 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Invariant Representation Learning via Decoupling Style and Spurious Features
Dec 11, 2023
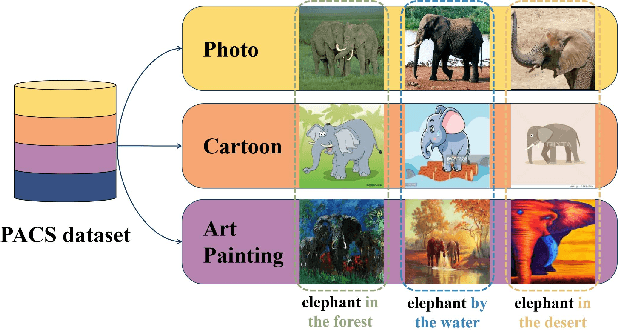
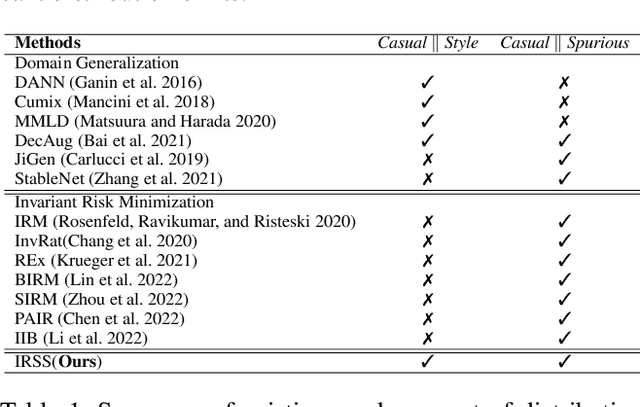
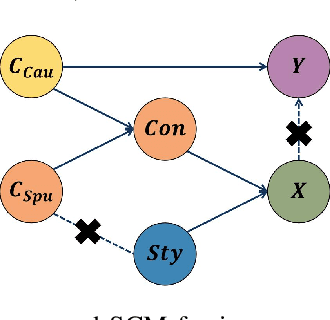
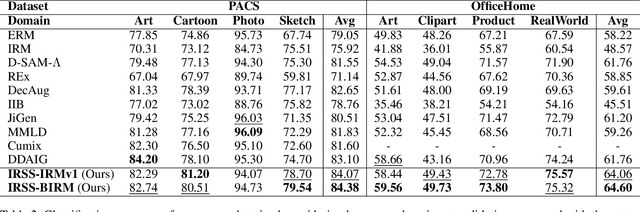
This paper considers the out-of-distribution (OOD) generalization problem under the setting that both style distribution shift and spurious features exist and domain labels are missing. This setting frequently arises in real-world applications and is underlooked because previous approaches mainly handle either of these two factors. The critical challenge is decoupling style and spurious features in the absence of domain labels. To address this challenge, we first propose a structural causal model (SCM) for the image generation process, which captures both style distribution shift and spurious features. The proposed SCM enables us to design a new framework called IRSS, which can gradually separate style distribution and spurious features from images by introducing adversarial neural networks and multi-environment optimization, thus achieving OOD generalization. Moreover, it does not require additional supervision (e.g., domain labels) other than the images and their corresponding labels. Experiments on benchmark datasets demonstrate that IRSS outperforms traditional OOD methods and solves the problem of Invariant risk minimization (IRM) degradation, enabling the extraction of invariant features under distribution shift.
EpiDiff: Enhancing Multi-View Synthesis via Localized Epipolar-Constrained Diffusion
Dec 11, 2023Generating multiview images from a single view facilitates the rapid generation of a 3D mesh conditioned on a single image. Recent methods that introduce 3D global representation into diffusion models have shown the potential to generate consistent multiviews, but they have reduced generation speed and face challenges in maintaining generalizability and quality. To address this issue, we propose EpiDiff, a localized interactive multiview diffusion model. At the core of the proposed approach is to insert a lightweight epipolar attention block into the frozen diffusion model, leveraging epipolar constraints to enable cross-view interaction among feature maps of neighboring views. The newly initialized 3D modeling module preserves the original feature distribution of the diffusion model, exhibiting compatibility with a variety of base diffusion models. Experiments show that EpiDiff generates 16 multiview images in just 12 seconds, and it surpasses previous methods in quality evaluation metrics, including PSNR, SSIM and LPIPS. Additionally, EpiDiff can generate a more diverse distribution of views, improving the reconstruction quality from generated multiviews. Please see our project page at https://huanngzh.github.io/EpiDiff/.
Revolutionizing Healthcare Image Analysis in Pandemic-Based Fog-Cloud Computing Architectures
Nov 02, 2023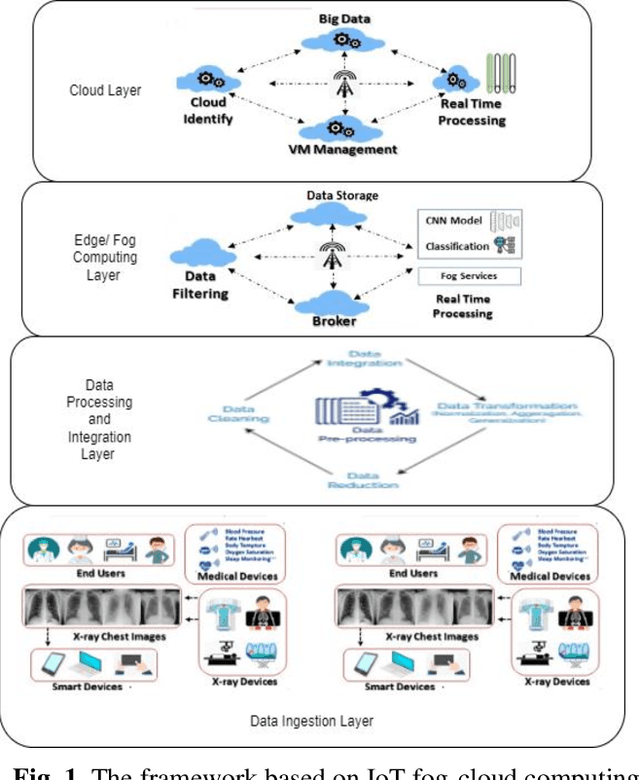

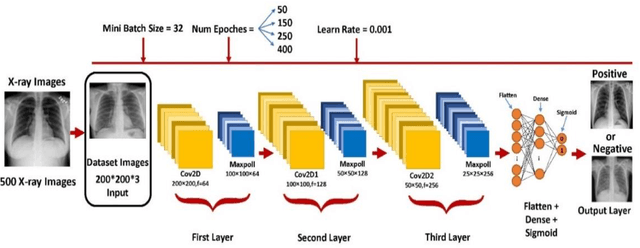
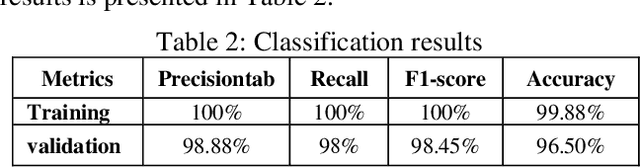
The emergence of pandemics has significantly emphasized the need for effective solutions in healthcare data analysis. One particular challenge in this domain is the manual examination of medical images, such as X-rays and CT scans. This process is time-consuming and involves the logistical complexities of transferring these images to centralized cloud computing servers. Additionally, the speed and accuracy of image analysis are vital for efficient healthcare image management. This research paper introduces an innovative healthcare architecture that tackles the challenges of analysis efficiency and accuracy by harnessing the capabilities of Artificial Intelligence (AI). Specifically, the proposed architecture utilizes fog computing and presents a modified Convolutional Neural Network (CNN) designed specifically for image analysis. Different architectures of CNN layers are thoroughly explored and evaluated to optimize overall performance. To demonstrate the effectiveness of the proposed approach, a dataset of X-ray images is utilized for analysis and evaluation. Comparative assessments are conducted against recent models such as VGG16, VGG19, MobileNet, and related research papers. Notably, the proposed approach achieves an exceptional accuracy rate of 99.88% in classifying normal cases, accompanied by a validation rate of 96.5%, precision and recall rates of 100%, and an F1 score of 100%. These results highlight the immense potential of fog computing and modified CNNs in revolutionizing healthcare image analysis and diagnosis, not only during pandemics but also in the future. By leveraging these technologies, healthcare professionals can enhance the efficiency and accuracy of medical image analysis, leading to improved patient care and outcomes.
StyleCrafter: Enhancing Stylized Text-to-Video Generation with Style Adapter
Dec 01, 2023Text-to-video (T2V) models have shown remarkable capabilities in generating diverse videos. However, they struggle to produce user-desired stylized videos due to (i) text's inherent clumsiness in expressing specific styles and (ii) the generally degraded style fidelity. To address these challenges, we introduce StyleCrafter, a generic method that enhances pre-trained T2V models with a style control adapter, enabling video generation in any style by providing a reference image. Considering the scarcity of stylized video datasets, we propose to first train a style control adapter using style-rich image datasets, then transfer the learned stylization ability to video generation through a tailor-made finetuning paradigm. To promote content-style disentanglement, we remove style descriptions from the text prompt and extract style information solely from the reference image using a decoupling learning strategy. Additionally, we design a scale-adaptive fusion module to balance the influences of text-based content features and image-based style features, which helps generalization across various text and style combinations. StyleCrafter efficiently generates high-quality stylized videos that align with the content of the texts and resemble the style of the reference images. Experiments demonstrate that our approach is more flexible and efficient than existing competitors.
BESTMVQA: A Benchmark Evaluation System for Medical Visual Question Answering
Dec 13, 2023Medical Visual Question Answering (Med-VQA) is a very important task in healthcare industry, which answers a natural language question with a medical image. Existing VQA techniques in information systems can be directly applied to solving the task. However, they often suffer from (i) the data insufficient problem, which makes it difficult to train the state of the arts (SOTAs) for the domain-specific task, and (ii) the reproducibility problem, that many existing models have not been thoroughly evaluated in a unified experimental setup. To address these issues, this paper develops a Benchmark Evaluation SysTem for Medical Visual Question Answering, denoted by BESTMVQA. Given self-collected clinical data, our system provides a useful tool for users to automatically build Med-VQA datasets, which helps overcoming the data insufficient problem. Users also can conveniently select a wide spectrum of SOTA models from our model library to perform a comprehensive empirical study. With simple configurations, our system automatically trains and evaluates the selected models over a benchmark dataset, and reports the comprehensive results for users to develop new techniques or perform medical practice. Limitations of existing work are overcome (i) by the data generation tool, which automatically constructs new datasets from unstructured clinical data, and (ii) by evaluating SOTAs on benchmark datasets in a unified experimental setup. The demonstration video of our system can be found at https://youtu.be/QkEeFlu1x4A. Our code and data will be available soon.
Radio Signal Classification by Adversarially Robust Quantum Machine Learning
Dec 13, 2023Radio signal classification plays a pivotal role in identifying the modulation scheme used in received radio signals, which is essential for demodulation and proper interpretation of the transmitted information. Researchers have underscored the high susceptibility of ML algorithms for radio signal classification to adversarial attacks. Such vulnerability could result in severe consequences, including misinterpretation of critical messages, interception of classified information, or disruption of communication channels. Recent advancements in quantum computing have revolutionized theories and implementations of computation, bringing the unprecedented development of Quantum Machine Learning (QML). It is shown that quantum variational classifiers (QVCs) provide notably enhanced robustness against classical adversarial attacks in image classification. However, no research has yet explored whether QML can similarly mitigate adversarial threats in the context of radio signal classification. This work applies QVCs to radio signal classification and studies their robustness to various adversarial attacks. We also propose the novel application of the approximate amplitude encoding (AAE) technique to encode radio signal data efficiently. Our extensive simulation results present that attacks generated on QVCs transfer well to CNN models, indicating that these adversarial examples can fool neural networks that they are not explicitly designed to attack. However, the converse is not true. QVCs primarily resist the attacks generated on CNNs. Overall, with comprehensive simulations, our results shed new light on the growing field of QML by bridging knowledge gaps in QAML in radio signal classification and uncovering the advantages of applying QML methods in practical applications.
Adversarial Diffusion Distillation
Nov 28, 2023We introduce Adversarial Diffusion Distillation (ADD), a novel training approach that efficiently samples large-scale foundational image diffusion models in just 1-4 steps while maintaining high image quality. We use score distillation to leverage large-scale off-the-shelf image diffusion models as a teacher signal in combination with an adversarial loss to ensure high image fidelity even in the low-step regime of one or two sampling steps. Our analyses show that our model clearly outperforms existing few-step methods (GANs, Latent Consistency Models) in a single step and reaches the performance of state-of-the-art diffusion models (SDXL) in only four steps. ADD is the first method to unlock single-step, real-time image synthesis with foundation models. Code and weights available under https://github.com/Stability-AI/generative-models and https://huggingface.co/stabilityai/ .
MLLMs-Augmented Visual-Language Representation Learning
Dec 01, 2023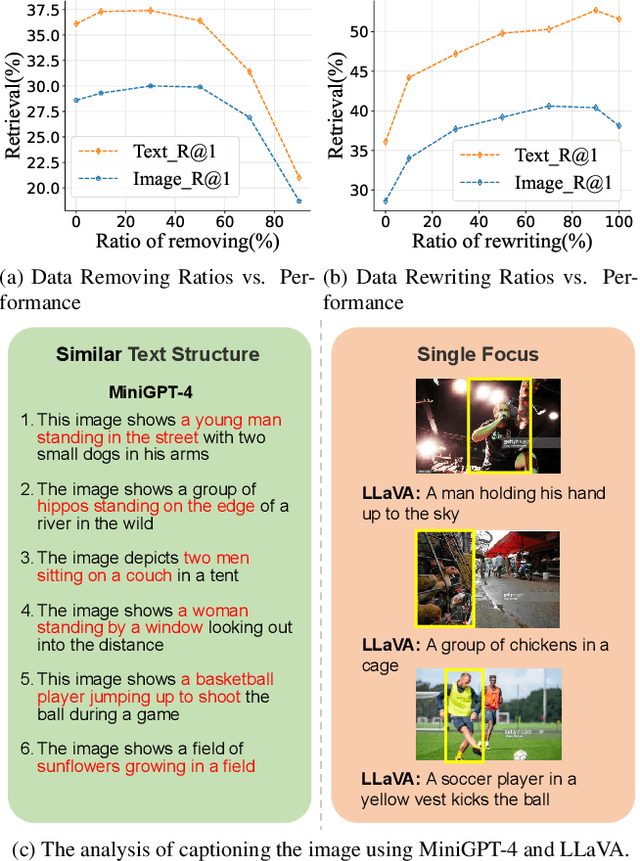
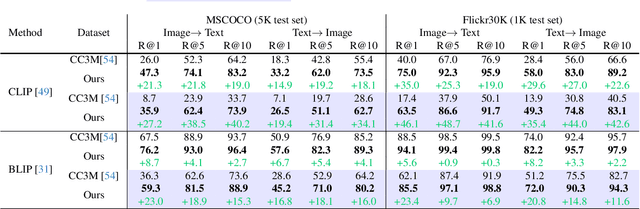
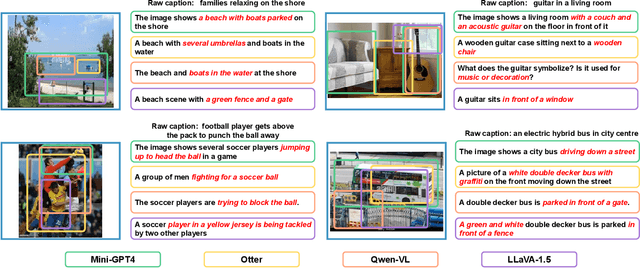
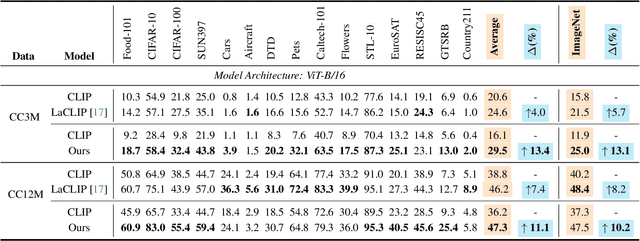
Visual-language pre-training (VLP) has achieved remarkable success in multi-modal tasks, largely attributed to the availability of large-scale image-text datasets. In this work, we demonstrate that multi-modal large language models (MLLMs) can enhance visual-language representation learning by improving data quality. Our approach is simple, utilizing MLLMs to extend multiple captions for each image. To prevent the bias introduced by MLLMs' hallucinations and intrinsic caption styles, we propose "text shearing" to maintain the same length for extended captions as that of the original captions. In image-text retrieval, our method consistently obtains 5.6 ~ 35.0% and 16.8 ~ 46.1% improvement on R@1 under the fine-tuning and zero-shot settings, respectively. Notably, we obtain zero-shot results that are comparable to fine-tuning on target datasets, which encourages more exploration of the versatile use of MLLMs.
NearbyPatchCL: Leveraging Nearby Patches for Self-Supervised Patch-Level Multi-Class Classification in Whole-Slide Images
Dec 12, 2023Whole-slide image (WSI) analysis plays a crucial role in cancer diagnosis and treatment. In addressing the demands of this critical task, self-supervised learning (SSL) methods have emerged as a valuable resource, leveraging their efficiency in circumventing the need for a large number of annotations, which can be both costly and time-consuming to deploy supervised methods. Nevertheless, patch-wise representation may exhibit instability in performance, primarily due to class imbalances stemming from patch selection within WSIs. In this paper, we introduce Nearby Patch Contrastive Learning (NearbyPatchCL), a novel self-supervised learning method that leverages nearby patches as positive samples and a decoupled contrastive loss for robust representation learning. Our method demonstrates a tangible enhancement in performance for downstream tasks involving patch-level multi-class classification. Additionally, we curate a new dataset derived from WSIs sourced from the Canine Cutaneous Cancer Histology, thus establishing a benchmark for the rigorous evaluation of patch-level multi-class classification methodologies. Intensive experiments show that our method significantly outperforms the supervised baseline and state-of-the-art SSL methods with top-1 classification accuracy of 87.56%. Our method also achieves comparable results while utilizing a mere 1% of labeled data, a stark contrast to the 100% labeled data requirement of other approaches. Source code: https://github.com/nvtien457/NearbyPatchCL
LoRA-Enhanced Distillation on Guided Diffusion Models
Dec 12, 2023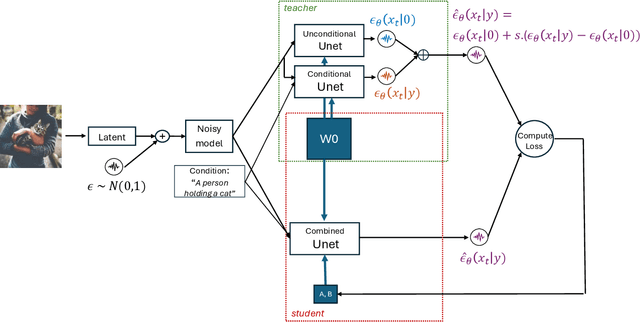


Diffusion models, such as Stable Diffusion (SD), offer the ability to generate high-resolution images with diverse features, but they come at a significant computational and memory cost. In classifier-free guided diffusion models, prolonged inference times are attributed to the necessity of computing two separate diffusion models at each denoising step. Recent work has shown promise in improving inference time through distillation techniques, teaching the model to perform similar denoising steps with reduced computations. However, the application of distillation introduces additional memory overhead to these already resource-intensive diffusion models, making it less practical. To address these challenges, our research explores a novel approach that combines Low-Rank Adaptation (LoRA) with model distillation to efficiently compress diffusion models. This approach not only reduces inference time but also mitigates memory overhead, and notably decreases memory consumption even before applying distillation. The results are remarkable, featuring a significant reduction in inference time due to the distillation process and a substantial 50% reduction in memory consumption. Our examination of the generated images underscores that the incorporation of LoRA-enhanced distillation maintains image quality and alignment with the provided prompts. In summary, while conventional distillation tends to increase memory consumption, LoRA-enhanced distillation offers optimization without any trade-offs or compromises in quality.