 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Multi-View Spectrogram Transformer for Respiratory Sound Classification
Dec 05, 2023
Deep neural networks have been applied to audio spectrograms for respiratory sound classification. Existing models often treat the spectrogram as a synthetic image while overlooking its physical characteristics. In this paper, a Multi-View Spectrogram Transformer (MVST) is proposed to embed different views of time-frequency characteristics into the vision transformer. Specifically, the proposed MVST splits the mel-spectrogram into different sized patches, representing the multi-view acoustic elements of a respiratory sound. These patches and positional embeddings are then fed into transformer encoders to extract the attentional information among patches through a self-attention mechanism. Finally, a gated fusion scheme is designed to automatically weigh the multi-view features to highlight the best one in a specific scenario. Experimental results on the ICBHI dataset demonstrate that the proposed MVST significantly outperforms state-of-the-art methods for classifying respiratory sounds.
MCAD: Multi-teacher Cross-modal Alignment Distillation for efficient image-text retrieval
Oct 30, 2023With the success of large-scale visual-language pretraining models and the wide application of image-text retrieval in industry areas, reducing the model size and streamlining their terminal-device deployment have become urgently necessary. The mainstream model structures for image-text retrieval are single-stream and dual-stream, both aiming to close the semantic gap between visual and textual modalities. Dual-stream models excel at offline indexing and fast inference, while single-stream models achieve more accurate cross-model alignment by employing adequate feature fusion. We propose a multi-teacher cross-modality alignment distillation (MCAD) technique to integrate the advantages of single-stream and dual-stream models. By incorporating the fused single-stream features into the image and text features of the dual-stream model, we formulate new modified teacher features and logits. Then, we conduct both logit and feature distillation to boost the capability of the student dual-stream model, achieving high retrieval performance without increasing inference complexity. Extensive experiments demonstrate the remarkable performance and high efficiency of MCAD on image-text retrieval tasks. Furthermore, we implement a mobile CLIP model on Snapdragon clips with only 93M running memory and 30ms search latency, without apparent performance degradation of the original large CLIP.
FPM-INR: Fourier ptychographic microscopy image stack reconstruction using implicit neural representations
Oct 27, 2023Image stacks provide invaluable 3D information in various biological and pathological imaging applications. Fourier ptychographic microscopy (FPM) enables reconstructing high-resolution, wide field-of-view image stacks without z-stack scanning, thus significantly accelerating image acquisition. However, existing FPM methods take tens of minutes to reconstruct and gigabytes of memory to store a high-resolution volumetric scene, impeding fast gigapixel-scale remote digital pathology. While deep learning approaches have been explored to address this challenge, existing methods poorly generalize to novel datasets and can produce unreliable hallucinations. This work presents FPM-INR, a compact and efficient framework that integrates physics-based optical models with implicit neural representations (INR) to represent and reconstruct FPM image stacks. FPM-INR is agnostic to system design or sample types and does not require external training data. In our demonstrated experiments, FPM-INR substantially outperforms traditional FPM algorithms with up to a 25-fold increase in speed and an 80-fold reduction in memory usage for continuous image stack representations.
Inject Semantic Concepts into Image Tagging for Open-Set Recognition
Oct 23, 2023In this paper, we introduce the Recognize Anything Plus Model~(RAM++), a fundamental image recognition model with strong open-set recognition capabilities, by injecting semantic concepts into image tagging training framework. Previous approaches are either image tagging models constrained by limited semantics, or vision-language models with shallow interaction for suboptimal performance in multi-tag recognition. In contrast, RAM++ integrates image-text alignment and image-tagging within a unified fine-grained interaction framework based on image-tags-text triplets. This design enables RAM++ not only excel in identifying predefined categories, but also significantly augment the recognition ability in open-set categories. Moreover, RAM++ employs large language models~(LLMs) to generate diverse visual tag descriptions, pioneering the integration of LLM's knowledge into image tagging training. This approach empowers RAM++ to integrate visual description concepts for open-set recognition during inference. Evaluations on comprehensive image recognition benchmarks demonstrate RAM++ exceeds existing state-of-the-art (SOTA) fundamental image recognition models on most aspects. Specifically, for predefined common-used tag categories, RAM++ showcases 10.2 mAP and 15.4 mAP enhancements over CLIP on OpenImages and ImageNet. For open-set categories beyond predefined, RAM++ records improvements of 5 mAP and 6.4 mAP over CLIP and RAM respectively on OpenImages. For diverse human-object interaction phrases, RAM++ achieves 7.8 mAP and 4.7 mAP improvements on the HICO benchmark. Code, datasets and pre-trained models are available at \url{https://github.com/xinyu1205/recognize-anything}.
Learning graph-Fourier spectra of textured surface images for defect localization
Dec 02, 2023
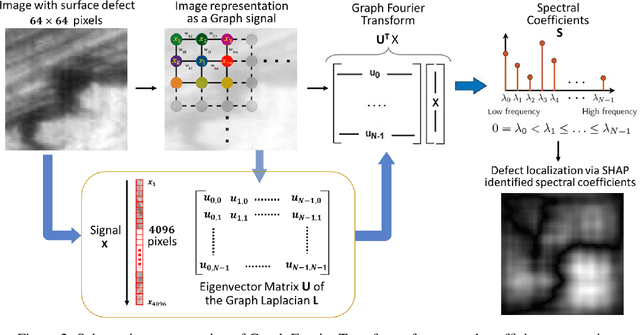
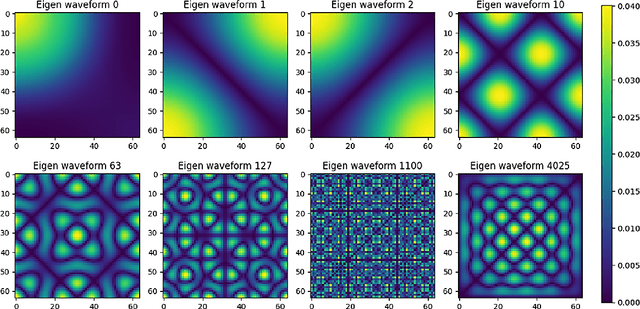
In the realm of industrial manufacturing, product inspection remains a significant bottleneck, with only a small fraction of manufactured items undergoing inspection for surface defects. Advances in imaging systems and AI can allow automated full inspection of manufactured surfaces. However, even the most contemporary imaging and machine learning methods perform poorly for detecting defects in images with highly textured backgrounds, that stem from diverse manufacturing processes. This paper introduces an approach based on graph Fourier analysis to automatically identify defective images, as well as crucial graph Fourier coefficients that inform the defects in images amidst highly textured backgrounds. The approach capitalizes on the ability of graph representations to capture the complex dynamics inherent in high-dimensional data, preserving crucial locality properties in a lower dimensional space. A convolutional neural network model (1D-CNN) was trained with the coefficients of the graph Fourier transform of the images as the input to identify, with classification accuracy of 99.4%, if the image contains a defect. An explainable AI method using SHAP (SHapley Additive exPlanations) was used to further analyze the trained 1D-CNN model to discern important spectral coefficients for each image. This approach sheds light on the crucial contribution of low-frequency graph eigen waveforms to precisely localize surface defects in images, thereby advancing the realization of zero-defect manufacturing.
$Z^*$: Zero-shot Style Transfer via Attention Rearrangement
Nov 25, 2023Despite the remarkable progress in image style transfer, formulating style in the context of art is inherently subjective and challenging. In contrast to existing learning/tuning methods, this study shows that vanilla diffusion models can directly extract style information and seamlessly integrate the generative prior into the content image without retraining. Specifically, we adopt dual denoising paths to represent content/style references in latent space and then guide the content image denoising process with style latent codes. We further reveal that the cross-attention mechanism in latent diffusion models tends to blend the content and style images, resulting in stylized outputs that deviate from the original content image. To overcome this limitation, we introduce a cross-attention rearrangement strategy. Through theoretical analysis and experiments, we demonstrate the effectiveness and superiority of the diffusion-based $\underline{Z}$ero-shot $\underline{S}$tyle $\underline{T}$ransfer via $\underline{A}$ttention $\underline{R}$earrangement, Z-STAR.
Speed Up Federated Learning in Heterogeneous Environment: A Dynamic Tiering Approach
Dec 09, 2023Federated learning (FL) enables collaboratively training a model while keeping the training data decentralized and private. However, one significant impediment to training a model using FL, especially large models, is the resource constraints of devices with heterogeneous computation and communication capacities as well as varying task sizes. Such heterogeneity would render significant variations in the training time of clients, resulting in a longer overall training time as well as a waste of resources in faster clients. To tackle these heterogeneity issues, we propose the Dynamic Tiering-based Federated Learning (DTFL) system where slower clients dynamically offload part of the model to the server to alleviate resource constraints and speed up training. By leveraging the concept of Split Learning, DTFL offloads different portions of the global model to clients in different tiers and enables each client to update the models in parallel via local-loss-based training. This helps reduce the computation and communication demand on resource-constrained devices and thus mitigates the straggler problem. DTFL introduces a dynamic tier scheduler that uses tier profiling to estimate the expected training time of each client, based on their historical training time, communication speed, and dataset size. The dynamic tier scheduler assigns clients to suitable tiers to minimize the overall training time in each round. We first theoretically prove the convergence properties of DTFL. We then train large models (ResNet-56 and ResNet-110) on popular image datasets (CIFAR-10, CIFAR-100, CINIC-10, and HAM10000) under both IID and non-IID systems. Extensive experimental results show that compared with state-of-the-art FL methods, DTFL can significantly reduce the training time while maintaining model accuracy.
Subject-Based Domain Adaptation for Facial Expression Recognition
Dec 09, 2023Adapting a deep learning (DL) model to a specific target individual is a challenging task in facial expression recognition (FER) that may be achieved using unsupervised domain adaptation (UDA) methods. Although several UDA methods have been proposed to adapt deep FER models across source and target data sets, multiple subject-specific source domains are needed to accurately represent the intra- and inter-person variability in subject-based adaption. In this paper, we consider the setting where domains correspond to individuals, not entire datasets. Unlike UDA, multi-source domain adaptation (MSDA) methods can leverage multiple source datasets to improve the accuracy and robustness of the target model. However, previous methods for MSDA adapt image classification models across datasets and do not scale well to a larger number of source domains. In this paper, a new MSDA method is introduced for subject-based domain adaptation in FER. It efficiently leverages information from multiple source subjects (labeled source domain data) to adapt a deep FER model to a single target individual (unlabeled target domain data). During adaptation, our Subject-based MSDA first computes a between-source discrepancy loss to mitigate the domain shift among data from several source subjects. Then, a new strategy is employed to generate augmented confident pseudo-labels for the target subject, allowing a reduction in the domain shift between source and target subjects. Experiments\footnote{\textcolor{red}{\textbf{Supplementary material} contains our code, which will be made public, and additional experimental results.}} on the challenging BioVid heat and pain dataset (PartA) with 87 subjects shows that our Subject-based MSDA can outperform state-of-the-art methods yet scale well to multiple subject-based source domains.
Benchmark Generation Framework with Customizable Distortions for Image Classifier Robustness
Oct 28, 2023We present a novel framework for generating adversarial benchmarks to evaluate the robustness of image classification models. Our framework allows users to customize the types of distortions to be optimally applied to images, which helps address the specific distortions relevant to their deployment. The benchmark can generate datasets at various distortion levels to assess the robustness of different image classifiers. Our results show that the adversarial samples generated by our framework with any of the image classification models, like ResNet-50, Inception-V3, and VGG-16, are effective and transferable to other models causing them to fail. These failures happen even when these models are adversarially retrained using state-of-the-art techniques, demonstrating the generalizability of our adversarial samples. We achieve competitive performance in terms of net $L_2$ distortion compared to state-of-the-art benchmark techniques on CIFAR-10 and ImageNet; however, we demonstrate our framework achieves such results with simple distortions like Gaussian noise without introducing unnatural artifacts or color bleeds. This is made possible by a model-based reinforcement learning (RL) agent and a technique that reduces a deep tree search of the image for model sensitivity to perturbations, to a one-level analysis and action. The flexibility of choosing distortions and setting classification probability thresholds for multiple classes makes our framework suitable for algorithmic audits.
From Posterior Sampling to Meaningful Diversity in Image Restoration
Oct 24, 2023Image restoration problems are typically ill-posed in the sense that each degraded image can be restored in infinitely many valid ways. To accommodate this, many works generate a diverse set of outputs by attempting to randomly sample from the posterior distribution of natural images given the degraded input. Here we argue that this strategy is commonly of limited practical value because of the heavy tail of the posterior distribution. Consider for example inpainting a missing region of the sky in an image. Since there is a high probability that the missing region contains no object but clouds, any set of samples from the posterior would be entirely dominated by (practically identical) completions of sky. However, arguably, presenting users with only one clear sky completion, along with several alternative solutions such as airships, birds, and balloons, would better outline the set of possibilities. In this paper, we initiate the study of meaningfully diverse image restoration. We explore several post-processing approaches that can be combined with any diverse image restoration method to yield semantically meaningful diversity. Moreover, we propose a practical approach for allowing diffusion based image restoration methods to generate meaningfully diverse outputs, while incurring only negligent computational overhead. We conduct extensive user studies to analyze the proposed techniques, and find the strategy of reducing similarity between outputs to be significantly favorable over posterior sampling. Code and examples are available in https://noa-cohen.github.io/MeaningfulDiversityInIR