 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SHAP-EDITOR: Instruction-guided Latent 3D Editing in Seconds
Dec 14, 2023
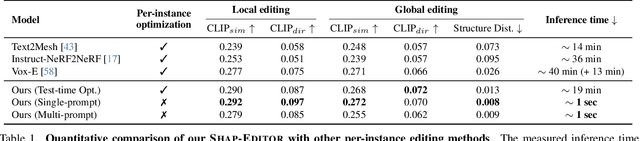
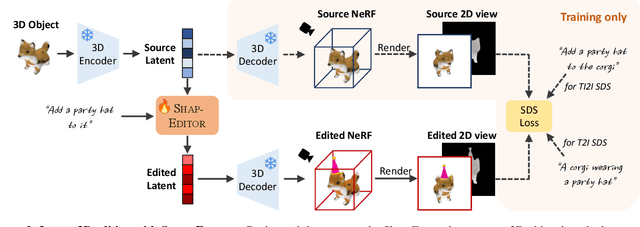
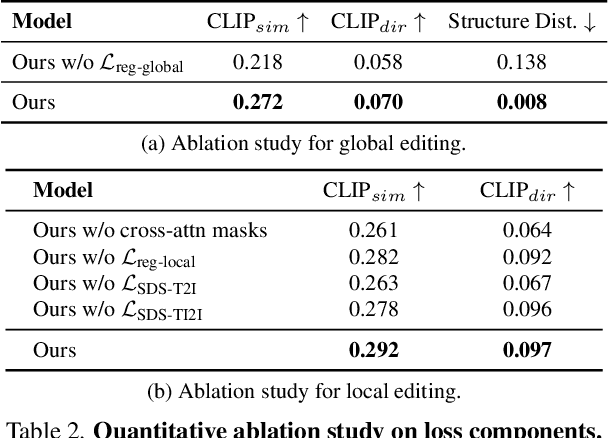

We propose a novel feed-forward 3D editing framework called Shap-Editor. Prior research on editing 3D objects primarily concentrated on editing individual objects by leveraging off-the-shelf 2D image editing networks. This is achieved via a process called distillation, which transfers knowledge from the 2D network to 3D assets. Distillation necessitates at least tens of minutes per asset to attain satisfactory editing results, and is thus not very practical. In contrast, we ask whether 3D editing can be carried out directly by a feed-forward network, eschewing test-time optimisation. In particular, we hypothesise that editing can be greatly simplified by first encoding 3D objects in a suitable latent space. We validate this hypothesis by building upon the latent space of Shap-E. We demonstrate that direct 3D editing in this space is possible and efficient by building a feed-forward editor network that only requires approximately one second per edit. Our experiments show that Shap-Editor generalises well to both in-distribution and out-of-distribution 3D assets with different prompts, exhibiting comparable performance with methods that carry out test-time optimisation for each edited instance.
Pixel Aligned Language Models
Dec 14, 2023Large language models have achieved great success in recent years, so as their variants in vision. Existing vision-language models can describe images in natural languages, answer visual-related questions, or perform complex reasoning about the image. However, it is yet unclear how localization tasks, such as word grounding or referring localization, can be performed using large language models. In this work, we aim to develop a vision-language model that can take locations, for example, a set of points or boxes, as either inputs or outputs. When taking locations as inputs, the model performs location-conditioned captioning, which generates captions for the indicated object or region. When generating locations as outputs, our model regresses pixel coordinates for each output word generated by the language model, and thus performs dense word grounding. Our model is pre-trained on the Localized Narrative dataset, which contains pixel-word-aligned captioning from human attention. We show our model can be applied to various location-aware vision-language tasks, including referring localization, location-conditioned captioning, and dense object captioning, archiving state-of-the-art performance on RefCOCO and Visual Genome. Project page: https://jerryxu.net/PixelLLM .
Learning Long Sequences in Spiking Neural Networks
Dec 14, 2023Spiking neural networks (SNNs) take inspiration from the brain to enable energy-efficient computations. Since the advent of Transformers, SNNs have struggled to compete with artificial networks on modern sequential tasks, as they inherit limitations from recurrent neural networks (RNNs), with the added challenge of training with non-differentiable binary spiking activations. However, a recent renewed interest in efficient alternatives to Transformers has given rise to state-of-the-art recurrent architectures named state space models (SSMs). This work systematically investigates, for the first time, the intersection of state-of-the-art SSMs with SNNs for long-range sequence modelling. Results suggest that SSM-based SNNs can outperform the Transformer on all tasks of a well-established long-range sequence modelling benchmark. It is also shown that SSM-based SNNs can outperform current state-of-the-art SNNs with fewer parameters on sequential image classification. Finally, a novel feature mixing layer is introduced, improving SNN accuracy while challenging assumptions about the role of binary activations in SNNs. This work paves the way for deploying powerful SSM-based architectures, such as large language models, to neuromorphic hardware for energy-efficient long-range sequence modelling.
CL2CM: Improving Cross-Lingual Cross-Modal Retrieval via Cross-Lingual Knowledge Transfer
Dec 14, 2023Cross-lingual cross-modal retrieval has garnered increasing attention recently, which aims to achieve the alignment between vision and target language (V-T) without using any annotated V-T data pairs. Current methods employ machine translation (MT) to construct pseudo-parallel data pairs, which are then used to learn a multi-lingual and multi-modal embedding space that aligns visual and target-language representations. However, the large heterogeneous gap between vision and text, along with the noise present in target language translations, poses significant challenges in effectively aligning their representations. To address these challenges, we propose a general framework, Cross-Lingual to Cross-Modal (CL2CM), which improves the alignment between vision and target language using cross-lingual transfer. This approach allows us to fully leverage the merits of multi-lingual pre-trained models (e.g., mBERT) and the benefits of the same modality structure, i.e., smaller gap, to provide reliable and comprehensive semantic correspondence (knowledge) for the cross-modal network. We evaluate our proposed approach on two multilingual image-text datasets, Multi30K and MSCOCO, and one video-text dataset, VATEX. The results clearly demonstrate the effectiveness of our proposed method and its high potential for large-scale retrieval.
HeadRecon: High-Fidelity 3D Head Reconstruction from Monocular Video
Dec 14, 2023Recently, the reconstruction of high-fidelity 3D head models from static portrait image has made great progress. However, most methods require multi-view or multi-illumination information, which therefore put forward high requirements for data acquisition. In this paper, we study the reconstruction of high-fidelity 3D head models from arbitrary monocular videos. Non-rigid structure from motion (NRSFM) methods have been widely used to solve such problems according to the two-dimensional correspondence between different frames. However, the inaccurate correspondence caused by high-complex hair structures and various facial expression changes would heavily influence the reconstruction accuracy. To tackle these problems, we propose a prior-guided dynamic implicit neural network. Specifically, we design a two-part dynamic deformation field to transform the current frame space to the canonical one. We further model the head geometry in the canonical space with a learnable signed distance field (SDF) and optimize it using the volumetric rendering with the guidance of two-main head priors to improve the reconstruction accuracy and robustness. Extensive ablation studies and comparisons with state-of-the-art methods demonstrate the effectiveness and robustness of our proposed method.
GOEnFusion: Gradient Origin Encodings for 3D Forward Diffusion Models
Dec 14, 2023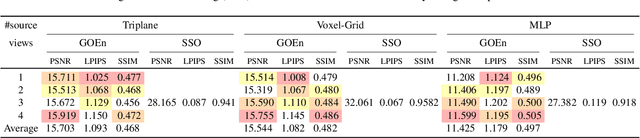
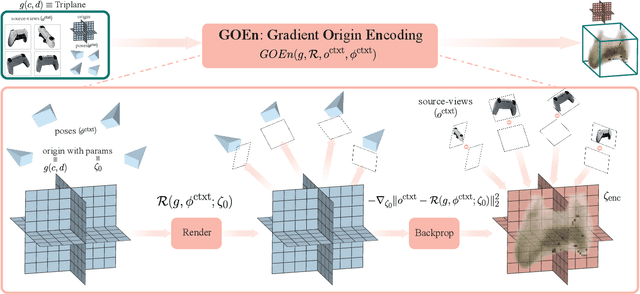
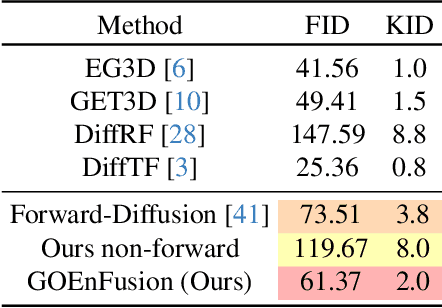
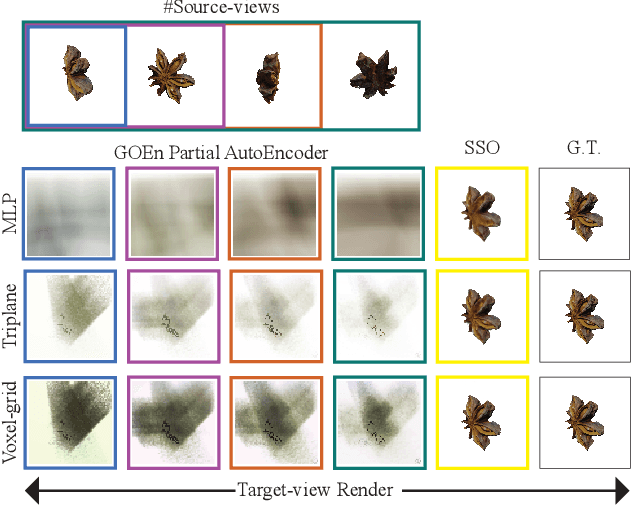
The recently introduced Forward-Diffusion method allows to train a 3D diffusion model using only 2D images for supervision. However, it does not easily generalise to different 3D representations and requires a computationally expensive auto-regressive sampling process to generate the underlying 3D scenes. In this paper, we propose GOEn: Gradient Origin Encoding (pronounced "gone"). GOEn can encode input images into any type of 3D representation without the need to use a pre-trained image feature extractor. It can also handle single, multiple or no source view(s) alike, by design, and tries to maximise the information transfer from the views to the encodings. Our proposed GOEnFusion model pairs GOEn encodings with a realisation of the Forward-Diffusion model which addresses the limitations of the vanilla Forward-Diffusion realisation. We evaluate how much information the GOEn mechanism transfers to the encoded representations, and how well it captures the prior distribution over the underlying 3D scenes, through the lens of a partial AutoEncoder. Lastly, the efficacy of the GOEnFusion model is evaluated on the recently proposed OmniObject3D dataset while comparing to the state-of-the-art Forward and non-Forward-Diffusion models and other 3D generative models.
WarpDiffusion: Efficient Diffusion Model for High-Fidelity Virtual Try-on
Dec 06, 2023
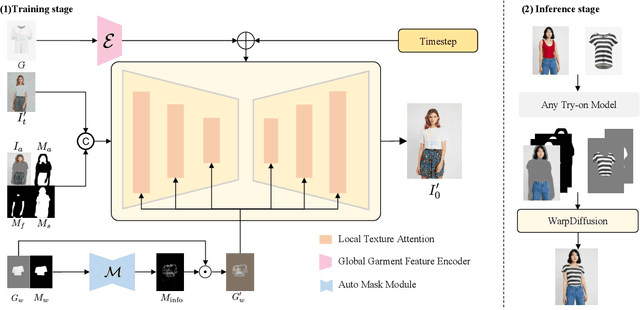
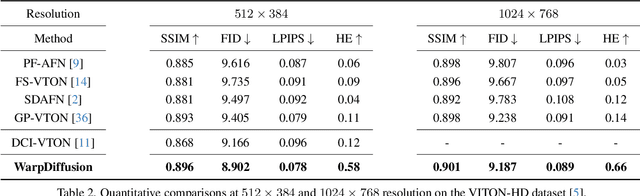
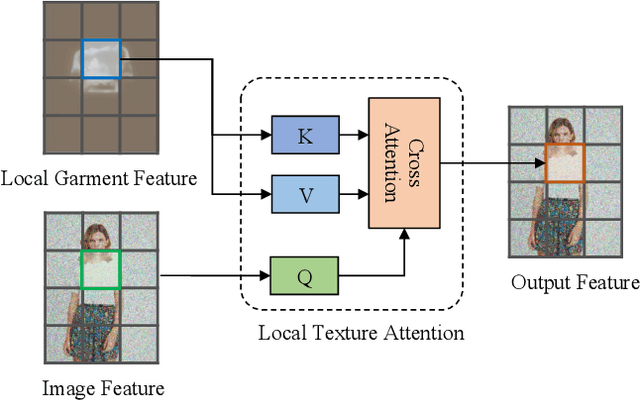
Image-based Virtual Try-On (VITON) aims to transfer an in-shop garment image onto a target person. While existing methods focus on warping the garment to fit the body pose, they often overlook the synthesis quality around the garment-skin boundary and realistic effects like wrinkles and shadows on the warped garments. These limitations greatly reduce the realism of the generated results and hinder the practical application of VITON techniques. Leveraging the notable success of diffusion-based models in cross-modal image synthesis, some recent diffusion-based methods have ventured to tackle this issue. However, they tend to either consume a significant amount of training resources or struggle to achieve realistic try-on effects and retain garment details. For efficient and high-fidelity VITON, we propose WarpDiffusion, which bridges the warping-based and diffusion-based paradigms via a novel informative and local garment feature attention mechanism. Specifically, WarpDiffusion incorporates local texture attention to reduce resource consumption and uses a novel auto-mask module that effectively retains only the critical areas of the warped garment while disregarding unrealistic or erroneous portions. Notably, WarpDiffusion can be integrated as a plug-and-play component into existing VITON methodologies, elevating their synthesis quality. Extensive experiments on high-resolution VITON benchmarks and an in-the-wild test set demonstrate the superiority of WarpDiffusion, surpassing state-of-the-art methods both qualitatively and quantitatively.
The Journey, Not the Destination: How Data Guides Diffusion Models
Dec 11, 2023Diffusion models trained on large datasets can synthesize photo-realistic images of remarkable quality and diversity. However, attributing these images back to the training data-that is, identifying specific training examples which caused an image to be generated-remains a challenge. In this paper, we propose a framework that: (i) provides a formal notion of data attribution in the context of diffusion models, and (ii) allows us to counterfactually validate such attributions. Then, we provide a method for computing these attributions efficiently. Finally, we apply our method to find (and evaluate) such attributions for denoising diffusion probabilistic models trained on CIFAR-10 and latent diffusion models trained on MS COCO. We provide code at https://github.com/MadryLab/journey-TRAK .
Label Smoothing for Enhanced Text Sentiment Classification
Dec 11, 2023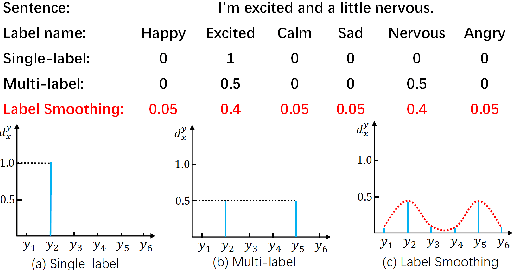

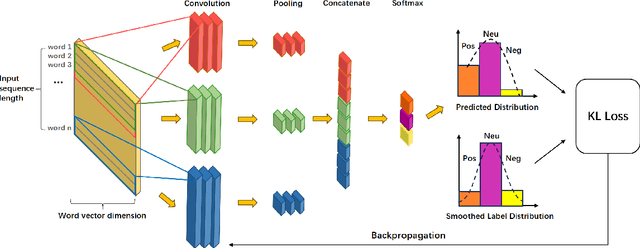
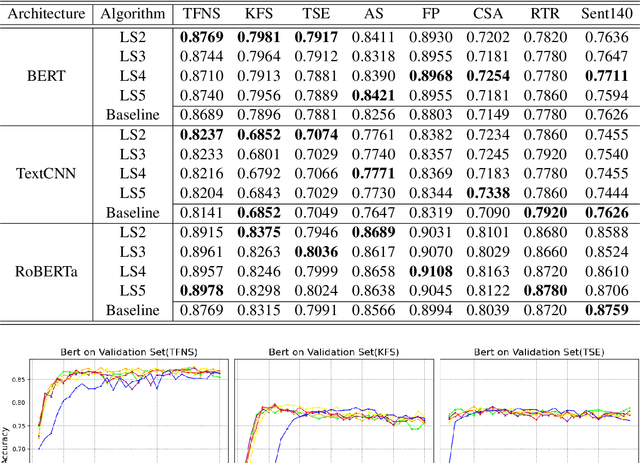
Label smoothing is a widely used technique in various domains, such as image classification and speech recognition, known for effectively combating model overfitting. However, there is few research on its application to text sentiment classification. To fill in the gap, this study investigates the implementation of label smoothing for sentiment classification by utilizing different levels of smoothing. The primary objective is to enhance sentiment classification accuracy by transforming discrete labels into smoothed label distributions. Through extensive experiments, we demonstrate the superior performance of label smoothing in text sentiment classification tasks across eight diverse datasets and deep learning architectures: TextCNN, BERT, and RoBERTa, under two learning schemes: training from scratch and fine-tuning.
An Empirical Investigation into Benchmarking Model Multiplicity for Trustworthy Machine Learning: A Case Study on Image Classification
Nov 24, 2023Deep learning models have proven to be highly successful. Yet, their over-parameterization gives rise to model multiplicity, a phenomenon in which multiple models achieve similar performance but exhibit distinct underlying behaviours. This multiplicity presents a significant challenge and necessitates additional specifications in model selection to prevent unexpected failures during deployment. While prior studies have examined these concerns, they focus on individual metrics in isolation, making it difficult to obtain a comprehensive view of multiplicity in trustworthy machine learning. Our work stands out by offering a one-stop empirical benchmark of multiplicity across various dimensions of model design and its impact on a diverse set of trustworthy metrics. In this work, we establish a consistent language for studying model multiplicity by translating several trustworthy metrics into accuracy under appropriate interventions. We also develop a framework, which we call multiplicity sheets, to benchmark multiplicity in various scenarios. We demonstrate the advantages of our setup through a case study in image classification and provide actionable insights into the impact and trends of different hyperparameters on model multiplicity. Finally, we show that multiplicity persists in deep learning models even after enforcing additional specifications during model selection, highlighting the severity of over-parameterization. The concerns of under-specification thus remain, and we seek to promote a more comprehensive discussion of multiplicity in trustworthy machine learning.