 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
UFineBench: Towards Text-based Person Retrieval with Ultra-fine Granularity
Dec 11, 2023
Existing text-based person retrieval datasets often have relatively coarse-grained text annotations. This hinders the model to comprehend the fine-grained semantics of query texts in real scenarios. To address this problem, we contribute a new benchmark named \textbf{UFineBench} for text-based person retrieval with ultra-fine granularity. Firstly, we construct a new \textbf{dataset} named UFine6926. We collect a large number of person images and manually annotate each image with two detailed textual descriptions, averaging 80.8 words each. The average word count is three to four times that of the previous datasets. In addition of standard in-domain evaluation, we also propose a special \textbf{evaluation paradigm} more representative of real scenarios. It contains a new evaluation set with cross domains, cross textual granularity and cross textual styles, named UFine3C, and a new evaluation metric for accurately measuring retrieval ability, named mean Similarity Distribution (mSD). Moreover, we propose CFAM, a more efficient \textbf{algorithm} especially designed for text-based person retrieval with ultra fine-grained texts. It achieves fine granularity mining by adopting a shared cross-modal granularity decoder and hard negative match mechanism. With standard in-domain evaluation, CFAM establishes competitive performance across various datasets, especially on our ultra fine-grained UFine6926. Furthermore, by evaluating on UFine3C, we demonstrate that training on our UFine6926 significantly improves generalization to real scenarios compared with other coarse-grained datasets. The dataset and code will be made publicly available at \url{https://github.com/Zplusdragon/UFineBench}.
TMSR: Tiny Multi-path CNNs for Super Resolution
Dec 04, 2023In this paper, we proposed a tiny multi-path CNN-based Super-Resolution (SR) method, called TMSR. We mainly refer to some tiny CNN-based SR methods, under 5k parameters. The main contribution of the proposed method is the improved multi-path learning and self-defined activated function. The experimental results show that TMSR obtains competitive image quality (i.e. PSNR and SSIM) compared to the related works under 5k parameters.
A Representative Study on Human Detection of Artificially Generated Media Across Countries
Dec 10, 2023AI-generated media has become a threat to our digital society as we know it. These forgeries can be created automatically and on a large scale based on publicly available technology. Recognizing this challenge, academics and practitioners have proposed a multitude of automatic detection strategies to detect such artificial media. However, in contrast to these technical advances, the human perception of generated media has not been thoroughly studied yet. In this paper, we aim at closing this research gap. We perform the first comprehensive survey into people's ability to detect generated media, spanning three countries (USA, Germany, and China) with 3,002 participants across audio, image, and text media. Our results indicate that state-of-the-art forgeries are almost indistinguishable from "real" media, with the majority of participants simply guessing when asked to rate them as human- or machine-generated. In addition, AI-generated media receive is voted more human like across all media types and all countries. To further understand which factors influence people's ability to detect generated media, we include personal variables, chosen based on a literature review in the domains of deepfake and fake news research. In a regression analysis, we found that generalized trust, cognitive reflection, and self-reported familiarity with deepfakes significantly influence participant's decision across all media categories.
InvertAvatar: Incremental GAN Inversion for Generalized Head Avatars
Dec 03, 2023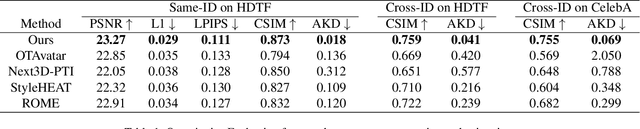
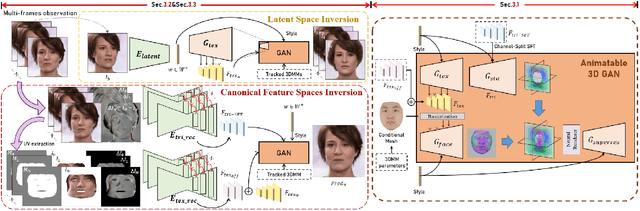


While high fidelity and efficiency are central to the creation of digital head avatars, recent methods relying on 2D or 3D generative models often experience limitations such as shape distortion, expression inaccuracy, and identity flickering. Additionally, existing one-shot inversion techniques fail to fully leverage multiple input images for detailed feature extraction. We propose a novel framework, \textbf{Incremental 3D GAN Inversion}, that enhances avatar reconstruction performance using an algorithm designed to increase the fidelity from multiple frames, resulting in improved reconstruction quality proportional to frame count. Our method introduces a unique animatable 3D GAN prior with two crucial modifications for enhanced expression controllability alongside an innovative neural texture encoder that categorizes texture feature spaces based on UV parameterization. Differentiating from traditional techniques, our architecture emphasizes pixel-aligned image-to-image translation, mitigating the need to learn correspondences between observation and canonical spaces. Furthermore, we incorporate ConvGRU-based recurrent networks for temporal data aggregation from multiple frames, boosting geometry and texture detail reconstruction. The proposed paradigm demonstrates state-of-the-art performance on one-shot and few-shot avatar animation tasks.
Portrait Diffusion: Training-free Face Stylization with Chain-of-Painting
Dec 03, 2023Face stylization refers to the transformation of a face into a specific portrait style. However, current methods require the use of example-based adaptation approaches to fine-tune pre-trained generative models so that they demand lots of time and storage space and fail to achieve detailed style transformation. This paper proposes a training-free face stylization framework, named Portrait Diffusion. This framework leverages off-the-shelf text-to-image diffusion models, eliminating the need for fine-tuning specific examples. Specifically, the content and style images are first inverted into latent codes. Then, during image reconstruction using the corresponding latent code, the content and style features in the attention space are delicately blended through a modified self-attention operation called Style Attention Control. Additionally, a Chain-of-Painting method is proposed for the gradual redrawing of unsatisfactory areas from rough adjustments to fine-tuning. Extensive experiments validate the effectiveness of our Portrait Diffusion method and demonstrate the superiority of Chain-of-Painting in achieving precise face stylization. Code will be released at \url{https://github.com/liujin112/PortraitDiffusion}.
Improving In-Context Learning in Diffusion Models with Visual Context-Modulated Prompts
Dec 03, 2023In light of the remarkable success of in-context learning in large language models, its potential extension to the vision domain, particularly with visual foundation models like Stable Diffusion, has sparked considerable interest. Existing approaches in visual in-context learning frequently face hurdles such as expensive pretraining, limiting frameworks, inadequate visual comprehension, and limited adaptability to new tasks. In response to these challenges, we introduce improved Prompt Diffusion (iPromptDiff) in this study. iPromptDiff integrates an end-to-end trained vision encoder that converts visual context into an embedding vector. This vector is subsequently used to modulate the token embeddings of text prompts. We show that a diffusion-based vision foundation model, when equipped with this visual context-modulated text guidance and a standard ControlNet structure, exhibits versatility and robustness across a variety of training tasks and excels in in-context learning for novel vision tasks, such as normal-to-image or image-to-line transformations. The effectiveness of these capabilities relies heavily on a deep visual understanding, which is achieved through relevant visual demonstrations processed by our proposed in-context learning architecture.
Stacked Autoencoder Based Feature Extraction and Superpixel Generation for Multifrequency PolSAR Image Classification
Nov 06, 2023In this paper we are proposing classification algorithm for multifrequency Polarimetric Synthetic Aperture Radar (PolSAR) image. Using PolSAR decomposition algorithms 33 features are extracted from each frequency band of the given image. Then, a two-layer autoencoder is used to reduce the dimensionality of input feature vector while retaining useful features of the input. This reduced dimensional feature vector is then applied to generate superpixels using simple linear iterative clustering (SLIC) algorithm. Next, a robust feature representation is constructed using both pixel as well as superpixel information. Finally, softmax classifier is used to perform classification task. The advantage of using superpixels is that it preserves spatial information between neighbouring PolSAR pixels and therefore minimises the effect of speckle noise during classification. Experiments have been conducted on Flevoland dataset and the proposed method was found to be superior to other methods available in the literature.
MagicStick: Controllable Video Editing via Control Handle Transformations
Dec 05, 2023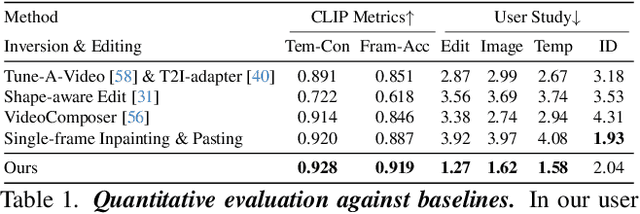
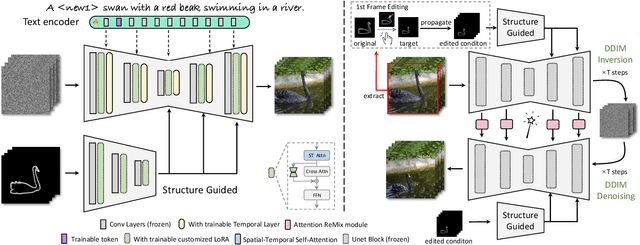
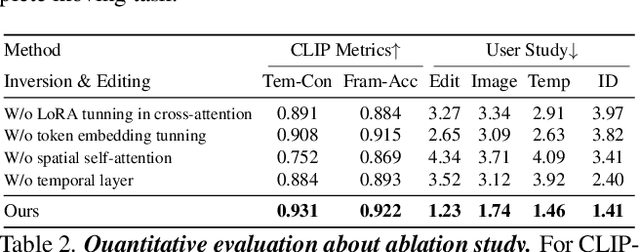
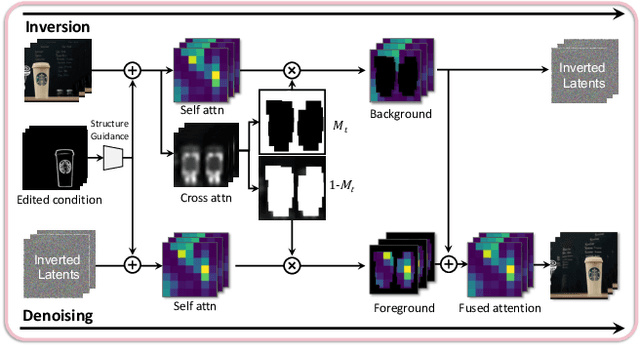
Text-based video editing has recently attracted considerable interest in changing the style or replacing the objects with a similar structure. Beyond this, we demonstrate that properties such as shape, size, location, motion, etc., can also be edited in videos. Our key insight is that the keyframe transformations of the specific internal feature (e.g., edge maps of objects or human pose), can easily propagate to other frames to provide generation guidance. We thus propose MagicStick, a controllable video editing method that edits the video properties by utilizing the transformation on the extracted internal control signals. In detail, to keep the appearance, we inflate both the pretrained image diffusion model and ControlNet to the temporal dimension and train low-rank adaptions (LORA) layers to fit the specific scenes. Then, in editing, we perform an inversion and editing framework. Differently, finetuned ControlNet is introduced in both inversion and generation for attention guidance with the proposed attention remix between the spatial attention maps of inversion and editing. Yet succinct, our method is the first method to show the ability of video property editing from the pre-trained text-to-image model. We present experiments on numerous examples within our unified framework. We also compare with shape-aware text-based editing and handcrafted motion video generation, demonstrating our superior temporal consistency and editing capability than previous works. The code and models will be made publicly available.
Double Integral Enhanced Zeroing Neural Network Optimized with ALSOA fostered Lung Cancer Classification using CT Images
Dec 05, 2023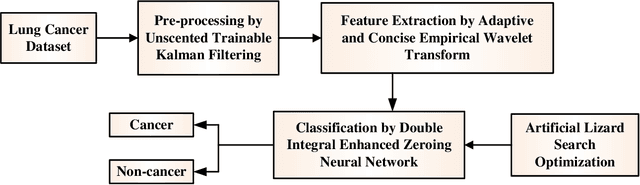
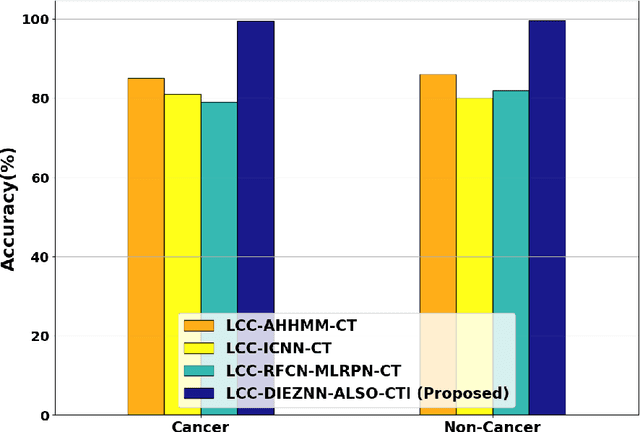
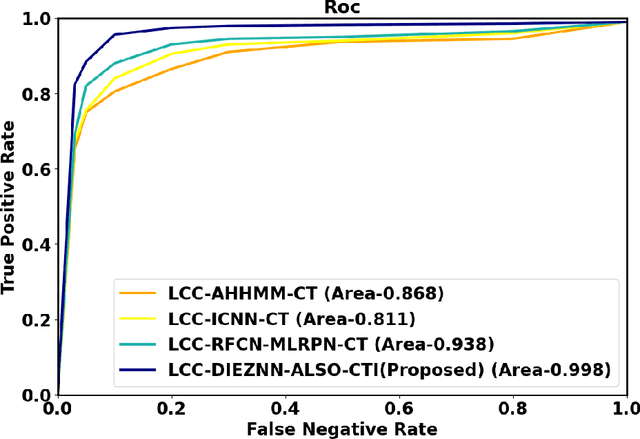
Lung cancer is one of the deadliest diseases and the leading cause of illness and death. Since lung cancer cannot predicted at premature stage, it able to only be discovered more broadly once it has spread to other lung parts. The risk grows when radiologists and other specialists determine whether lung cancer is current. Owing to significance of determining type of treatment and its depth based on severity of the illness, critical to develop smart and automatic cancer prediction scheme is precise, at which stage of cancer. In this paper, Double Integral Enhanced Zeroing Neural Network Optimized with ALSOA fostered Lung Cancer Classification using CT Images (LCC-DIEZNN-ALSO-CTI) is proposed. Initially, input CT image is amassed from lung cancer dataset. The input CT image is pre-processing via Unscented Trainable Kalman Filtering (UTKF) technique. In pre-processing stage unwanted noise are removed from CT images. Afterwards, grayscale statistic features and Haralick texture features extracted by Adaptive and Concise Empirical Wavelet Transform (ACEWT). The proposed model is implemented on MATLAB. The performance of the proposed method is analyzed through existing techniques. The proposed method attains 18.32%, 27.20%, and 34.32% higher accuracy analyzed with existing method likes Deep Learning Assisted Predict of Lung Cancer on Computed Tomography Images Utilizing AHHMM (LCC-AHHMM-CT), Convolutional neural networks based pulmonary nodule malignancy assessment in pipeline for classifying lung cancer (LCC-ICNN-CT), Automated Decision Support Scheme for Lung Cancer Identification with Categorization (LCC-RFCN-MLRPN-CT) methods respectively.
X-Adapter: Adding Universal Compatibility of Plugins for Upgraded Diffusion Model
Dec 04, 2023We introduce X-Adapter, a universal upgrader to enable the pretrained plug-and-play modules (e.g., ControlNet, LoRA) to work directly with the upgraded text-to-image diffusion model (e.g., SDXL) without further retraining. We achieve this goal by training an additional network to control the frozen upgraded model with the new text-image data pairs. In detail, X-Adapter keeps a frozen copy of the old model to preserve the connectors of different plugins. Additionally, X-Adapter adds trainable mapping layers that bridge the decoders from models of different versions for feature remapping. The remapped features will be used as guidance for the upgraded model. To enhance the guidance ability of X-Adapter, we employ a null-text training strategy for the upgraded model. After training, we also introduce a two-stage denoising strategy to align the initial latents of X-Adapter and the upgraded model. Thanks to our strategies, X-Adapter demonstrates universal compatibility with various plugins and also enables plugins of different versions to work together, thereby expanding the functionalities of diffusion community. To verify the effectiveness of the proposed method, we conduct extensive experiments and the results show that X-Adapter may facilitate wider application in the upgraded foundational diffusion model.