 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
TrackDiffusion: Multi-object Tracking Data Generation via Diffusion Models
Dec 01, 2023
Diffusion models have gained prominence in generating data for perception tasks such as image classification and object detection. However, the potential in generating high-quality tracking sequences, a crucial aspect in the field of video perception, has not been fully investigated. To address this gap, we propose TrackDiffusion, a novel architecture designed to generate continuous video sequences from the tracklets. TrackDiffusion represents a significant departure from the traditional layout-to-image (L2I) generation and copy-paste synthesis focusing on static image elements like bounding boxes by empowering image diffusion models to encompass dynamic and continuous tracking trajectories, thereby capturing complex motion nuances and ensuring instance consistency among video frames. For the first time, we demonstrate that the generated video sequences can be utilized for training multi-object tracking (MOT) systems, leading to significant improvement in tracker performance. Experimental results show that our model significantly enhances instance consistency in generated video sequences, leading to improved perceptual metrics. Our approach achieves an improvement of 8.7 in TrackAP and 11.8 in TrackAP$_{50}$ on the YTVIS dataset, underscoring its potential to redefine the standards of video data generation for MOT tasks and beyond.
Lasagna: Layered Score Distillation for Disentangled Object Relighting
Nov 30, 2023Professional artists, photographers, and other visual content creators use object relighting to establish their photo's desired effect. Unfortunately, manual tools that allow relighting have a steep learning curve and are difficult to master. Although generative editing methods now enable some forms of image editing, relighting is still beyond today's capabilities; existing methods struggle to keep other aspects of the image -- colors, shapes, and textures -- consistent after the edit. We propose Lasagna, a method that enables intuitive text-guided relighting control. Lasagna learns a lighting prior by using score distillation sampling to distill the prior of a diffusion model, which has been finetuned on synthetic relighting data. To train Lasagna, we curate a new synthetic dataset ReLiT, which contains 3D object assets re-lit from multiple light source locations. Despite training on synthetic images, quantitative results show that Lasagna relights real-world images while preserving other aspects of the input image, outperforming state-of-the-art text-guided image editing methods. Lasagna enables realistic and controlled results on natural images and digital art pieces and is preferred by humans over other methods in over 91% of cases. Finally, we demonstrate the versatility of our learning objective by extending it to allow colorization, another form of image editing.
Violet: A Vision-Language Model for Arabic Image Captioning with Gemini Decoder
Nov 15, 2023Although image captioning has a vast array of applications, it has not reached its full potential in languages other than English. Arabic, for instance, although the native language of more than 400 million people, remains largely underrepresented in this area. This is due to the lack of labeled data and powerful Arabic generative models. We alleviate this issue by presenting a novel vision-language model dedicated to Arabic, dubbed \textit{Violet}. Our model is based on a vision encoder and a Gemini text decoder that maintains generation fluency while allowing fusion between the vision and language components. To train our model, we introduce a new method for automatically acquiring data from available English datasets. We also manually prepare a new dataset for evaluation. \textit{Violet} performs sizeably better than our baselines on all of our evaluation datasets. For example, it reaches a CIDEr score of $61.2$ on our manually annotated dataset and achieves an improvement of $13$ points on Flickr8k.
Diverse Diffusion: Enhancing Image Diversity in Text-to-Image Generation
Oct 19, 2023Latent diffusion models excel at producing high-quality images from text. Yet, concerns appear about the lack of diversity in the generated imagery. To tackle this, we introduce Diverse Diffusion, a method for boosting image diversity beyond gender and ethnicity, spanning into richer realms, including color diversity.Diverse Diffusion is a general unsupervised technique that can be applied to existing text-to-image models. Our approach focuses on finding vectors in the Stable Diffusion latent space that are distant from each other. We generate multiple vectors in the latent space until we find a set of vectors that meets the desired distance requirements and the required batch size.To evaluate the effectiveness of our diversity methods, we conduct experiments examining various characteristics, including color diversity, LPIPS metric, and ethnicity/gender representation in images featuring humans.The results of our experiments emphasize the significance of diversity in generating realistic and varied images, offering valuable insights for improving text-to-image models. Through the enhancement of image diversity, our approach contributes to the creation of more inclusive and representative AI-generated art.
FDNet: Feature Decoupled Segmentation Network for Tooth CBCT Image
Nov 11, 2023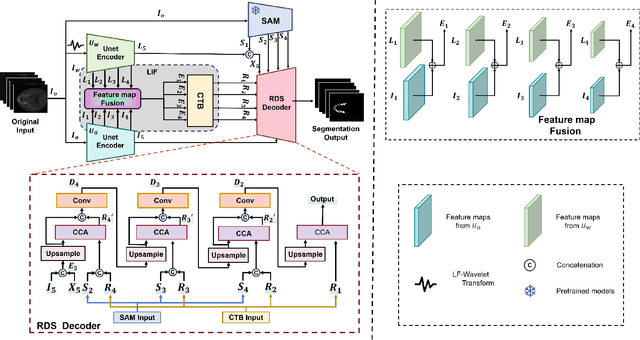
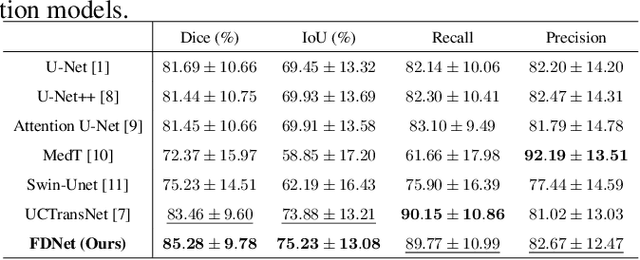
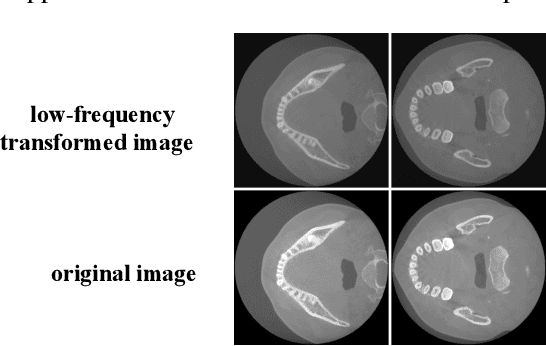
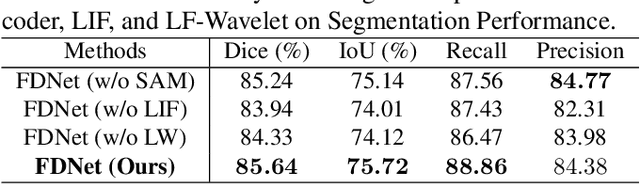
Precise Tooth Cone Beam Computed Tomography (CBCT) image segmentation is crucial for orthodontic treatment planning. In this paper, we propose FDNet, a Feature Decoupled Segmentation Network, to excel in the face of the variable dental conditions encountered in CBCT scans, such as complex artifacts and indistinct tooth boundaries. The Low-Frequency Wavelet Transform (LF-Wavelet) is employed to enrich the semantic content by emphasizing the global structural integrity of the teeth, while the SAM encoder is leveraged to refine the boundary delineation, thus improving the contrast between adjacent dental structures. By integrating these dual aspects, FDNet adeptly addresses the semantic gap, providing a detailed and accurate segmentation. The framework's effectiveness is validated through rigorous benchmarks, achieving the top Dice and IoU scores of 85.28% and 75.23%, respectively. This innovative decoupling of semantic and boundary features capitalizes on the unique strengths of each element to significantly elevate the quality of segmentation performance.
TLMCM Network for Medical Image Hierarchical Multi-Label Classification
Nov 11, 2023Medical Image Hierarchical Multi-Label Classification (MI-HMC) is of paramount importance in modern healthcare, presenting two significant challenges: data imbalance and \textit{hierarchy constraint}. Existing solutions involve complex model architecture design or domain-specific preprocessing, demanding considerable expertise or effort in implementation. To address these limitations, this paper proposes Transfer Learning with Maximum Constraint Module (TLMCM) network for the MI-HMC task. The TLMCM network offers a novel approach to overcome the aforementioned challenges, outperforming existing methods based on the Area Under the Average Precision and Recall Curve($AU\overline{(PRC)}$) metric. In addition, this research proposes two novel accuracy metrics, $EMR$ and $HammingAccuracy$, which have not been extensively explored in the context of the MI-HMC task. Experimental results demonstrate that the TLMCM network achieves high multi-label prediction accuracy($80\%$-$90\%$) for MI-HMC tasks, making it a valuable contribution to healthcare domain applications.
Self-correcting LLM-controlled Diffusion Models
Nov 27, 2023Text-to-image generation has witnessed significant progress with the advent of diffusion models. Despite the ability to generate photorealistic images, current text-to-image diffusion models still often struggle to accurately interpret and follow complex input text prompts. In contrast to existing models that aim to generate images only with their best effort, we introduce Self-correcting LLM-controlled Diffusion (SLD). SLD is a framework that generates an image from the input prompt, assesses its alignment with the prompt, and performs self-corrections on the inaccuracies in the generated image. Steered by an LLM controller, SLD turns text-to-image generation into an iterative closed-loop process, ensuring correctness in the resulting image. SLD is not only training-free but can also be seamlessly integrated with diffusion models behind API access, such as DALL-E 3, to further boost the performance of state-of-the-art diffusion models. Experimental results show that our approach can rectify a majority of incorrect generations, particularly in generative numeracy, attribute binding, and spatial relationships. Furthermore, by simply adjusting the instructions to the LLM, SLD can perform image editing tasks, bridging the gap between text-to-image generation and image editing pipelines. We will make our code available for future research and applications.
Neutral Editing Framework for Diffusion-based Video Editing
Dec 10, 2023Text-conditioned image editing has succeeded in various types of editing based on a diffusion framework. Unfortunately, this success did not carry over to a video, which continues to be challenging. Existing video editing systems are still limited to rigid-type editing such as style transfer and object overlay. To this end, this paper proposes Neutral Editing (NeuEdit) framework to enable complex non-rigid editing by changing the motion of a person/object in a video, which has never been attempted before. NeuEdit introduces a concept of `neutralization' that enhances a tuning-editing process of diffusion-based editing systems in a model-agnostic manner by leveraging input video and text without any other auxiliary aids (e.g., visual masks, video captions). Extensive experiments on numerous videos demonstrate adaptability and effectiveness of the NeuEdit framework. The website of our work is available here: https://neuedit.github.io
Symptom-based Machine Learning Models for the Early Detection of COVID-19: A Narrative Review
Dec 08, 2023Despite the widespread testing protocols for COVID-19, there are still significant challenges in early detection of the disease, which is crucial for preventing its spread and optimizing patient outcomes. Owing to the limited testing capacity in resource-strapped settings and the limitations of the available traditional methods of testing, it has been established that a fast and efficient strategy is important to fully stop the virus. Machine learning models can analyze large datasets, incorporating patient-reported symptoms, clinical data, and medical imaging. Symptom-based detection methods have been developed to predict COVID-19, and they have shown promising results. In this paper, we provide an overview of the landscape of symptoms-only machine learning models for predicting COVID-19, including their performance and limitations. The review will also examine the performance of symptom-based models when compared to image-based models. Because different studies used varying datasets, methodologies, and performance metrics. Selecting the model that performs best relies on the context and objectives of the research. However, based on the results, we observed that ensemble classifier performed exceptionally well in predicting the occurrence of COVID-19 based on patient symptoms with the highest overall accuracy of 97.88%. Gradient Boosting Algorithm achieved an AUC (Area Under the Curve) of 0.90 and identified key features contributing to the decision-making process. Image-based models, as observed in the analyzed studies, have consistently demonstrated higher accuracy than symptom-based models, often reaching impressive levels ranging from 96.09% to as high as 99%.
Generative Network Layer for Communication Systems with Artificial Intelligence
Dec 08, 2023The traditional role of the network layer is the transfer of packet replicas from source to destination through intermediate network nodes. We present a generative network layer that uses Generative AI (GenAI) at intermediate or edge network nodes and analyze its impact on the required data rates in the network. We conduct a case study where the GenAI-aided nodes generate images from prompts that consist of substantially compressed latent representations. The results from network flow analyses under image quality constraints show that the generative network layer can achieve an improvement of more than 100% in terms of the required data rate.