 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
How Well Does GPT-4V(ision) Adapt to Distribution Shifts? A Preliminary Investigation
Dec 13, 2023
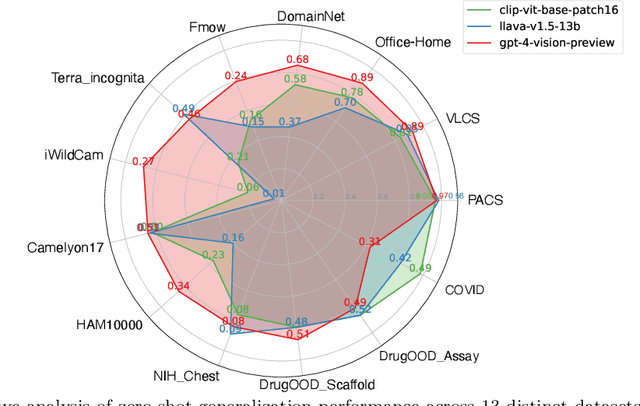
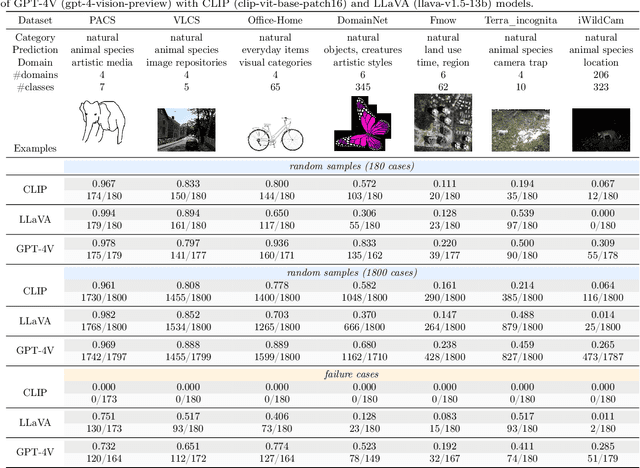

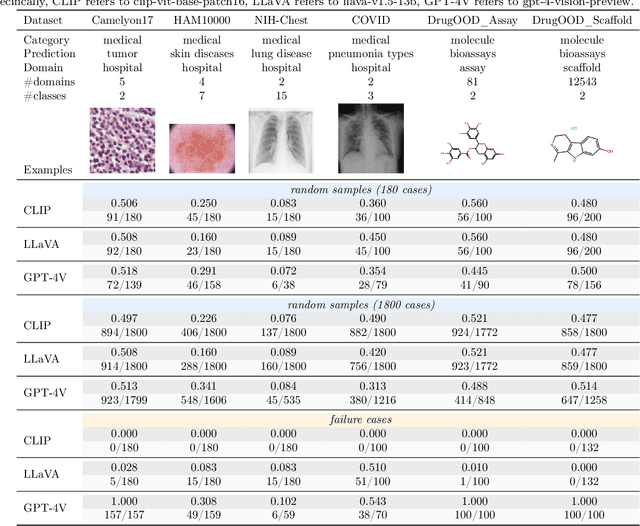
In machine learning, generalization against distribution shifts -- where deployment conditions diverge from the training scenarios -- is crucial, particularly in fields like climate modeling, biomedicine, and autonomous driving. The emergence of foundation models, distinguished by their extensive pretraining and task versatility, has led to an increased interest in their adaptability to distribution shifts. GPT-4V(ision) acts as the most advanced publicly accessible multimodal foundation model, with extensive applications across various domains, including anomaly detection, video understanding, image generation, and medical diagnosis. However, its robustness against data distributions remains largely underexplored. Addressing this gap, this study rigorously evaluates GPT-4V's adaptability and generalization capabilities in dynamic environments, benchmarking against prominent models like CLIP and LLaVA. We delve into GPT-4V's zero-shot generalization across 13 diverse datasets spanning natural, medical, and molecular domains. We further investigate its adaptability to controlled data perturbations and examine the efficacy of in-context learning as a tool to enhance its adaptation. Our findings delineate GPT-4V's capability boundaries in distribution shifts, shedding light on its strengths and limitations across various scenarios. Importantly, this investigation contributes to our understanding of how AI foundation models generalize to distribution shifts, offering pivotal insights into their adaptability and robustness. Code is publicly available at https://github.com/jameszhou-gl/gpt-4v-distribution-shift.
IMProv: Inpainting-based Multimodal Prompting for Computer Vision Tasks
Dec 04, 2023
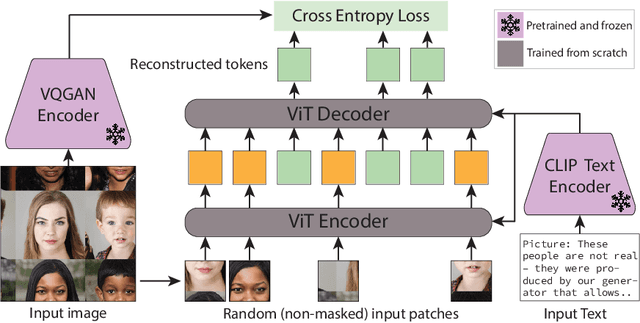
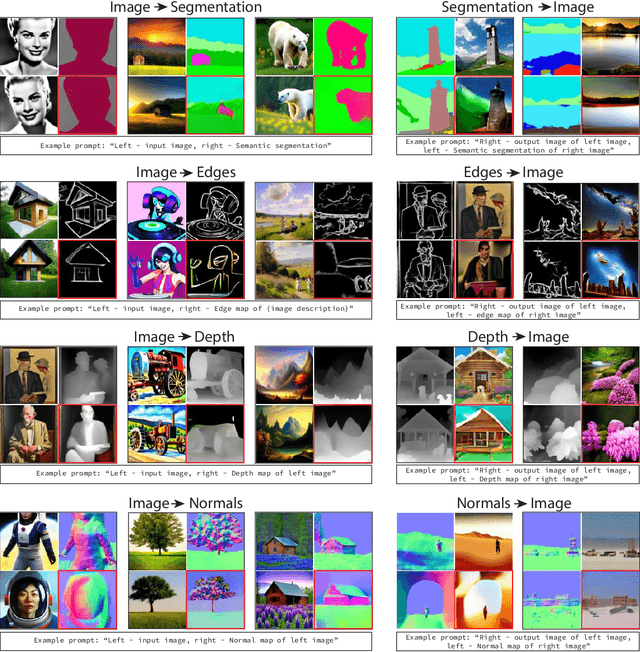

In-context learning allows adapting a model to new tasks given a task description at test time. In this paper, we present IMProv - a generative model that is able to in-context learn visual tasks from multimodal prompts. Given a textual description of a visual task (e.g. "Left: input image, Right: foreground segmentation"), a few input-output visual examples, or both, the model in-context learns to solve it for a new test input. We train a masked generative transformer on a new dataset of figures from computer vision papers and their associated captions, together with a captioned large-scale image-text dataset. During inference time, we prompt the model with text and/or image task example(s) and have the model inpaint the corresponding output. We show that training our model with text conditioning and scaling the dataset size improves in-context learning for computer vision tasks by over +10\% AP for Foreground Segmentation, over +5\% gains in AP for Single Object Detection, and almost 20\% lower LPIPS in Colorization. Our empirical results suggest that vision and language prompts are complementary and it is advantageous to use both to achieve better in-context learning performance. Project page is available at https://jerryxu.net/IMProv .
Plasticine3D: Non-rigid 3D editting with text guidance
Dec 15, 2023With the help of Score Distillation Sampling(SDS) and the rapid development of various trainable 3D representations, Text-to-Image(T2I) diffusion models have been applied to 3D generation tasks and achieved considerable results. There are also some attempts toward the task of editing 3D objects leveraging this Text-to-3D pipeline. However, most methods currently focus on adding additional geometries, overwriting textures or both. But few of them can perform non-rigid transformation of 3D objects. For those who can perform non-rigid editing, on the other hand, suffer from low-resolution, lack of fidelity and poor flexibility. In order to address these issues, we present: Plasticine3D, a general, high-fidelity, photo-realistic and controllable non-rigid editing pipeline. Firstly, our work divides the editing process into a geometry editing stage and a texture editing stage to achieve more detailed and photo-realistic results ; Secondly, in order to perform non-rigid transformation with controllable results while maintain the fidelity towards original 3D models in the same time, we propose a multi-view-embedding(MVE) optimization strategy to ensure that the diffusion model learns the overall features of the original object and an embedding-fusion(EF) to control the degree of editing by adjusting the value of the fusing rate. We also design a geometry processing step before optimizing on the base geometry to cope with different needs of various editing tasks. Further more, to fully leverage the geometric prior from the original 3D object, we provide an optional replacement of score distillation sampling named score projection sampling(SPS) which enables us to directly perform optimization from the origin 3D mesh in most common median non-rigid editing scenarios. We demonstrate the effectiveness of our method on both the non-rigid 3D editing task and general 3D editing task.
Make-A-Storyboard: A General Framework for Storyboard with Disentangled and Merged Control
Dec 06, 2023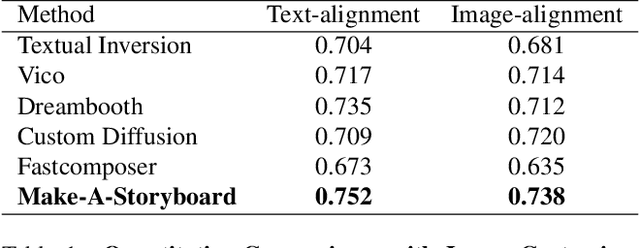
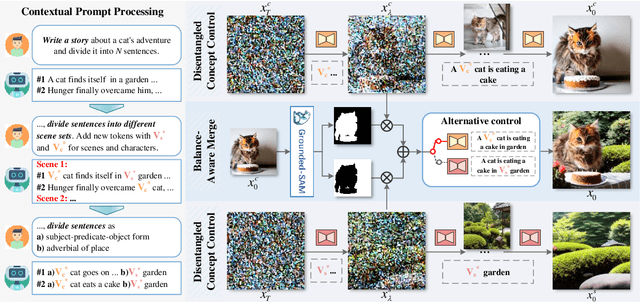


Story Visualization aims to generate images aligned with story prompts, reflecting the coherence of storybooks through visual consistency among characters and scenes.Whereas current approaches exclusively concentrate on characters and neglect the visual consistency among contextually correlated scenes, resulting in independent character images without inter-image coherence.To tackle this issue, we propose a new presentation form for Story Visualization called Storyboard, inspired by film-making, as illustrated in Fig.1.Specifically, a Storyboard unfolds a story into visual representations scene by scene. Within each scene in Storyboard, characters engage in activities at the same location, necessitating both visually consistent scenes and characters.For Storyboard, we design a general framework coined as Make-A-Storyboard that applies disentangled control over the consistency of contextual correlated characters and scenes and then merge them to form harmonized images.Extensive experiments demonstrate 1) Effectiveness.the effectiveness of the method in story alignment, character consistency, and scene correlation; 2) Generalization. Our method could be seamlessly integrated into mainstream Image Customization methods, empowering them with the capability of story visualization.
Novel class discovery meets foundation models for 3D semantic segmentation
Dec 06, 2023The task of Novel Class Discovery (NCD) in semantic segmentation entails training a model able to accurately segment unlabelled (novel) classes, relying on the available supervision from annotated (base) classes. Although extensively investigated in 2D image data, the extension of the NCD task to the domain of 3D point clouds represents a pioneering effort, characterized by assumptions and challenges that are not present in the 2D case. This paper represents an advancement in the analysis of point cloud data in four directions. Firstly, it introduces the novel task of NCD for point cloud semantic segmentation. Secondly, it demonstrates that directly transposing the only existing NCD method for 2D image semantic segmentation to 3D data yields suboptimal results. Thirdly, a new NCD approach based on online clustering, uncertainty estimation, and semantic distillation is presented. Lastly, a novel evaluation protocol is proposed to rigorously assess the performance of NCD in point cloud semantic segmentation. Through comprehensive evaluations on the SemanticKITTI, SemanticPOSS, and S3DIS datasets, the paper demonstrates substantial superiority of the proposed method over the considered baselines.
GCFA:Geodesic Curve Feature Augmentation via Shape Space Theory
Dec 06, 2023Deep learning has yielded remarkable outcomes in various domains. However, the challenge of requiring large-scale labeled samples still persists in deep learning. Thus, data augmentation has been introduced as a critical strategy to train deep learning models. However, data augmentation suffers from information loss and poor performance in small sample environments. To overcome these drawbacks, we propose a feature augmentation method based on shape space theory, i.e., Geodesic curve feature augmentation, called GCFA in brevity. First, we extract features from the image with the neural network model. Then, the multiple image features are projected into a pre-shape space as features. In the pre-shape space, a Geodesic curve is built to fit the features. Finally, the many generated features on the Geodesic curve are used to train the various machine learning models. The GCFA module can be seamlessly integrated with most machine learning methods. And the proposed method is simple, effective and insensitive for the small sample datasets. Several examples demonstrate that the GCFA method can greatly improve the performance of the data preprocessing model in a small sample environment.
FAAC: Facial Animation Generation with Anchor Frame and Conditional Control for Superior Fidelity and Editability
Dec 06, 2023Over recent years, diffusion models have facilitated significant advancements in video generation. Yet, the creation of face-related videos still confronts issues such as low facial fidelity, lack of frame consistency, limited editability and uncontrollable human poses. To address these challenges, we introduce a facial animation generation method that enhances both face identity fidelity and editing capabilities while ensuring frame consistency. This approach incorporates the concept of an anchor frame to counteract the degradation of generative ability in original text-to-image models when incorporating a motion module. We propose two strategies towards this objective: training-free and training-based anchor frame methods. Our method's efficacy has been validated on multiple representative DreamBooth and LoRA models, delivering substantial improvements over the original outcomes in terms of facial fidelity, text-to-image editability, and video motion. Moreover, we introduce conditional control using a 3D parametric face model to capture accurate facial movements and expressions. This solution augments the creative possibilities for facial animation generation through the integration of multiple control signals. For additional samples, please visit https://anonymous.4open.science/r/FAAC.
BenchLMM: Benchmarking Cross-style Visual Capability of Large Multimodal Models
Dec 06, 2023Large Multimodal Models (LMMs) such as GPT-4V and LLaVA have shown remarkable capabilities in visual reasoning with common image styles. However, their robustness against diverse style shifts, crucial for practical applications, remains largely unexplored. In this paper, we propose a new benchmark, BenchLMM, to assess the robustness of LMMs against three different styles: artistic image style, imaging sensor style, and application style, where each style has five sub-styles. Utilizing BenchLMM, we comprehensively evaluate state-of-the-art LMMs and reveal: 1) LMMs generally suffer performance degradation when working with other styles; 2) An LMM performs better than another model in common style does not guarantee its superior performance in other styles; 3) LMMs' reasoning capability can be enhanced by prompting LMMs to predict the style first, based on which we propose a versatile and training-free method for improving LMMs; 4) An intelligent LMM is expected to interpret the causes of its errors when facing stylistic variations. We hope that our benchmark and analysis can shed new light on developing more intelligent and versatile LMMs.
Shape Matters: Detecting Vertebral Fractures Using Differentiable Point-Based Shape Decoding
Dec 08, 2023Degenerative spinal pathologies are highly prevalent among the elderly population. Timely diagnosis of osteoporotic fractures and other degenerative deformities facilitates proactive measures to mitigate the risk of severe back pain and disability. In this study, we specifically explore the use of shape auto-encoders for vertebrae, taking advantage of advancements in automated multi-label segmentation and the availability of large datasets for unsupervised learning. Our shape auto-encoders are trained on a large set of vertebrae surface patches, leveraging the vast amount of available data for vertebra segmentation. This addresses the label scarcity problem faced when learning shape information of vertebrae from image intensities. Based on the learned shape features we train an MLP to detect vertebral body fractures. Using segmentation masks that were automatically generated using the TotalSegmentator, our proposed method achieves an AUC of 0.901 on the VerSe19 testset. This outperforms image-based and surface-based end-to-end trained models. Additionally, our results demonstrate that pre-training the models in an unsupervised manner enhances geometric methods like PointNet and DGCNN. Our findings emphasise the advantages of explicitly learning shape features for diagnosing osteoporotic vertebrae fractures. This approach improves the reliability of classification results and reduces the need for annotated labels. This study provides novel insights into the effectiveness of various encoder-decoder models for shape analysis of vertebrae and proposes a new decoder architecture: the point-based shape decoder.
An unsupervised approach towards promptable defect segmentation in laser-based additive manufacturing by Segment Anything
Dec 07, 2023Foundation models are currently driving a paradigm shift in computer vision tasks for various fields including biology, astronomy, and robotics among others, leveraging user-generated prompts to enhance their performance. In the manufacturing domain, accurate image-based defect segmentation is imperative to ensure product quality and facilitate real-time process control. However, such tasks are often characterized by multiple challenges including the absence of labels and the requirement for low latency inference among others. To address these issues, we construct a framework for image segmentation using a state-of-the-art Vision Transformer (ViT) based Foundation model (Segment Anything Model) with a novel multi-point prompt generation scheme using unsupervised clustering. We apply our framework to perform real-time porosity segmentation in a case study of laser base powder bed fusion (L-PBF) and obtain high Dice Similarity Coefficients (DSC) without the necessity for any supervised fine-tuning in the model. Using such lightweight foundation model inference in conjunction with unsupervised prompt generation, we envision the construction of a real-time anomaly detection pipeline that has the potential to revolutionize the current laser-based additive manufacturing processes, thereby facilitating the shift towards Industry 4.0 and promoting defect-free production along with operational efficiency.