object entities.
Causal-CoG: A Causal-Effect Look at Context Generation for Boosting Multi-modal Language Models
Dec 09, 2023While Multi-modal Language Models (MLMs) demonstrate impressive multimodal ability, they still struggle on providing factual and precise responses for tasks like visual question answering (VQA). In this paper, we address this challenge from the perspective of contextual information. We propose Causal Context Generation, Causal-CoG, which is a prompting strategy that engages contextual information to enhance precise VQA during inference. Specifically, we prompt MLMs to generate contexts, i.e, text description of an image, and engage the generated contexts for question answering. Moreover, we investigate the advantage of contexts on VQA from a causality perspective, introducing causality filtering to select samples for which contextual information is helpful. To show the effectiveness of Causal-CoG, we run extensive experiments on 10 multimodal benchmarks and show consistent improvements, e.g., +6.30% on POPE, +13.69% on Vizwiz and +6.43% on VQAv2 compared to direct decoding, surpassing existing methods. We hope Casual-CoG inspires explorations of context knowledge in multimodal models, and serves as a plug-and-play strategy for MLM decoding.
One-step Diffusion with Distribution Matching Distillation
Nov 30, 2023Diffusion models generate high-quality images but require dozens of forward passes. We introduce Distribution Matching Distillation (DMD), a procedure to transform a diffusion model into a one-step image generator with minimal impact on image quality. We enforce the one-step image generator match the diffusion model at distribution level, by minimizing an approximate KL divergence whose gradient can be expressed as the difference between 2 score functions, one of the target distribution and the other of the synthetic distribution being produced by our one-step generator. The score functions are parameterized as two diffusion models trained separately on each distribution. Combined with a simple regression loss matching the large-scale structure of the multi-step diffusion outputs, our method outperforms all published few-step diffusion approaches, reaching 2.62 FID on ImageNet 64x64 and 11.49 FID on zero-shot COCO-30k, comparable to Stable Diffusion but orders of magnitude faster. Utilizing FP16 inference, our model can generate images at 20 FPS on modern hardware.