 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
WhisBERT: Multimodal Text-Audio Language Modeling on 100M Words
Dec 07, 2023
Training on multiple modalities of input can augment the capabilities of a language model. Here, we ask whether such a training regime can improve the quality and efficiency of these systems as well. We focus on text--audio and introduce Whisbert, which is inspired by the text--image approach of FLAVA (Singh et al., 2022). In accordance with Babylm guidelines (Warstadt et al., 2023), we pretrain Whisbert on a dataset comprising only 100 million words plus their corresponding speech from the word-aligned version of the People's Speech dataset (Galvez et al., 2021). To assess the impact of multimodality, we compare versions of the model that are trained on text only and on both audio and text simultaneously. We find that while Whisbert is able to perform well on multimodal masked modeling and surpasses the Babylm baselines in most benchmark tasks, it struggles to optimize its complex objective and outperform its text-only Whisbert baseline.
FRNet: Frustum-Range Networks for Scalable LiDAR Segmentation
Dec 07, 2023LiDAR segmentation is crucial for autonomous driving systems. The recent range-view approaches are promising for real-time processing. However, they suffer inevitably from corrupted contextual information and rely heavily on post-processing techniques for prediction refinement. In this work, we propose a simple yet powerful FRNet that restores the contextual information of the range image pixels with corresponding frustum LiDAR points. Firstly, a frustum feature encoder module is used to extract per-point features within the frustum region, which preserves scene consistency and is crucial for point-level predictions. Next, a frustum-point fusion module is introduced to update per-point features hierarchically, which enables each point to extract more surrounding information via the frustum features. Finally, a head fusion module is used to fuse features at different levels for final semantic prediction. Extensive experiments on four popular LiDAR segmentation benchmarks under various task setups demonstrate our superiority. FRNet achieves competitive performance while maintaining high efficiency. The code is publicly available.
Video Face Re-Aging: Toward Temporally Consistent Face Re-Aging
Dec 07, 2023Video face re-aging deals with altering the apparent age of a person to the target age in videos. This problem is challenging due to the lack of paired video datasets maintaining temporal consistency in identity and age. Most re-aging methods process each image individually without considering the temporal consistency of videos. While some existing works address the issue of temporal coherence through video facial attribute manipulation in latent space, they often fail to deliver satisfactory performance in age transformation. To tackle the issues, we propose (1) a novel synthetic video dataset that features subjects across a diverse range of age groups; (2) a baseline architecture designed to validate the effectiveness of our proposed dataset, and (3) the development of three novel metrics tailored explicitly for evaluating the temporal consistency of video re-aging techniques. Our comprehensive experiments on public datasets, such as VFHQ and CelebV-HQ, show that our method outperforms the existing approaches in terms of both age transformation and temporal consistency.
Stronger, Fewer, & Superior: Harnessing Vision Foundation Models for Domain Generalized Semantic Segmentation
Dec 07, 2023In this paper, we first assess and harness various Vision Foundation Models (VFMs) in the context of Domain Generalized Semantic Segmentation (DGSS). Driven by the motivation that Leveraging Stronger pre-trained models and Fewer trainable parameters for Superior generalizability, we introduce a robust fine-tuning approach, namely Rein, to parameter-efficiently harness VFMs for DGSS. Built upon a set of trainable tokens, each linked to distinct instances, Rein precisely refines and forwards the feature maps from each layer to the next layer within the backbone. This process produces diverse refinements for different categories within a single image. With fewer trainable parameters, Rein efficiently fine-tunes VFMs for DGSS tasks, surprisingly surpassing full parameter fine-tuning. Extensive experiments across various settings demonstrate that Rein significantly outperforms state-of-the-art methods. Remarkably, with just an extra 1% of trainable parameters within the frozen backbone, Rein achieves a mIoU of 68.1% on the Cityscapes, without accessing any real urban-scene datasets.
SPIRE-SIES: A Spontaneous Indian English Speech Corpus
Dec 01, 2023In this paper, we present a 170.83 hour Indian English spontaneous speech dataset. Lack of Indian English speech data is one of the major hindrances in developing robust speech systems which are adapted to the Indian speech style. Moreover this scarcity is even more for spontaneous speech. This corpus is crowd sourced over varied Indian nativities, genders and age groups. Traditional spontaneous speech collection strategies involve capturing of speech during interviewing or conversations. In this study, we use images as stimuli to induce spontaneity in speech. Transcripts for 23 hours is generated and validated which can serve as a spontaneous speech ASR benchmark. Quality of the corpus is validated with voice activity detection based segmentation, gender verification and image semantic correlation. Which determines a relationship between image stimulus and recorded speech using caption keywords derived from Image2Text model and high occurring words derived from whisper ASR generated transcripts.
GenDepth: Generalizing Monocular Depth Estimation for Arbitrary Camera Parameters via Ground Plane Embedding
Dec 10, 2023Learning-based monocular depth estimation leverages geometric priors present in the training data to enable metric depth perception from a single image, a traditionally ill-posed problem. However, these priors are often specific to a particular domain, leading to limited generalization performance on unseen data. Apart from the well studied environmental domain gap, monocular depth estimation is also sensitive to the domain gap induced by varying camera parameters, an aspect that is often overlooked in current state-of-the-art approaches. This issue is particularly evident in autonomous driving scenarios, where datasets are typically collected with a single vehicle-camera setup, leading to a bias in the training data due to a fixed perspective geometry. In this paper, we challenge this trend and introduce GenDepth, a novel model capable of performing metric depth estimation for arbitrary vehicle-camera setups. To address the lack of data with sufficiently diverse camera parameters, we first create a bespoke synthetic dataset collected with different vehicle-camera systems. Then, we design GenDepth to simultaneously optimize two objectives: (i) equivariance to the camera parameter variations on synthetic data, (ii) transferring the learned equivariance to real-world environmental features using a single real-world dataset with a fixed vehicle-camera system. To achieve this, we propose a novel embedding of camera parameters as the ground plane depth and present a novel architecture that integrates these embeddings with adversarial domain alignment. We validate GenDepth on several autonomous driving datasets, demonstrating its state-of-the-art generalization capability for different vehicle-camera systems.
DREAM: Diffusion Rectification and Estimation-Adaptive Models
Nov 30, 2023We present DREAM, a novel training framework representing Diffusion Rectification and Estimation-Adaptive Models, requiring minimal code changes (just three lines) yet significantly enhancing the alignment of training with sampling in diffusion models. DREAM features two components: diffusion rectification, which adjusts training to reflect the sampling process, and estimation adaptation, which balances perception against distortion. When applied to image super-resolution (SR), DREAM adeptly navigates the tradeoff between minimizing distortion and preserving high image quality. Experiments demonstrate DREAM's superiority over standard diffusion-based SR methods, showing a $2$ to $3\times $ faster training convergence and a $10$ to $20\times$ reduction in necessary sampling steps to achieve comparable or superior results. We hope DREAM will inspire a rethinking of diffusion model training paradigms.
Anatomy and Physiology of Artificial Intelligence in PET Imaging
Nov 30, 2023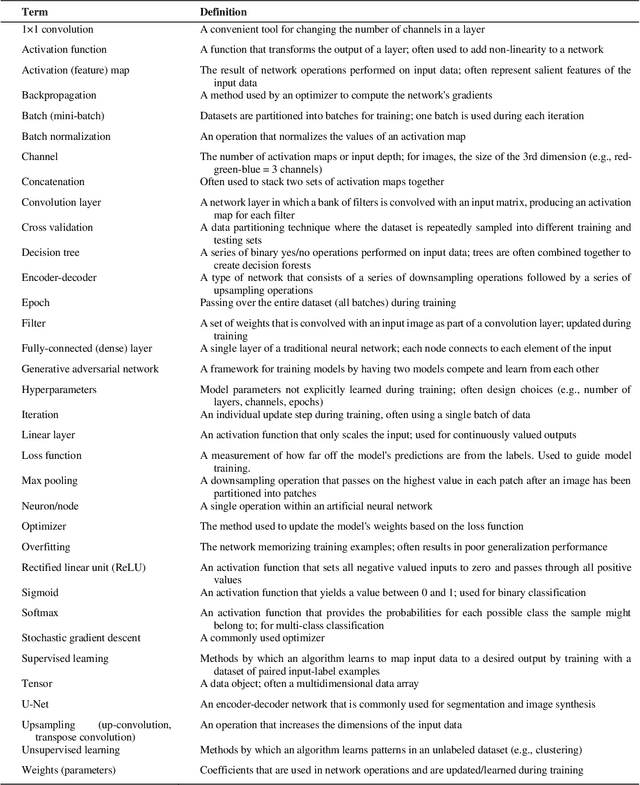
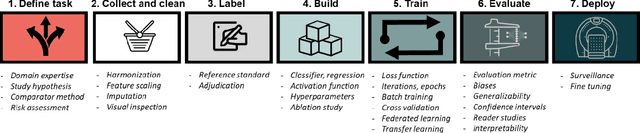
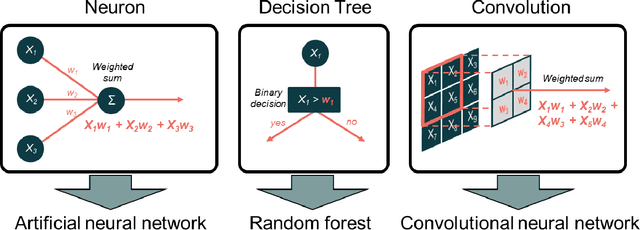
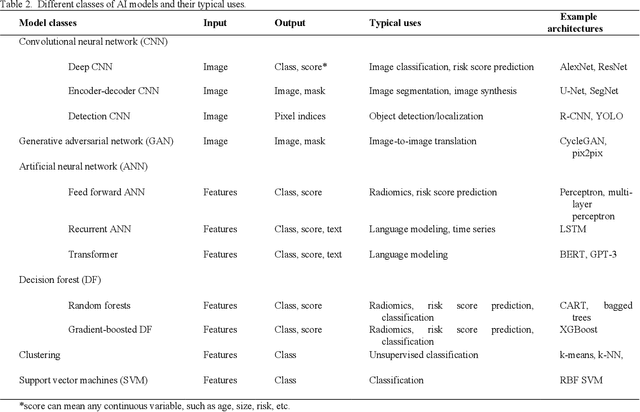
The influence of artificial intelligence (AI) within the field of nuclear medicine has been rapidly growing. Many researchers and clinicians are seeking to apply AI within PET, and clinicians will soon find themselves engaging with AI-based applications all along the chain of molecular imaging, from image reconstruction to enhanced reporting. This expanding presence of AI in PET imaging will result in greater demand for educational resources for those unfamiliar with AI. The objective of this article to is provide an illustrated guide to the core principles of modern AI, with specific focus on aspects that are most likely to be encountered in PET imaging. We describe convolutional neural networks, algorithm training, and explain the components of the commonly used U-Net for segmentation and image synthesis.
Visible to Thermal image Translation for improving visual task in low light conditions
Oct 31, 2023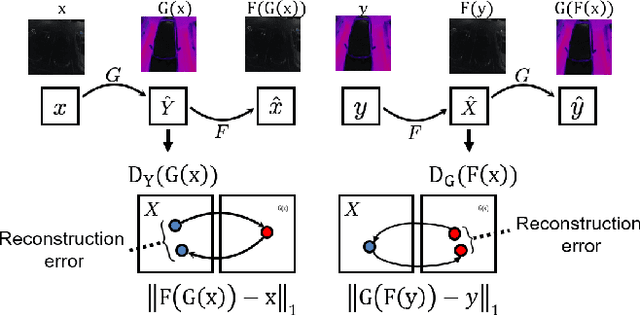
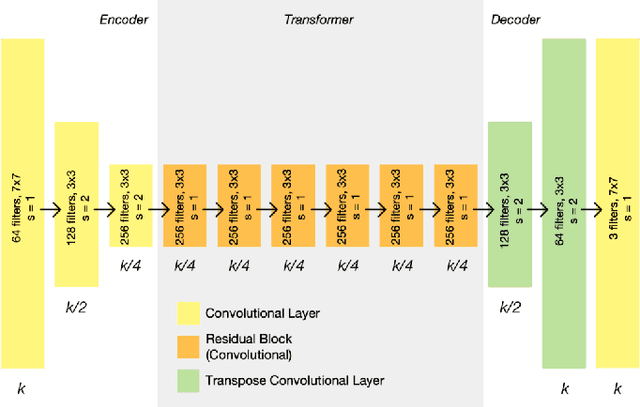
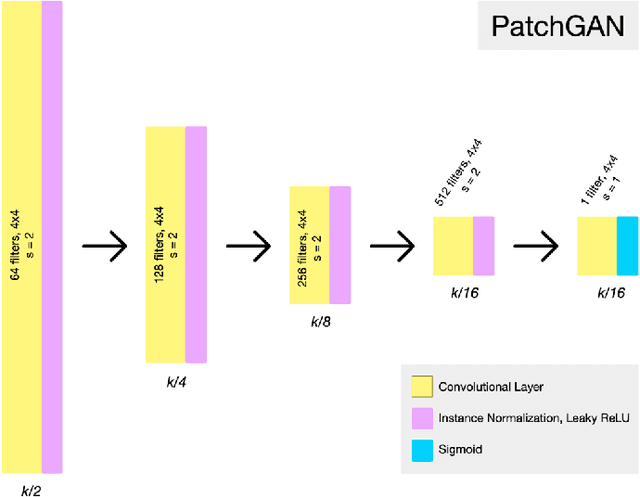
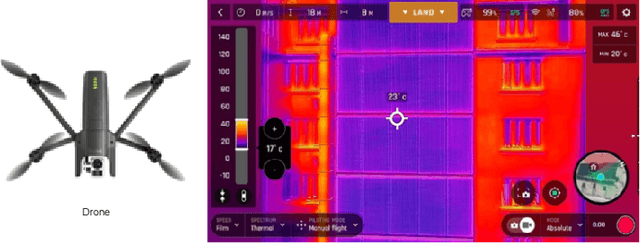
Several visual tasks, such as pedestrian detection and image-to-image translation, are challenging to accomplish in low light using RGB images. Heat variation of objects in thermal images can be used to overcome this. In this work, an end-to-end framework, which consists of a generative network and a detector network, is proposed to translate RGB image into Thermal ones and compare generated thermal images with real data. We have collected images from two different locations using the Parrot Anafi Thermal drone. After that, we created a two-stream network, preprocessed, augmented, the image data, and trained the generator and discriminator models from scratch. The findings demonstrate that it is feasible to translate RGB training data to thermal data using GAN. As a result, thermal data can now be produced more quickly and affordably, which is useful for security and surveillance applications.
A Unified Multi-Phase CT Synthesis and Classification Framework for Kidney Cancer Diagnosis with Incomplete Data
Dec 09, 2023Multi-phase CT is widely adopted for the diagnosis of kidney cancer due to the complementary information among phases. However, the complete set of multi-phase CT is often not available in practical clinical applications. In recent years, there have been some studies to generate the missing modality image from the available data. Nevertheless, the generated images are not guaranteed to be effective for the diagnosis task. In this paper, we propose a unified framework for kidney cancer diagnosis with incomplete multi-phase CT, which simultaneously recovers missing CT images and classifies cancer subtypes using the completed set of images. The advantage of our framework is that it encourages a synthesis model to explicitly learn to generate missing CT phases that are helpful for classifying cancer subtypes. We further incorporate lesion segmentation network into our framework to exploit lesion-level features for effective cancer classification in the whole CT volumes. The proposed framework is based on fully 3D convolutional neural networks to jointly optimize both synthesis and classification of 3D CT volumes. Extensive experiments on both in-house and external datasets demonstrate the effectiveness of our framework for the diagnosis with incomplete data compared with state-of-the-art baselines. In particular, cancer subtype classification using the completed CT data by our method achieves higher performance than the classification using the given incomplete data.
* This article has been accepted for publication in IEEE Journal of Biomedical and Health Informatics