 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
LLaVA-Interactive: An All-in-One Demo for Image Chat, Segmentation, Generation and Editing
Nov 01, 2023
LLaVA-Interactive is a research prototype for multimodal human-AI interaction. The system can have multi-turn dialogues with human users by taking multimodal user inputs and generating multimodal responses. Importantly, LLaVA-Interactive goes beyond language prompt, where visual prompt is enabled to align human intents in the interaction. The development of LLaVA-Interactive is extremely cost-efficient as the system combines three multimodal skills of pre-built AI models without additional model training: visual chat of LLaVA, image segmentation from SEEM, as well as image generation and editing from GLIGEN. A diverse set of application scenarios is presented to demonstrate the promises of LLaVA-Interactive and to inspire future research in multimodal interactive systems.
GDN: A Stacking Network Used for Skin Cancer Diagnosis
Dec 05, 2023Skin cancer, the primary type of cancer that can be identified by visual recognition, requires an automatic identification system that can accurately classify different types of lesions. This paper presents GoogLe-Dense Network (GDN), which is an image-classification model to identify two types of skin cancer, Basal Cell Carcinoma, and Melanoma. GDN uses stacking of different networks to enhance the model performance. Specifically, GDN consists of two sequential levels in its structure. The first level performs basic classification tasks accomplished by GoogLeNet and DenseNet, which are trained in parallel to enhance efficiency. To avoid low accuracy and long training time, the second level takes the output of the GoogLeNet and DenseNet as the input for a logistic regression model. We compare our method with four baseline networks including ResNet, VGGNet, DenseNet, and GoogLeNet on the dataset, in which GoogLeNet and DenseNet significantly outperform ResNet and VGGNet. In the second level, different stacking methods such as perceptron, logistic regression, SVM, decision trees and K-neighbor are studied in which Logistic Regression shows the best prediction result among all. The results prove that GDN, compared to a single network structure, has higher accuracy in optimizing skin cancer detection.
Projection Regret: Reducing Background Bias for Novelty Detection via Diffusion Models
Dec 05, 2023Novelty detection is a fundamental task of machine learning which aims to detect abnormal ($\textit{i.e.}$ out-of-distribution (OOD)) samples. Since diffusion models have recently emerged as the de facto standard generative framework with surprising generation results, novelty detection via diffusion models has also gained much attention. Recent methods have mainly utilized the reconstruction property of in-distribution samples. However, they often suffer from detecting OOD samples that share similar background information to the in-distribution data. Based on our observation that diffusion models can \emph{project} any sample to an in-distribution sample with similar background information, we propose \emph{Projection Regret (PR)}, an efficient novelty detection method that mitigates the bias of non-semantic information. To be specific, PR computes the perceptual distance between the test image and its diffusion-based projection to detect abnormality. Since the perceptual distance often fails to capture semantic changes when the background information is dominant, we cancel out the background bias by comparing it against recursive projections. Extensive experiments demonstrate that PR outperforms the prior art of generative-model-based novelty detection methods by a significant margin.
Graph Information Bottleneck for Remote Sensing Segmentation
Dec 05, 2023Remote sensing segmentation has a wide range of applications in environmental protection, and urban change detection, etc. Despite the success of deep learning-based remote sensing segmentation methods (e.g., CNN and Transformer), they are not flexible enough to model irregular objects. In addition, existing graph contrastive learning methods usually adopt the way of maximizing mutual information to keep the node representations consistent between different graph views, which may cause the model to learn task-independent redundant information. To tackle the above problems, this paper treats images as graph structures and introduces a simple contrastive vision GNN (SC-ViG) architecture for remote sensing segmentation. Specifically, we construct a node-masked and edge-masked graph view to obtain an optimal graph structure representation, which can adaptively learn whether to mask nodes and edges. Furthermore, this paper innovatively introduces information bottleneck theory into graph contrastive learning to maximize task-related information while minimizing task-independent redundant information. Finally, we replace the convolutional module in UNet with the SC-ViG module to complete the segmentation and classification tasks of remote sensing images. Extensive experiments on publicly available real datasets demonstrate that our method outperforms state-of-the-art remote sensing image segmentation methods.
Evaluating the point cloud of individual trees generated from images based on Neural Radiance fields (NeRF) method
Dec 06, 2023Three-dimensional (3D) reconstruction of trees has always been a key task in precision forestry management and research. Due to the complex branch morphological structure of trees themselves and the occlusions from tree stems, branches and foliage, it is difficult to recreate a complete three-dimensional tree model from a two-dimensional image by conventional photogrammetric methods. In this study, based on tree images collected by various cameras in different ways, the Neural Radiance Fields (NeRF) method was used for individual tree reconstruction and the exported point cloud models are compared with point cloud derived from photogrammetric reconstruction and laser scanning methods. The results show that the NeRF method performs well in individual tree 3D reconstruction, as it has higher successful reconstruction rate, better reconstruction in the canopy area, it requires less amount of images as input. Compared with photogrammetric reconstruction method, NeRF has significant advantages in reconstruction efficiency and is adaptable to complex scenes, but the generated point cloud tends to be noisy and low resolution. The accuracy of tree structural parameters (tree height and diameter at breast height) extracted from the photogrammetric point cloud is still higher than those of derived from the NeRF point cloud. The results of this study illustrate the great potential of NeRF method for individual tree reconstruction, and it provides new ideas and research directions for 3D reconstruction and visualization of complex forest scenes.
Personalized Face Inpainting with Diffusion Models by Parallel Visual Attention
Dec 06, 2023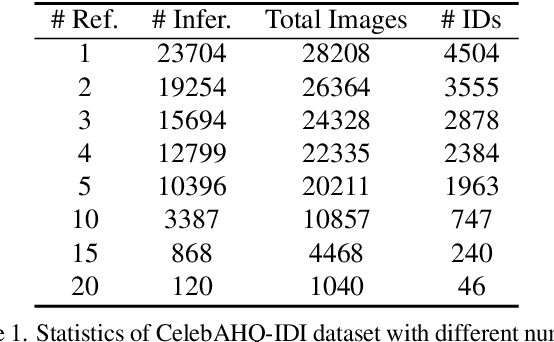
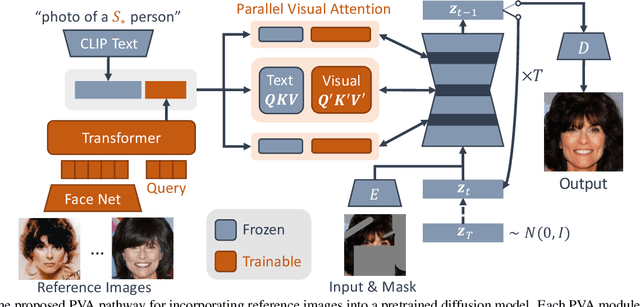


Face inpainting is important in various applications, such as photo restoration, image editing, and virtual reality. Despite the significant advances in face generative models, ensuring that a person's unique facial identity is maintained during the inpainting process is still an elusive goal. Current state-of-the-art techniques, exemplified by MyStyle, necessitate resource-intensive fine-tuning and a substantial number of images for each new identity. Furthermore, existing methods often fall short in accommodating user-specified semantic attributes, such as beard or expression. To improve inpainting results, and reduce the computational complexity during inference, this paper proposes the use of Parallel Visual Attention (PVA) in conjunction with diffusion models. Specifically, we insert parallel attention matrices to each cross-attention module in the denoising network, which attends to features extracted from reference images by an identity encoder. We train the added attention modules and identity encoder on CelebAHQ-IDI, a dataset proposed for identity-preserving face inpainting. Experiments demonstrate that PVA attains unparalleled identity resemblance in both face inpainting and face inpainting with language guidance tasks, in comparison to various benchmarks, including MyStyle, Paint by Example, and Custom Diffusion. Our findings reveal that PVA ensures good identity preservation while offering effective language-controllability. Additionally, in contrast to Custom Diffusion, PVA requires just 40 fine-tuning steps for each new identity, which translates to a significant speed increase of over 20 times.
InstructPix2NeRF: Instructed 3D Portrait Editing from a Single Image
Nov 06, 2023With the success of Neural Radiance Field (NeRF) in 3D-aware portrait editing, a variety of works have achieved promising results regarding both quality and 3D consistency. However, these methods heavily rely on per-prompt optimization when handling natural language as editing instructions. Due to the lack of labeled human face 3D datasets and effective architectures, the area of human-instructed 3D-aware editing for open-world portraits in an end-to-end manner remains under-explored. To solve this problem, we propose an end-to-end diffusion-based framework termed InstructPix2NeRF, which enables instructed 3D-aware portrait editing from a single open-world image with human instructions. At its core lies a conditional latent 3D diffusion process that lifts 2D editing to 3D space by learning the correlation between the paired images' difference and the instructions via triplet data. With the help of our proposed token position randomization strategy, we could even achieve multi-semantic editing through one single pass with the portrait identity well-preserved. Besides, we further propose an identity consistency module that directly modulates the extracted identity signals into our diffusion process, which increases the multi-view 3D identity consistency. Extensive experiments verify the effectiveness of our method and show its superiority against strong baselines quantitatively and qualitatively.
Complex Image Generation SwinTransformer Network for Audio Denoising
Oct 24, 2023Achieving high-performance audio denoising is still a challenging task in real-world applications. Existing time-frequency methods often ignore the quality of generated frequency domain images. This paper converts the audio denoising problem into an image generation task. We first develop a complex image generation SwinTransformer network to capture more information from the complex Fourier domain. We then impose structure similarity and detailed loss functions to generate high-quality images and develop an SDR loss to minimize the difference between denoised and clean audios. Extensive experiments on two benchmark datasets demonstrate that our proposed model is better than state-of-the-art methods.
PUMA: Fully Decentralized Uncertainty-aware Multiagent Trajectory Planner with Real-time Image Segmentation-based Frame Alignment
Nov 07, 2023Fully decentralized, multiagent trajectory planners enable complex tasks like search and rescue or package delivery by ensuring safe navigation in unknown environments. However, deconflicting trajectories with other agents and ensuring collision-free paths in a fully decentralized setting is complicated by dynamic elements and localization uncertainty. To this end, this paper presents (1) an uncertainty-aware multiagent trajectory planner and (2) an image segmentation-based frame alignment pipeline. The uncertainty-aware planner propagates uncertainty associated with the future motion of detected obstacles, and by incorporating this propagated uncertainty into optimization constraints, the planner effectively navigates around obstacles. Unlike conventional methods that emphasize explicit obstacle tracking, our approach integrates implicit tracking. Sharing trajectories between agents can cause potential collisions due to frame misalignment. Addressing this, we introduce a novel frame alignment pipeline that rectifies inter-agent frame misalignment. This method leverages a zero-shot image segmentation model for detecting objects in the environment and a data association framework based on geometric consistency for map alignment. Our approach accurately aligns frames with only 0.18 m and 2.7 deg of mean frame alignment error in our most challenging simulation scenario. In addition, we conducted hardware experiments and successfully achieved 0.29 m and 2.59 deg of frame alignment error. Together with the alignment framework, our planner ensures safe navigation in unknown environments and collision avoidance in decentralized settings.
Word for Person: Zero-shot Composed Person Retrieval
Nov 25, 2023Searching for specific person has great security value and social benefits, and it often involves a combination of visual and textual information. Conventional person retrieval methods, whether image-based or text-based, usually fall short in effectively harnessing both types of information, leading to the loss of accuracy. In this paper, a whole new task called Composed Person Retrieval (CPR) is proposed to jointly utilize both image and text information for target person retrieval. However, the supervised CPR must depend on very costly manual annotation dataset, while there are currently no available resources. To mitigate this issue, we firstly introduce the Zero-shot Composed Person Retrieval (ZS-CPR), which leverages existing domain-related data to resolve the CPR problem without reliance on expensive annotations. Secondly, to learn ZS-CPR model, we propose a two-stage learning framework, Word4Per, where a lightweight Textual Inversion Network (TINet) and a text-based person retrieval model based on fine-tuned Contrastive Language-Image Pre-training (CLIP) network are learned without utilizing any CPR data. Thirdly, a finely annotated Image-Text Composed Person Retrieval dataset (ITCPR) is built as the benchmark to assess the performance of the proposed Word4Per framework. Extensive experiments under both Rank-1 and mAP demonstrate the effectiveness of Word4Per for the ZS-CPR task, surpassing the comparative methods by over 10%. The code and ITCPR dataset will be publicly available at https://github.com/Delong-liu-bupt/Word4Per.