 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Enhanced Edge-Perceptual Guided Image Filtering
Oct 16, 2023
Due to the powerful edge-preserving ability and low computational complexity, Guided image filter (GIF) and its improved versions has been widely applied in computer vision and image processing. However, all of them are suffered halo artifacts to some degree, as the regularization parameter increase. In the case of inconsistent structure of guidance image and input image, edge-preserving ability degradation will also happen. In this paper, a novel guided image filter is proposed by integrating an explicit first-order edge-protect constraint and an explicit residual constraint which will improve the edge-preserving ability in both cases. To illustrate the efficiency of the proposed filter, the performances are shown in some typical applications, which are single image detail enhancement, multi-scale exposure fusion, hyper spectral images classification. Both theoretical analysis and experimental results prove that the powerful edge-preserving ability of the proposed filter.
Iterative Token Evaluation and Refinement for Real-World Super-Resolution
Dec 09, 2023Real-world image super-resolution (RWSR) is a long-standing problem as low-quality (LQ) images often have complex and unidentified degradations. Existing methods such as Generative Adversarial Networks (GANs) or continuous diffusion models present their own issues including GANs being difficult to train while continuous diffusion models requiring numerous inference steps. In this paper, we propose an Iterative Token Evaluation and Refinement (ITER) framework for RWSR, which utilizes a discrete diffusion model operating in the discrete token representation space, i.e., indexes of features extracted from a VQGAN codebook pre-trained with high-quality (HQ) images. We show that ITER is easier to train than GANs and more efficient than continuous diffusion models. Specifically, we divide RWSR into two sub-tasks, i.e., distortion removal and texture generation. Distortion removal involves simple HQ token prediction with LQ images, while texture generation uses a discrete diffusion model to iteratively refine the distortion removal output with a token refinement network. In particular, we propose to include a token evaluation network in the discrete diffusion process. It learns to evaluate which tokens are good restorations and helps to improve the iterative refinement results. Moreover, the evaluation network can first check status of the distortion removal output and then adaptively select total refinement steps needed, thereby maintaining a good balance between distortion removal and texture generation. Extensive experimental results show that ITER is easy to train and performs well within just 8 iterative steps. Our codes will be available publicly.
Unsupervised Multi-modal Feature Alignment for Time Series Representation Learning
Dec 09, 2023In recent times, the field of unsupervised representation learning (URL) for time series data has garnered significant interest due to its remarkable adaptability across diverse downstream applications. Unsupervised learning goals differ from downstream tasks, making it tricky to ensure downstream task utility by focusing only on temporal feature characterization. Researchers have proposed multiple transformations to extract discriminative patterns implied in informative time series, trying to fill the gap. Despite the introduction of a variety of feature engineering techniques, e.g. spectral domain, wavelet transformed features, features in image form and symbolic features etc. the utilization of intricate feature fusion methods and dependence on heterogeneous features during inference hampers the scalability of the solutions. To address this, our study introduces an innovative approach that focuses on aligning and binding time series representations encoded from different modalities, inspired by spectral graph theory, thereby guiding the neural encoder to uncover latent pattern associations among these multi-modal features. In contrast to conventional methods that fuse features from multiple modalities, our proposed approach simplifies the neural architecture by retaining a single time series encoder, consequently leading to preserved scalability. We further demonstrate and prove mechanisms for the encoder to maintain better inductive bias. In our experimental evaluation, we validated the proposed method on a diverse set of time series datasets from various domains. Our approach outperforms existing state-of-the-art URL methods across diverse downstream tasks.
Combating the "Sameness" in AI Art: Reflections on the Interactive AI Installation Fencing Hallucination
Nov 28, 2023The article summarizes three types of "sameness" issues in Artificial Intelligence(AI) art, each occurring at different stages of development in AI image creation tools. Through the Fencing Hallucination project, the article reflects on the design of AI art production in alleviating the sense of uniformity, maintaining the uniqueness of images from an AI image synthesizer, and enhancing the connection between the artworks and the audience. This paper endeavors to stimulate the creation of distinctive AI art by recounting the efforts and insights derived from the Fencing Hallucination project, all dedicated to addressing the issue of "sameness".
Cross-BERT for Point Cloud Pretraining
Dec 08, 2023Introducing BERT into cross-modal settings raises difficulties in its optimization for handling multiple modalities. Both the BERT architecture and training objective need to be adapted to incorporate and model information from different modalities. In this paper, we address these challenges by exploring the implicit semantic and geometric correlations between 2D and 3D data of the same objects/scenes. We propose a new cross-modal BERT-style self-supervised learning paradigm, called Cross-BERT. To facilitate pretraining for irregular and sparse point clouds, we design two self-supervised tasks to boost cross-modal interaction. The first task, referred to as Point-Image Alignment, aims to align features between unimodal and cross-modal representations to capture the correspondences between the 2D and 3D modalities. The second task, termed Masked Cross-modal Modeling, further improves mask modeling of BERT by incorporating high-dimensional semantic information obtained by cross-modal interaction. By performing cross-modal interaction, Cross-BERT can smoothly reconstruct the masked tokens during pretraining, leading to notable performance enhancements for downstream tasks. Through empirical evaluation, we demonstrate that Cross-BERT outperforms existing state-of-the-art methods in 3D downstream applications. Our work highlights the effectiveness of leveraging cross-modal 2D knowledge to strengthen 3D point cloud representation and the transferable capability of BERT across modalities.
Lyrics: Boosting Fine-grained Language-Vision Alignment and Comprehension via Semantic-aware Visual Objects
Dec 08, 2023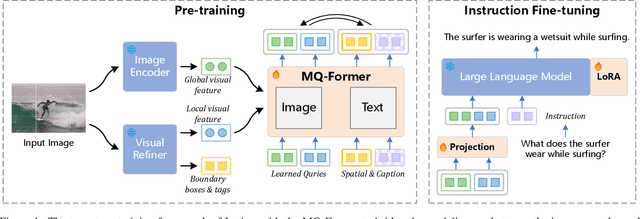
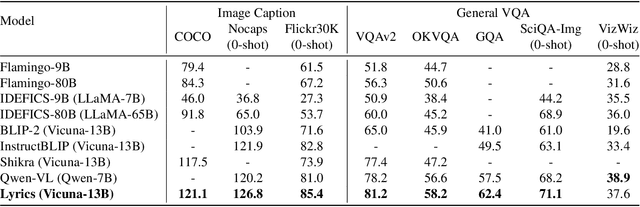
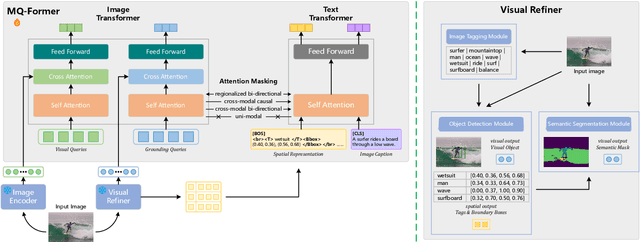
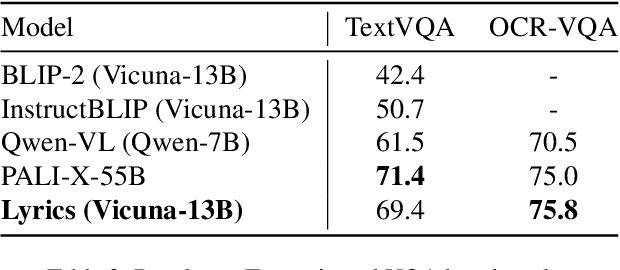
Large Vision Language Models (LVLMs) have demonstrated impressive zero-shot capabilities in various vision-language dialogue scenarios. However, the absence of fine-grained visual object detection hinders the model from understanding the details of images, leading to irreparable visual hallucinations and factual errors. In this paper, we propose Lyrics, a novel multi-modal pre-training and instruction fine-tuning paradigm that bootstraps vision-language alignment from fine-grained cross-modal collaboration. Building on the foundation of BLIP-2, Lyrics infuses local visual features extracted from a visual refiner that includes image tagging, object detection and semantic segmentation modules into the Querying Transformer, while on the text side, the language inputs equip the boundary boxes and tags derived from the visual refiner. We further introduce a two-stage training scheme, in which the pre-training stage bridges the modality gap through explicit and comprehensive vision-language alignment targets. During the instruction fine-tuning stage, we introduce semantic-aware visual feature extraction, a crucial method that enables the model to extract informative features from concrete visual objects. Our approach achieves strong performance on 13 held-out datasets across various vision-language tasks, and demonstrates promising multi-modal understanding and detailed depiction capabilities in real dialogue scenarios.
ProsDectNet: Bridging the Gap in Prostate Cancer Detection via Transrectal B-mode Ultrasound Imaging
Dec 08, 2023Interpreting traditional B-mode ultrasound images can be challenging due to image artifacts (e.g., shadowing, speckle), leading to low sensitivity and limited diagnostic accuracy. While Magnetic Resonance Imaging (MRI) has been proposed as a solution, it is expensive and not widely available. Furthermore, most biopsies are guided by Transrectal Ultrasound (TRUS) alone and can miss up to 52% cancers, highlighting the need for improved targeting. To address this issue, we propose ProsDectNet, a multi-task deep learning approach that localizes prostate cancer on B-mode ultrasound. Our model is pre-trained using radiologist-labeled data and fine-tuned using biopsy-confirmed labels. ProsDectNet includes a lesion detection and patch classification head, with uncertainty minimization using entropy to improve model performance and reduce false positive predictions. We trained and validated ProsDectNet using a cohort of 289 patients who underwent MRI-TRUS fusion targeted biopsy. We then tested our approach on a group of 41 patients and found that ProsDectNet outperformed the average expert clinician in detecting prostate cancer on B-mode ultrasound images, achieving a patient-level ROC-AUC of 82%, a sensitivity of 74%, and a specificity of 67%. Our results demonstrate that ProsDectNet has the potential to be used as a computer-aided diagnosis system to improve targeted biopsy and treatment planning.
Scaling Laws in Jet Classification
Dec 04, 2023We demonstrate the emergence of scaling laws in the benchmark top versus QCD jet classification problem in collider physics. Six distinct physically-motivated classifiers exhibit power-law scaling of the binary cross-entropy test loss as a function of training set size, with distinct power law indices. This result highlights the importance of comparing classifiers as a function of dataset size rather than for a fixed training set, as the optimal classifier may change considerably as the dataset is scaled up. We speculate on the interpretation of our results in terms of previous models of scaling laws observed in natural language and image datasets.
Diffusion Models Without Attention
Nov 30, 2023In recent advancements in high-fidelity image generation, Denoising Diffusion Probabilistic Models (DDPMs) have emerged as a key player. However, their application at high resolutions presents significant computational challenges. Current methods, such as patchifying, expedite processes in UNet and Transformer architectures but at the expense of representational capacity. Addressing this, we introduce the Diffusion State Space Model (DiffuSSM), an architecture that supplants attention mechanisms with a more scalable state space model backbone. This approach effectively handles higher resolutions without resorting to global compression, thus preserving detailed image representation throughout the diffusion process. Our focus on FLOP-efficient architectures in diffusion training marks a significant step forward. Comprehensive evaluations on both ImageNet and LSUN datasets at two resolutions demonstrate that DiffuSSMs are on par or even outperform existing diffusion models with attention modules in FID and Inception Score metrics while significantly reducing total FLOP usage.
Slice3D: Multi-Slice, Occlusion-Revealing, Single View 3D Reconstruction
Dec 03, 2023We introduce multi-slice reasoning, a new notion for single-view 3D reconstruction which challenges the current and prevailing belief that multi-view synthesis is the most natural conduit between single-view and 3D. Our key observation is that object slicing is more advantageous than altering views to reveal occluded structures. Specifically, slicing is more occlusion-revealing since it can peel through any occluders without obstruction. In the limit, i.e., with infinitely many slices, it is guaranteed to unveil all hidden object parts. We realize our idea by developing Slice3D, a novel method for single-view 3D reconstruction which first predicts multi-slice images from a single RGB image and then integrates the slices into a 3D model using a coordinate-based transformer network for signed distance prediction. The slice images can be regressed or generated, both through a U-Net based network. For the former, we inject a learnable slice indicator code to designate each decoded image into a spatial slice location, while the slice generator is a denoising diffusion model operating on the entirety of slice images stacked on the input channels. We conduct extensive evaluation against state-of-the-art alternatives to demonstrate superiority of our method, especially in recovering complex and severely occluded shape structures, amid ambiguities. All Slice3D results were produced by networks trained on a single Nvidia A40 GPU, with an inference time less than 20 seconds.