 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Subject-Based Domain Adaptation for Facial Expression Recognition
Dec 09, 2023
Adapting a deep learning (DL) model to a specific target individual is a challenging task in facial expression recognition (FER) that may be achieved using unsupervised domain adaptation (UDA) methods. Although several UDA methods have been proposed to adapt deep FER models across source and target data sets, multiple subject-specific source domains are needed to accurately represent the intra- and inter-person variability in subject-based adaption. In this paper, we consider the setting where domains correspond to individuals, not entire datasets. Unlike UDA, multi-source domain adaptation (MSDA) methods can leverage multiple source datasets to improve the accuracy and robustness of the target model. However, previous methods for MSDA adapt image classification models across datasets and do not scale well to a larger number of source domains. In this paper, a new MSDA method is introduced for subject-based domain adaptation in FER. It efficiently leverages information from multiple source subjects (labeled source domain data) to adapt a deep FER model to a single target individual (unlabeled target domain data). During adaptation, our Subject-based MSDA first computes a between-source discrepancy loss to mitigate the domain shift among data from several source subjects. Then, a new strategy is employed to generate augmented confident pseudo-labels for the target subject, allowing a reduction in the domain shift between source and target subjects. Experiments\footnote{\textcolor{red}{\textbf{Supplementary material} contains our code, which will be made public, and additional experimental results.}} on the challenging BioVid heat and pain dataset (PartA) with 87 subjects shows that our Subject-based MSDA can outperform state-of-the-art methods yet scale well to multiple subject-based source domains.
Assessing Test-time Variability for Interactive 3D Medical Image Segmentation with Diverse Point Prompts
Nov 13, 2023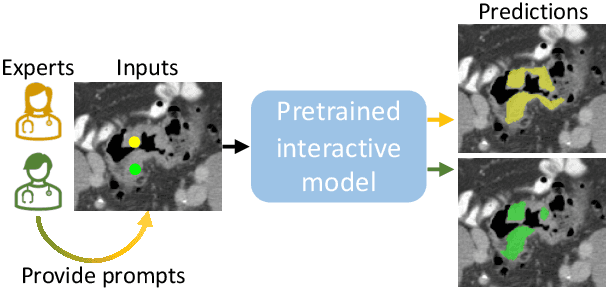
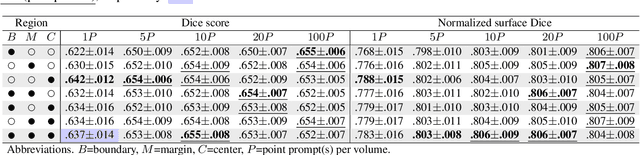
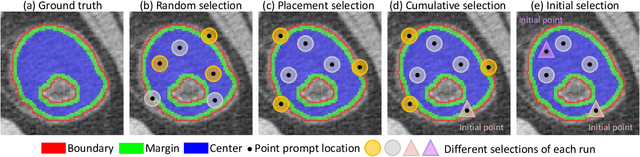
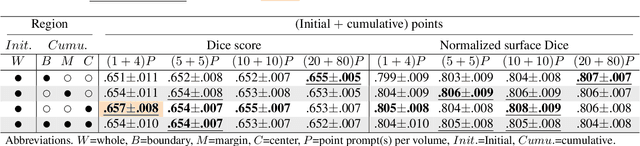
Interactive segmentation model leverages prompts from users to produce robust segmentation. This advancement is facilitated by prompt engineering, where interactive prompts serve as strong priors during test-time. However, this is an inherently subjective and hard-to-reproduce process. The variability in user expertise and inherently ambiguous boundaries in medical images can lead to inconsistent prompt selections, potentially affecting segmentation accuracy. This issue has not yet been extensively explored for medical imaging. In this paper, we assess the test-time variability for interactive medical image segmentation with diverse point prompts. For a given target region, the point is classified into three sub-regions: boundary, margin, and center. Our goal is to identify a straightforward and efficient approach for optimal prompt selection during test-time based on three considerations: (1) benefits of additional prompts, (2) effects of prompt placement, and (3) strategies for optimal prompt selection. We conduct extensive experiments on the public Medical Segmentation Decathlon dataset for challenging colon tumor segmentation task. We suggest an optimal strategy for prompt selection during test-time, supported by comprehensive results. The code is publicly available at https://github.com/MedICL-VU/variability
Assist Is Just as Important as the Goal: Image Resurfacing to Aid Model's Robust Prediction
Nov 02, 2023Adversarial patches threaten visual AI models in the real world. The number of patches in a patch attack is variable and determines the attack's potency in a specific environment. Most existing defenses assume a single patch in the scene, and the multiple patch scenarios are shown to overcome them. This paper presents a model-agnostic defense against patch attacks based on total variation for image resurfacing (TVR). The TVR is an image-cleansing method that processes images to remove probable adversarial regions. TVR can be utilized solely or augmented with a defended model, providing multi-level security for robust prediction. TVR nullifies the influence of patches in a single image scan with no prior assumption on the number of patches in the scene. We validate TVR on the ImageNet-Patch benchmark dataset and with real-world physical objects, demonstrating its ability to mitigate patch attack.
Diffusion Illusions: Hiding Images in Plain Sight
Dec 06, 2023

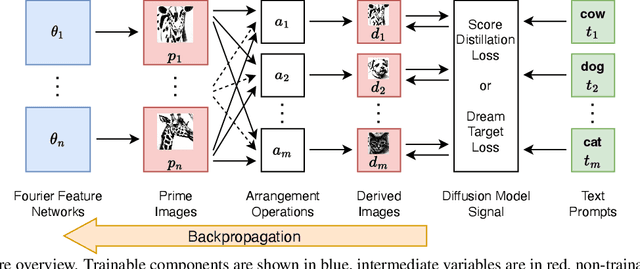
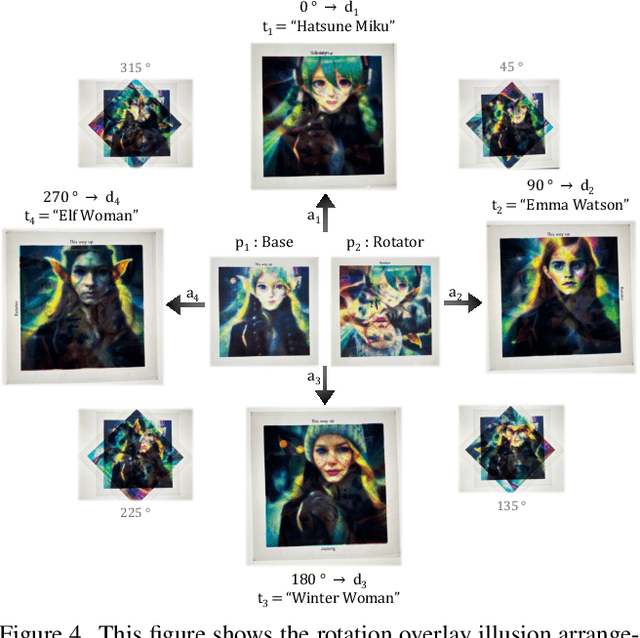
We explore the problem of computationally generating special `prime' images that produce optical illusions when physically arranged and viewed in a certain way. First, we propose a formal definition for this problem. Next, we introduce Diffusion Illusions, the first comprehensive pipeline designed to automatically generate a wide range of these illusions. Specifically, we both adapt the existing `score distillation loss' and propose a new `dream target loss' to optimize a group of differentially parametrized prime images, using a frozen text-to-image diffusion model. We study three types of illusions, each where the prime images are arranged in different ways and optimized using the aforementioned losses such that images derived from them align with user-chosen text prompts or images. We conduct comprehensive experiments on these illusions and verify the effectiveness of our proposed method qualitatively and quantitatively. Additionally, we showcase the successful physical fabrication of our illusions -- as they are all designed to work in the real world. Our code and examples are publicly available at our interactive project website: https://diffusionillusions.com
DreamComposer: Controllable 3D Object Generation via Multi-View Conditions
Dec 06, 2023Utilizing pre-trained 2D large-scale generative models, recent works are capable of generating high-quality novel views from a single in-the-wild image. However, due to the lack of information from multiple views, these works encounter difficulties in generating controllable novel views. In this paper, we present DreamComposer, a flexible and scalable framework that can enhance existing view-aware diffusion models by injecting multi-view conditions. Specifically, DreamComposer first uses a view-aware 3D lifting module to obtain 3D representations of an object from multiple views. Then, it renders the latent features of the target view from 3D representations with the multi-view feature fusion module. Finally the target view features extracted from multi-view inputs are injected into a pre-trained diffusion model. Experiments show that DreamComposer is compatible with state-of-the-art diffusion models for zero-shot novel view synthesis, further enhancing them to generate high-fidelity novel view images with multi-view conditions, ready for controllable 3D object reconstruction and various other applications.
Active Wildfires Detection and Dynamic Escape Routes Planning for Humans through Information Fusion between Drones and Satellites
Dec 06, 2023UAVs are playing an increasingly important role in the field of wilderness rescue by virtue of their flexibility. This paper proposes a fusion of UAV vision technology and satellite image analysis technology for active wildfires detection and road networks extraction of wildfire areas and real-time dynamic escape route planning for people in distress. Firstly, the fire source location and the segmentation of smoke and flames are targeted based on Sentinel 2 satellite imagery. Secondly, the road segmentation and the road condition assessment are performed by D-linkNet and NDVI values in the central area of the fire source by UAV. Finally, the dynamic optimal route planning for humans in real time is performed by the weighted A* algorithm in the road network with the dynamic fire spread model. Taking the Chongqing wildfire on August 24, 2022, as a case study, the results demonstrate that the dynamic escape route planning algorithm can provide an optimal real-time navigation path for humans in the presence of fire through the information fusion of UAVs and satellites.
An AI for Scientific Discovery Route between Amorphous Networks and Mechanical Behavior
Dec 06, 2023"AI for science" is widely recognized as a future trend in the development of scientific research. Currently, although machine learning algorithms have played a crucial role in scientific research with numerous successful cases, relatively few instances exist where AI assists researchers in uncovering the underlying physical mechanisms behind a certain phenomenon and subsequently using that mechanism to improve machine learning algorithms' efficiency. This article uses the investigation into the relationship between extreme Poisson's ratio values and the structure of amorphous networks as a case study to illustrate how machine learning methods can assist in revealing underlying physical mechanisms. Upon recognizing that the Poisson's ratio relies on the low-frequency vibrational modes of dynamical matrix, we can then employ a convolutional neural network, trained on the dynamical matrix instead of traditional image recognition, to predict the Poisson's ratio of amorphous networks with a much higher efficiency. Through this example, we aim to showcase the role that artificial intelligence can play in revealing fundamental physical mechanisms, which subsequently improves the machine learning algorithms significantly.
Channel-Transferable Semantic Communications for Multi-User OFDM-NOMA Systems
Dec 06, 2023Semantic communications are expected to become the core new paradigms of the sixth generation (6G) wireless networks. Most existing works implicitly utilize channel information for codecs training, which leads to poor communications when channel type or statistical characteristics change. To tackle this issue posed by various channels, a novel channel-transferable semantic communications (CT-SemCom) framework is proposed, which adapts the codecs learned on one type of channel to other types of channels. Furthermore, integrating the proposed framework and the orthogonal frequency division multiplexing systems integrating non-orthogonal multiple access technologies, i.e., OFDM-NOMA systems, a power allocation problem to realize the transfer from additive white Gaussian noise (AWGN) channels to multi-subcarrier Rayleigh fading channels is formulated. We then design a semantics-similar dual transformation (SSDT) algorithm to derive analytical solutions with low complexity. Simulation results show that the proposed CT-SemCom framework with SSDT algorithm significantly outperforms the existing work w.r.t. channel transferability, e.g., the peak signal-to-noise ratio (PSNR) of image transmission improves by 4.2-7.3 dB under different variances of Rayleigh fading channels.
AntifakePrompt: Prompt-Tuned Vision-Language Models are Fake Image Detectors
Oct 26, 2023Deep generative models can create remarkably photorealistic fake images while raising concerns about misinformation and copyright infringement, known as deepfake threats. Deepfake detection technique is developed to distinguish between real and fake images, where the existing methods typically learn classifiers in the image domain or various feature domains. However, the generalizability of deepfake detection against emerging and more advanced generative models remains challenging. In this paper, being inspired by the zero-shot advantages of Vision-Language Models (VLMs), we propose a novel approach using VLMs (e.g. InstructBLIP) and prompt tuning techniques to improve the deepfake detection accuracy over unseen data. We formulate deepfake detection as a visual question answering problem, and tune soft prompts for InstructBLIP to answer the real/fake information of a query image. We conduct full-spectrum experiments on datasets from 3 held-in and 13 held-out generative models, covering modern text-to-image generation, image editing and image attacks. Results demonstrate that (1) the deepfake detection accuracy can be significantly and consistently improved (from 58.8% to 91.31%, in average accuracy over unseen data) using pretrained vision-language models with prompt tuning; (2) our superior performance is at less cost of trainable parameters, resulting in an effective and efficient solution for deepfake detection. Code and models can be found at https://github.com/nctu-eva-lab/AntifakePrompt.
Kernel Diffusion: An Alternate Approach to Blind Deconvolution
Dec 04, 2023Blind deconvolution problems are severely ill-posed because neither the underlying signal nor the forward operator are not known exactly. Conventionally, these problems are solved by alternating between estimation of the image and kernel while keeping the other fixed. In this paper, we show that this framework is flawed because of its tendency to get trapped in local minima and, instead, suggest the use of a kernel estimation strategy with a non-blind solver. This framework is employed by a diffusion method which is trained to sample the blur kernel from the conditional distribution with guidance from a pre-trained non-blind solver. The proposed diffusion method leads to state-of-the-art results on both synthetic and real blur datasets.