 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
AVID: Any-Length Video Inpainting with Diffusion Model
Dec 06, 2023
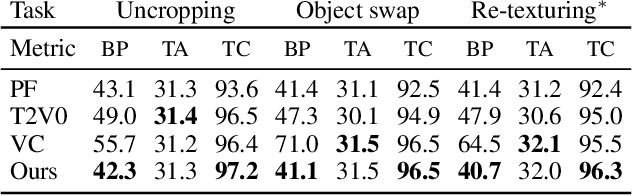
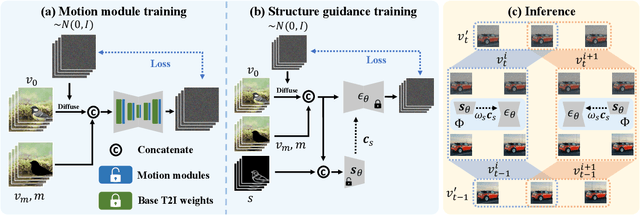
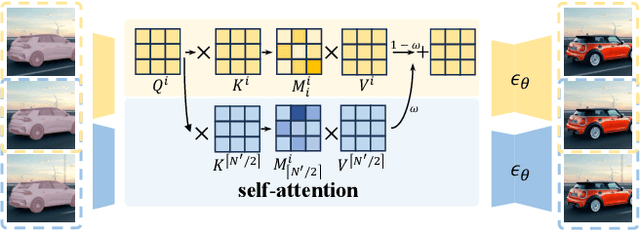

Recent advances in diffusion models have successfully enabled text-guided image inpainting. While it seems straightforward to extend such editing capability into video domain, there has been fewer works regarding text-guided video inpainting. Given a video, a masked region at its initial frame, and an editing prompt, it requires a model to do infilling at each frame following the editing guidance while keeping the out-of-mask region intact. There are three main challenges in text-guided video inpainting: ($i$) temporal consistency of the edited video, ($ii$) supporting different inpainting types at different structural fidelity level, and ($iii$) dealing with variable video length. To address these challenges, we introduce Any-Length Video Inpainting with Diffusion Model, dubbed as AVID. At its core, our model is equipped with effective motion modules and adjustable structure guidance, for fixed-length video inpainting. Building on top of that, we propose a novel Temporal MultiDiffusion sampling pipeline with an middle-frame attention guidance mechanism, facilitating the generation of videos with any desired duration. Our comprehensive experiments show our model can robustly deal with various inpainting types at different video duration range, with high quality. More visualization results is made publicly available at https://zhang-zx.github.io/AVID/ .
Multimodal Group Emotion Recognition In-the-wild Using Privacy-Compliant Features
Dec 06, 2023This paper explores privacy-compliant group-level emotion recognition ''in-the-wild'' within the EmotiW Challenge 2023. Group-level emotion recognition can be useful in many fields including social robotics, conversational agents, e-coaching and learning analytics. This research imposes itself using only global features avoiding individual ones, i.e. all features that can be used to identify or track people in videos (facial landmarks, body poses, audio diarization, etc.). The proposed multimodal model is composed of a video and an audio branches with a cross-attention between modalities. The video branch is based on a fine-tuned ViT architecture. The audio branch extracts Mel-spectrograms and feed them through CNN blocks into a transformer encoder. Our training paradigm includes a generated synthetic dataset to increase the sensitivity of our model on facial expression within the image in a data-driven way. The extensive experiments show the significance of our methodology. Our privacy-compliant proposal performs fairly on the EmotiW challenge, with 79.24% and 75.13% of accuracy respectively on validation and test set for the best models. Noticeably, our findings highlight that it is possible to reach this accuracy level with privacy-compliant features using only 5 frames uniformly distributed on the video.
Golden Gemini is All You Need: Finding the Sweet Spots for Speaker Verification
Dec 06, 2023Previous studies demonstrate the impressive performance of residual neural networks (ResNet) in speaker verification. The ResNet models treat the time and frequency dimensions equally. They follow the default stride configuration designed for image recognition, where the horizontal and vertical axes exhibit similarities. This approach ignores the fact that time and frequency are asymmetric in speech representation. In this paper, we address this issue and look for optimal stride configurations specifically tailored for speaker verification. We represent the stride space on a trellis diagram, and conduct a systematic study on the impact of temporal and frequency resolutions on the performance and further identify two optimal points, namely Golden Gemini, which serves as a guiding principle for designing 2D ResNet-based speaker verification models. By following the principle, a state-of-the-art ResNet baseline model gains a significant performance improvement on VoxCeleb, SITW, and CNCeleb datasets with 7.70%/11.76% average EER/minDCF reductions, respectively, across different network depths (ResNet18, 34, 50, and 101), while reducing the number of parameters by 16.5% and FLOPs by 4.1%. We refer to it as Gemini ResNet. Further investigation reveals the efficacy of the proposed Golden Gemini operating points across various training conditions and architectures. Furthermore, we present a new benchmark, namely the Gemini DF-ResNet, using a cutting-edge model.
Towards Real-World Focus Stacking with Deep Learning
Nov 29, 2023Focus stacking is widely used in micro, macro, and landscape photography to reconstruct all-in-focus images from multiple frames obtained with focus bracketing, that is, with shallow depth of field and different focus planes. Existing deep learning approaches to the underlying multi-focus image fusion problem have limited applicability to real-world imagery since they are designed for very short image sequences (two to four images), and are typically trained on small, low-resolution datasets either acquired by light-field cameras or generated synthetically. We introduce a new dataset consisting of 94 high-resolution bursts of raw images with focus bracketing, with pseudo ground truth computed from the data using state-of-the-art commercial software. This dataset is used to train the first deep learning algorithm for focus stacking capable of handling bursts of sufficient length for real-world applications. Qualitative experiments demonstrate that it is on par with existing commercial solutions in the long-burst, realistic regime while being significantly more tolerant to noise. The code and dataset are available at https://github.com/araujoalexandre/FocusStackingDataset.
LiveNVS: Neural View Synthesis on Live RGB-D Streams
Nov 29, 2023Existing real-time RGB-D reconstruction approaches, like Kinect Fusion, lack real-time photo-realistic visualization. This is due to noisy, oversmoothed or incomplete geometry and blurry textures which are fused from imperfect depth maps and camera poses. Recent neural rendering methods can overcome many of such artifacts but are mostly optimized for offline usage, hindering the integration into a live reconstruction pipeline. In this paper, we present LiveNVS, a system that allows for neural novel view synthesis on a live RGB-D input stream with very low latency and real-time rendering. Based on the RGB-D input stream, novel views are rendered by projecting neural features into the target view via a densely fused depth map and aggregating the features in image-space to a target feature map. A generalizable neural network then translates the target feature map into a high-quality RGB image. LiveNVS achieves state-of-the-art neural rendering quality of unknown scenes during capturing, allowing users to virtually explore the scene and assess reconstruction quality in real-time.
ChatIllusion: Efficient-Aligning Interleaved Generation ability with Visual Instruction Model
Nov 29, 2023As the capabilities of Large-Language Models (LLMs) become widely recognized, there is an increasing demand for human-machine chat applications. Human interaction with text often inherently invokes mental imagery, an aspect that existing LLM-based chatbots like GPT-4 do not currently emulate, as they are confined to generating text-only content. To bridge this gap, we introduce ChatIllusion, an advanced Generative multimodal large language model (MLLM) that combines the capabilities of LLM with not only visual comprehension but also creativity. Specifically, ChatIllusion integrates Stable Diffusion XL and Llama, which have been fine-tuned on modest image-caption data, to facilitate multiple rounds of illustrated chats. The central component of ChatIllusion is the "GenAdapter," an efficient approach that equips the multimodal language model with capabilities for visual representation, without necessitating modifications to the foundational model. Extensive experiments validate the efficacy of our approach, showcasing its ability to produce diverse and superior-quality image outputs Simultaneously, it preserves semantic consistency and control over the dialogue, significantly enhancing the overall user's quality of experience (QoE). The code is available at https://github.com/litwellchi/ChatIllusion.
Language-conditioned Detection Transformer
Nov 29, 2023We present a new open-vocabulary detection framework. Our framework uses both image-level labels and detailed detection annotations when available. Our framework proceeds in three steps. We first train a language-conditioned object detector on fully-supervised detection data. This detector gets to see the presence or absence of ground truth classes during training, and conditions prediction on the set of present classes. We use this detector to pseudo-label images with image-level labels. Our detector provides much more accurate pseudo-labels than prior approaches with its conditioning mechanism. Finally, we train an unconditioned open-vocabulary detector on the pseudo-annotated images. The resulting detector, named DECOLA, shows strong zero-shot performance in open-vocabulary LVIS benchmark as well as direct zero-shot transfer benchmarks on LVIS, COCO, Object365, and OpenImages. DECOLA outperforms the prior arts by 17.1 AP-rare and 9.4 mAP on zero-shot LVIS benchmark. DECOLA achieves state-of-the-art results in various model sizes, architectures, and datasets by only training on open-sourced data and academic-scale computing. Code is available at https://github.com/janghyuncho/DECOLA.
SODA: Bottleneck Diffusion Models for Representation Learning
Nov 29, 2023We introduce SODA, a self-supervised diffusion model, designed for representation learning. The model incorporates an image encoder, which distills a source view into a compact representation, that, in turn, guides the generation of related novel views. We show that by imposing a tight bottleneck between the encoder and a denoising decoder, and leveraging novel view synthesis as a self-supervised objective, we can turn diffusion models into strong representation learners, capable of capturing visual semantics in an unsupervised manner. To the best of our knowledge, SODA is the first diffusion model to succeed at ImageNet linear-probe classification, and, at the same time, it accomplishes reconstruction, editing and synthesis tasks across a wide range of datasets. Further investigation reveals the disentangled nature of its emergent latent space, that serves as an effective interface to control and manipulate the model's produced images. All in all, we aim to shed light on the exciting and promising potential of diffusion models, not only for image generation, but also for learning rich and robust representations.
Target to Source: Guidance-Based Diffusion Model for Test-Time Adaptation
Dec 08, 2023Most recent works of test-time adaptation (TTA) aim to alleviate domain shift problems by re-training source classifiers in each domain. On the other hand, the emergence of the diffusion model provides another solution to TTA, which directly maps the test data from the target domain to the source domain based on a diffusion model pre-trained in the source domain. The source classifier does not need to be fine-tuned. However, 1) the semantic information loss from test data to the source domain and 2) the model shift between the source classifier and diffusion model would prevent the diffusion model from mapping the test data back to the source domain correctly. In this paper, we propose a novel guidance-based diffusion-driven adaptation (GDDA) to overcome the data shift and let the diffusion model find a better way to go back to the source. Concretely, we first propose detail and global guidance to better keep the common semantics of the test and source data. The two guidance include a contrastive loss and mean squared error to alleviate the information loss by fully exploring the diffusion model and the test data. Meanwhile, we propose a classifier-aware guidance to reduce the bias caused by the model shift, which can incorporate the source classifier's information into the generation process of the diffusion model. Extensive experiments on three image datasets with three classifier backbones demonstrate that GDDA significantly performs better than the state-of-the-art baselines. On CIFAR-10C, CIFAR-100C, and ImageNetC, GDDA achieves 11.54\%, 19.05\%, and 11.63\% average accuracy improvements, respectively. GDDA even achieves equal performance compared with methods of re-training classifiers. The code is available in the supplementary material.
Exploring Deep Learning Image Super-Resolution for Iris Recognition
Nov 02, 2023In this work we test the ability of deep learning methods to provide an end-to-end mapping between low and high resolution images applying it to the iris recognition problem. Here, we propose the use of two deep learning single-image super-resolution approaches: Stacked Auto-Encoders (SAE) and Convolutional Neural Networks (CNN) with the most possible lightweight structure to achieve fast speed, preserve local information and reduce artifacts at the same time. We validate the methods with a database of 1.872 near-infrared iris images with quality assessment and recognition experiments showing the superiority of deep learning approaches over the compared algorithms.