 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Stronger, Fewer, & Superior: Harnessing Vision Foundation Models for Domain Generalized Semantic Segmentation
Dec 07, 2023
In this paper, we first assess and harness various Vision Foundation Models (VFMs) in the context of Domain Generalized Semantic Segmentation (DGSS). Driven by the motivation that Leveraging Stronger pre-trained models and Fewer trainable parameters for Superior generalizability, we introduce a robust fine-tuning approach, namely Rein, to parameter-efficiently harness VFMs for DGSS. Built upon a set of trainable tokens, each linked to distinct instances, Rein precisely refines and forwards the feature maps from each layer to the next layer within the backbone. This process produces diverse refinements for different categories within a single image. With fewer trainable parameters, Rein efficiently fine-tunes VFMs for DGSS tasks, surprisingly surpassing full parameter fine-tuning. Extensive experiments across various settings demonstrate that Rein significantly outperforms state-of-the-art methods. Remarkably, with just an extra 1% of trainable parameters within the frozen backbone, Rein achieves a mIoU of 68.1% on the Cityscapes, without accessing any real urban-scene datasets.
Continual Diffusion with STAMINA: STack-And-Mask INcremental Adapters
Nov 30, 2023Recent work has demonstrated a remarkable ability to customize text-to-image diffusion models to multiple, fine-grained concepts in a sequential (i.e., continual) manner while only providing a few example images for each concept. This setting is known as continual diffusion. Here, we ask the question: Can we scale these methods to longer concept sequences without forgetting? Although prior work mitigates the forgetting of previously learned concepts, we show that its capacity to learn new tasks reaches saturation over longer sequences. We address this challenge by introducing a novel method, STack-And-Mask INcremental Adapters (STAMINA), which is composed of low-ranked attention-masked adapters and customized MLP tokens. STAMINA is designed to enhance the robust fine-tuning properties of LoRA for sequential concept learning via learnable hard-attention masks parameterized with low rank MLPs, enabling precise, scalable learning via sparse adaptation. Notably, all introduced trainable parameters can be folded back into the model after training, inducing no additional inference parameter costs. We show that STAMINA outperforms the prior SOTA for the setting of text-to-image continual customization on a 50-concept benchmark composed of landmarks and human faces, with no stored replay data. Additionally, we extended our method to the setting of continual learning for image classification, demonstrating that our gains also translate to state-of-the-art performance in this standard benchmark.
PoseGPT: Chatting about 3D Human Pose
Nov 30, 2023We introduce PoseGPT, a framework employing Large Language Models (LLMs) to understand and reason about 3D human poses from images or textual descriptions. Our work is motivated by the human ability to intuitively understand postures from a single image or a brief description, a process that intertwines image interpretation, world knowledge, and an understanding of body language. Traditional human pose estimation methods, whether image-based or text-based, often lack holistic scene comprehension and nuanced reasoning, leading to a disconnect between visual data and its real-world implications. PoseGPT addresses these limitations by embedding SMPL poses as a distinct signal token within a multi-modal LLM, enabling direct generation of 3D body poses from both textual and visual inputs. This approach not only simplifies pose prediction but also empowers LLMs to apply their world knowledge in reasoning about human poses, fostering two advanced tasks: speculative pose generation and reasoning about pose estimation. These tasks involve reasoning about humans to generate 3D poses from subtle text queries, possibly accompanied by images. We establish benchmarks for these tasks, moving beyond traditional 3D pose generation and estimation methods. Our results show that PoseGPT outperforms existing multimodal LLMs and task-sepcific methods on these newly proposed tasks. Furthermore, PoseGPT's ability to understand and generate 3D human poses based on complex reasoning opens new directions in human pose analysis.
Utilizing Radiomic Feature Analysis For Automated MRI Keypoint Detection: Enhancing Graph Applications
Nov 30, 2023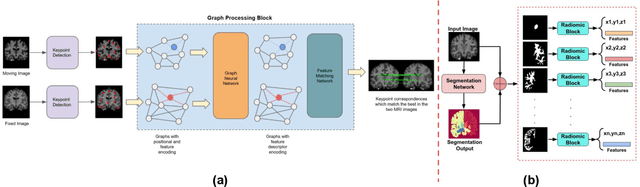

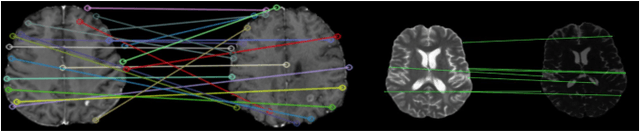

Graph neural networks (GNNs) present a promising alternative to CNNs and transformers in certain image processing applications due to their parameter-efficiency in modeling spatial relationships. Currently, a major area of research involves the converting non-graph input data for GNN-based models, notably in scenarios where the data originates from images. One approach involves converting images into nodes by identifying significant keypoints within them. Super-Retina, a semi-supervised technique, has been utilized for detecting keypoints in retinal images. However, its limitations lie in the dependency on a small initial set of ground truth keypoints, which is progressively expanded to detect more keypoints. Having encountered difficulties in detecting consistent initial keypoints in brain images using SIFT and LoFTR, we proposed a new approach: radiomic feature-based keypoint detection. Demonstrating the anatomical significance of the detected keypoints was achieved by showcasing their efficacy in improving registration processes guided by these keypoints. Subsequently, these keypoints were employed as the ground truth for the keypoint detection method (LK-SuperRetina). Furthermore, the study showcases the application of GNNs in image matching, highlighting their superior performance in terms of both the number of good matches and confidence scores. This research sets the stage for expanding GNN applications into various other applications, including but not limited to image classification, segmentation, and registration.
Knowledge Pursuit Prompting for Zero-Shot Multimodal Synthesis
Nov 30, 2023Hallucinations and unfaithful synthesis due to inaccurate prompts with insufficient semantic details are widely observed in multimodal generative models. A prevalent strategy to align multiple modalities is to fine-tune the generator with a large number of annotated text-image pairs. However, such a procedure is labor-consuming and resource-draining. The key question we ask is: can we enhance the quality and faithfulness of text-driven generative models beyond extensive text-image pair annotations? To address this question, we propose Knowledge Pursuit Prompting (KPP), a zero-shot framework that iteratively incorporates external knowledge to help generators produce reliable visual content. Instead of training generators to handle generic prompts, KPP employs a recursive knowledge query process to gather informative external facts from the knowledge base, instructs a language model to compress the acquired knowledge for prompt refinement, and utilizes text-driven generators for visual synthesis. The entire process is zero-shot, without accessing the architectures and parameters of generative models. We evaluate the framework across multiple text-driven generative tasks (image, 3D rendering, and video) on datasets of different domains. We further demonstrate the extensibility and adaptability of KPP through varying foundation model bases and instructions. Our results show that KPP is capable of generating faithful and semantically rich content across diverse visual domains, offering a promising solution to improve multimodal generative models.
Multi-view Relation Learning for Cross-domain Few-shot Hyperspectral Image Classification
Nov 02, 2023Cross-domain few-shot hyperspectral image classification focuses on learning prior knowledge from a large number of labeled samples from source domain and then transferring the knowledge to the tasks which contain only few labeled samples in target domains. Following the metric-based manner, many current methods first extract the features of the query and support samples, and then directly predict the classes of query samples according to their distance to the support samples or prototypes. The relations between samples have not been fully explored and utilized. Different from current works, this paper proposes to learn sample relations from different views and take them into the model learning process, to improve the cross-domain few-shot hyperspectral image classification. Building on current DCFSL method which adopts a domain discriminator to deal with domain-level distribution difference, the proposed method applys contrastive learning to learn the class-level sample relations to obtain more discriminable sample features. In addition, it adopts a transformer based cross-attention learning module to learn the set-level sample relations and acquire the attentions from query samples to support samples. Our experimental results have demonstrated the contribution of the multi-view relation learning mechanism for few-shot hyperspectral image classification when compared with the state of the art methods.
Shadows Don't Lie and Lines Can't Bend! Generative Models don't know Projective Geometry...for now
Nov 28, 2023Generative models can produce impressively realistic images. This paper demonstrates that generated images have geometric features different from those of real images. We build a set of collections of generated images, prequalified to fool simple, signal-based classifiers into believing they are real. We then show that prequalified generated images can be identified reliably by classifiers that only look at geometric properties. We use three such classifiers. All three classifiers are denied access to image pixels, and look only at derived geometric features. The first classifier looks at the perspective field of the image, the second looks at lines detected in the image, and the third looks at relations between detected objects and shadows. Our procedure detects generated images more reliably than SOTA local signal based detectors, for images from a number of distinct generators. Saliency maps suggest that the classifiers can identify geometric problems reliably. We conclude that current generators cannot reliably reproduce geometric properties of real images.
THInImg: Cross-modal Steganography for Presenting Talking Heads in Images
Nov 28, 2023Cross-modal Steganography is the practice of concealing secret signals in publicly available cover signals (distinct from the modality of the secret signals) unobtrusively. While previous approaches primarily concentrated on concealing a relatively small amount of information, we propose THInImg, which manages to hide lengthy audio data (and subsequently decode talking head video) inside an identity image by leveraging the properties of human face, which can be effectively utilized for covert communication, transmission and copyright protection. THInImg consists of two parts: the encoder and decoder. Inside the encoder-decoder pipeline, we introduce a novel architecture that substantially increase the capacity of hiding audio in images. Moreover, our framework can be extended to iteratively hide multiple audio clips into an identity image, offering multiple levels of control over permissions. We conduct extensive experiments to prove the effectiveness of our method, demonstrating that THInImg can present up to 80 seconds of high quality talking-head video (including audio) in an identity image with 160x160 resolution.
VINNA for Neonates -- Orientation Independence through Latent Augmentations
Nov 29, 2023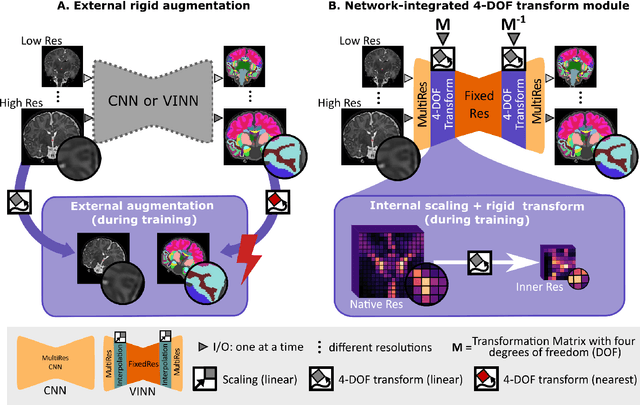
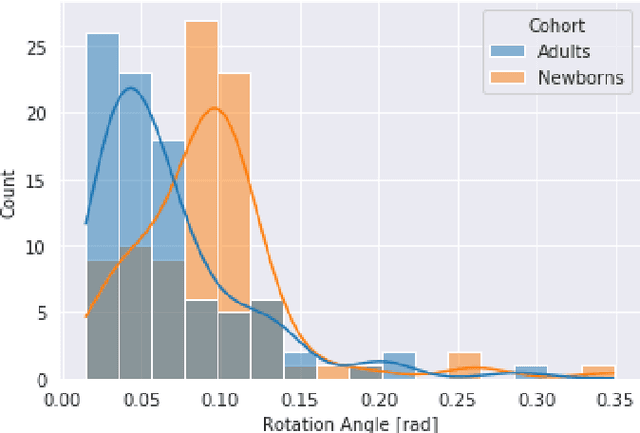
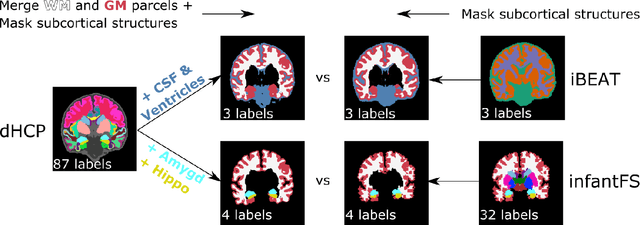
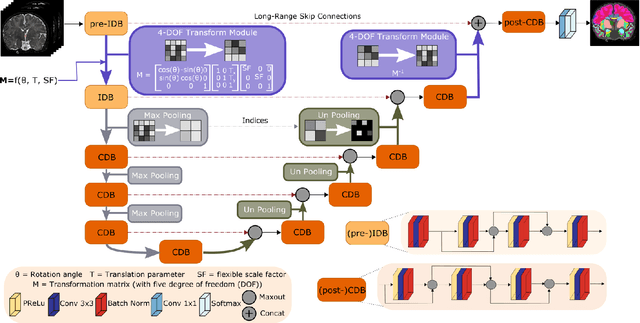
Fast and accurate segmentation of neonatal brain images is highly desired to better understand and detect changes during development and disease. Yet, the limited availability of ground truth datasets, lack of standardized acquisition protocols, and wide variations of head positioning pose challenges for method development. A few automated image analysis pipelines exist for newborn brain MRI segmentation, but they often rely on time-consuming procedures and require resampling to a common resolution, subject to loss of information due to interpolation and down-sampling. Without registration and image resampling, variations with respect to head positions and voxel resolutions have to be addressed differently. In deep-learning, external augmentations are traditionally used to artificially expand the representation of spatial variability, increasing the training dataset size and robustness. However, these transformations in the image space still require resampling, reducing accuracy specifically in the context of label interpolation. We recently introduced the concept of resolution-independence with the Voxel-size Independent Neural Network framework, VINN. Here, we extend this concept by additionally shifting all rigid-transforms into the network architecture with a four degree of freedom (4-DOF) transform module, enabling resolution-aware internal augmentations (VINNA). In this work we show that VINNA (i) significantly outperforms state-of-the-art external augmentation approaches, (ii) effectively addresses the head variations present specifically in newborn datasets, and (iii) retains high segmentation accuracy across a range of resolutions (0.5-1.0 mm). The 4-DOF transform module is a powerful, general approach to implement spatial augmentation without requiring image or label interpolation. The specific network application to newborns will be made publicly available as VINNA4neonates.
HiDiffusion: Unlocking High-Resolution Creativity and Efficiency in Low-Resolution Trained Diffusion Models
Nov 29, 2023We introduce HiDiffusion, a tuning-free framework comprised of Resolution-Aware U-Net (RAU-Net) and Modified Shifted Window Multi-head Self-Attention (MSW-MSA) to enable pretrained large text-to-image diffusion models to efficiently generate high-resolution images (e.g. 1024$\times$1024) that surpass the training image resolution. Pretrained diffusion models encounter unreasonable object duplication in generating images beyond the training image resolution. We attribute it to the mismatch between the feature map size of high-resolution images and the receptive field of U-Net's convolution. To address this issue, we propose a simple yet scalable method named RAU-Net. RAU-Net dynamically adjusts the feature map size to match the convolution's receptive field in the deep block of U-Net. Another obstacle in high-resolution synthesis is the slow inference speed of U-Net. Our observations reveal that the global self-attention in the top block, which exhibits locality, however, consumes the majority of computational resources. To tackle this issue, we propose MSW-MSA. Unlike previous window attention mechanisms, our method uses a much larger window size and dynamically shifts windows to better accommodate diffusion models. Extensive experiments demonstrate that our HiDiffusion can scale diffusion models to generate 1024$\times$1024, 2048$\times$2048, or even 4096$\times$4096 resolution images, while simultaneously reducing inference time by 40\%-60\%, achieving state-of-the-art performance on high-resolution image synthesis. The most significant revelation of our work is that a pretrained diffusion model on low-resolution images is scalable for high-resolution generation without further tuning. We hope this revelation can provide insights for future research on the scalability of diffusion models.