 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
OccNeRF: Self-Supervised Multi-Camera Occupancy Prediction with Neural Radiance Fields
Dec 14, 2023
As a fundamental task of vision-based perception, 3D occupancy prediction reconstructs 3D structures of surrounding environments. It provides detailed information for autonomous driving planning and navigation. However, most existing methods heavily rely on the LiDAR point clouds to generate occupancy ground truth, which is not available in the vision-based system. In this paper, we propose an OccNeRF method for self-supervised multi-camera occupancy prediction. Different from bounded 3D occupancy labels, we need to consider unbounded scenes with raw image supervision. To solve the issue, we parameterize the reconstructed occupancy fields and reorganize the sampling strategy. The neural rendering is adopted to convert occupancy fields to multi-camera depth maps, supervised by multi-frame photometric consistency. Moreover, for semantic occupancy prediction, we design several strategies to polish the prompts and filter the outputs of a pretrained open-vocabulary 2D segmentation model. Extensive experiments for both self-supervised depth estimation and semantic occupancy prediction tasks on nuScenes dataset demonstrate the effectiveness of our method.
Stronger, Fewer, & Superior: Harnessing Vision Foundation Models for Domain Generalized Semantic Segmentation
Dec 14, 2023In this paper, we first assess and harness various Vision Foundation Models (VFMs) in the context of Domain Generalized Semantic Segmentation (DGSS). Driven by the motivation that Leveraging Stronger pre-trained models and Fewer trainable parameters for Superior generalizability, we introduce a robust fine-tuning approach, namely Rein, to parameter-efficiently harness VFMs for DGSS. Built upon a set of trainable tokens, each linked to distinct instances, Rein precisely refines and forwards the feature maps from each layer to the next layer within the backbone. This process produces diverse refinements for different categories within a single image. With fewer trainable parameters, Rein efficiently fine-tunes VFMs for DGSS tasks, surprisingly surpassing full parameter fine-tuning. Extensive experiments across various settings demonstrate that Rein significantly outperforms state-of-the-art methods. Remarkably, with just an extra 1% of trainable parameters within the frozen backbone, Rein achieves a mIoU of 68.1% on the Cityscapes, without accessing any real urban-scene datasets.Code is available at https://github.com/w1oves/Rein.git.
Scene 3-D Reconstruction System in Scattering Medium
Dec 14, 2023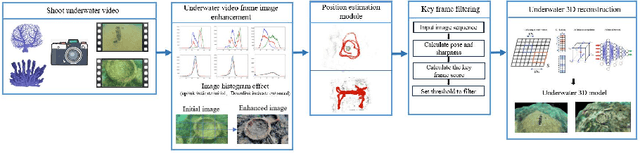
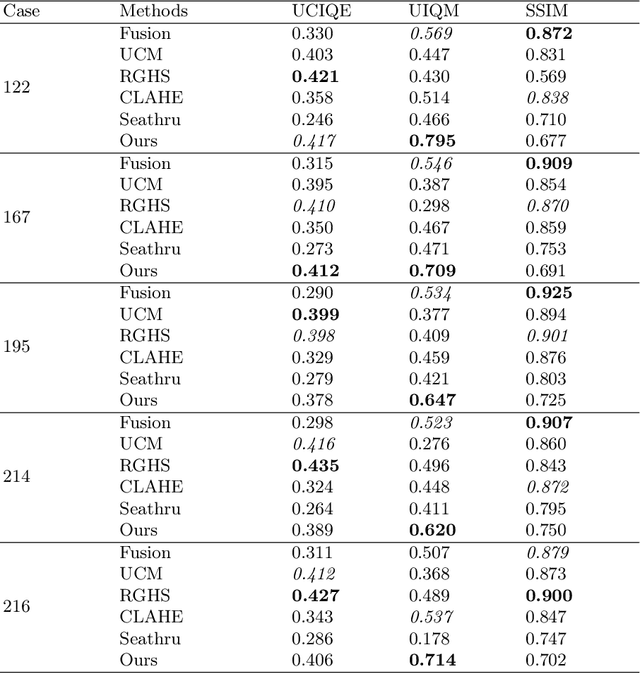


The research on neural radiance fields for new view synthesis has experienced explosive growth with the development of new models and extensions. The NERF algorithm, suitable for underwater scenes or scattering media, is also evolving. Existing underwater 3D reconstruction systems still face challenges such as extensive training time and low rendering efficiency. This paper proposes an improved underwater 3D reconstruction system to address these issues and achieve rapid, high-quality 3D reconstruction.To begin with, we enhance underwater videos captured by a monocular camera to correct the poor image quality caused by the physical properties of the water medium while ensuring consistency in enhancement across adjacent frames. Subsequently, we perform keyframe selection on the video frames to optimize resource utilization and eliminate the impact of dynamic objects on the reconstruction results. The selected keyframes, after pose estimation using COLMAP, undergo a three-dimensional reconstruction improvement process using neural radiance fields based on multi-resolution hash coding for model construction and rendering.
Diffusion Models Enable Zero-Shot Pose Estimation for Lower-Limb Prosthetic Users
Dec 13, 2023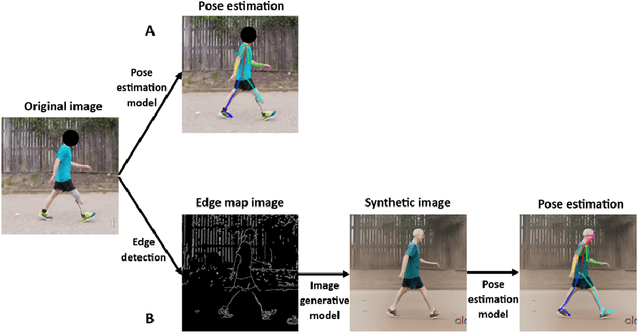
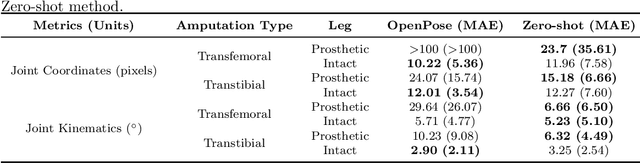
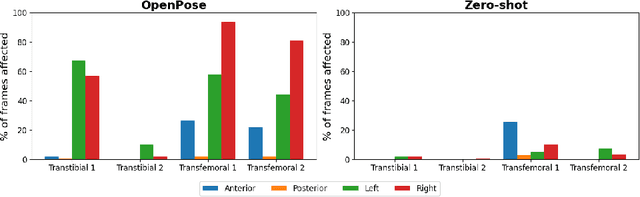
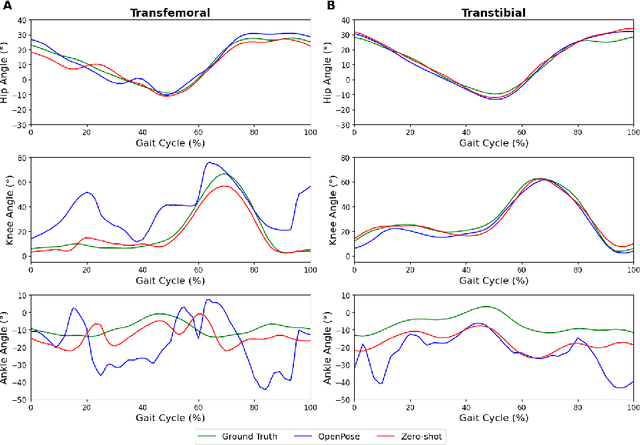
The application of 2D markerless gait analysis has garnered increasing interest and application within clinical settings. However, its effectiveness in the realm of lower-limb amputees has remained less than optimal. In response, this study introduces an innovative zero-shot method employing image generation diffusion models to achieve markerless pose estimation for lower-limb prosthetics, presenting a promising solution to gait analysis for this specific population. Our approach demonstrates an enhancement in detecting key points on prosthetic limbs over existing methods, and enables clinicians to gain invaluable insights into the kinematics of lower-limb amputees across the gait cycle. The outcomes obtained not only serve as a proof-of-concept for the feasibility of this zero-shot approach but also underscore its potential in advancing rehabilitation through gait analysis for this unique population.
Steerers: A framework for rotation equivariant keypoint descriptors
Dec 04, 2023Image keypoint descriptions that are discriminative and matchable over large changes in viewpoint are vital for 3D reconstruction. However, descriptions output by learned descriptors are typically not robust to camera rotation. While they can be made more robust by, e.g., data augmentation, this degrades performance on upright images. Another approach is test-time augmentation, which incurs a significant increase in runtime. We instead learn a linear transform in description space that encodes rotations of the input image. We call this linear transform a steerer since it allows us to transform the descriptions as if the image was rotated. From representation theory we know all possible steerers for the rotation group. Steerers can be optimized (A) given a fixed descriptor, (B) jointly with a descriptor or (C) we can optimize a descriptor given a fixed steerer. We perform experiments in all of these three settings and obtain state-of-the-art results on the rotation invariant image matching benchmarks AIMS and Roto-360. We publish code and model weights at github.com/georg-bn/rotation-steerers.
Video-Based Rendering Techniques: A Survey
Dec 08, 2023Three-dimensional reconstruction of events recorded on images has been a common challenge between computer vision and computer graphics for a long time. Estimating the real position of objects and surfaces using vision as an input is no trivial task and has been approached in several different ways. Although huge progress has been made so far, there are several open issues to which an answer is needed. The use of videos as an input for a rendering process (video-based rendering, VBR) is something that recently has been started to be looked upon and has added many other challenges and also solutions to the classical image-based rendering issue (IBR). This article presents the state of art on video-based rendering and image-based techniques that can be applied on this scenario, evaluating the open issues yet to be solved, indicating where future work should be focused.
A Parameterized Generative Adversarial Network Using Cyclic Projection for Explainable Medical Image Classification
Dec 07, 2023Although current data augmentation methods are successful to alleviate the data insufficiency, conventional augmentation are primarily intra-domain while advanced generative adversarial networks (GANs) generate images remaining uncertain, particularly in small-scale datasets. In this paper, we propose a parameterized GAN (ParaGAN) that effectively controls the changes of synthetic samples among domains and highlights the attention regions for downstream classification. Specifically, ParaGAN incorporates projection distance parameters in cyclic projection and projects the source images to the decision boundary to obtain the class-difference maps. Our experiments show that ParaGAN can consistently outperform the existing augmentation methods with explainable classification on two small-scale medical datasets.
Detecting and Restoring Non-Standard Hands in Stable Diffusion Generated Images
Dec 07, 2023We introduce a pipeline to address anatomical inaccuracies in Stable Diffusion generated hand images. The initial step involves constructing a specialized dataset, focusing on hand anomalies, to train our models effectively. A finetuned detection model is pivotal for precise identification of these anomalies, ensuring targeted correction. Body pose estimation aids in understanding hand orientation and positioning, crucial for accurate anomaly correction. The integration of ControlNet and InstructPix2Pix facilitates sophisticated inpainting and pixel-level transformation, respectively. This dual approach allows for high-fidelity image adjustments. This comprehensive approach ensures the generation of images with anatomically accurate hands, closely resembling real-world appearances. Our experimental results demonstrate the pipeline's efficacy in enhancing hand image realism in Stable Diffusion outputs. We provide an online demo at https://fixhand.yiqun.io
How to Train Neural Field Representations: A Comprehensive Study and Benchmark
Dec 16, 2023Neural fields (NeFs) have recently emerged as a versatile method for modeling signals of various modalities, including images, shapes, and scenes. Subsequently, a number of works have explored the use of NeFs as representations for downstream tasks, e.g. classifying an image based on the parameters of a NeF that has been fit to it. However, the impact of the NeF hyperparameters on their quality as downstream representation is scarcely understood and remains largely unexplored. This is in part caused by the large amount of time required to fit datasets of neural fields. In this work, we propose $\verb|fit-a-nef|$, a JAX-based library that leverages parallelization to enable fast optimization of large-scale NeF datasets, resulting in a significant speed-up. With this library, we perform a comprehensive study that investigates the effects of different hyperparameters -- including initialization, network architecture, and optimization strategies -- on fitting NeFs for downstream tasks. Our study provides valuable insights on how to train NeFs and offers guidance for optimizing their effectiveness in downstream applications. Finally, based on the proposed library and our analysis, we propose Neural Field Arena, a benchmark consisting of neural field variants of popular vision datasets, including MNIST, CIFAR, variants of ImageNet, and ShapeNetv2. Our library and the Neural Field Arena will be open-sourced to introduce standardized benchmarking and promote further research on neural fields.
Image Clustering Conditioned on Text Criteria
Oct 30, 2023
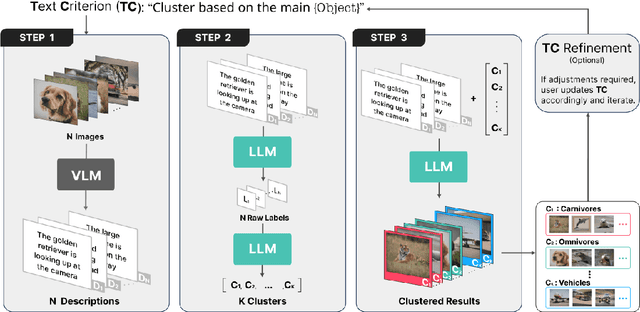


Classical clustering methods do not provide users with direct control of the clustering results, and the clustering results may not be consistent with the relevant criterion that a user has in mind. In this work, we present a new methodology for performing image clustering based on user-specified text criteria by leveraging modern vision-language models and large language models. We call our method Image Clustering Conditioned on Text Criteria (IC$|$TC), and it represents a different paradigm of image clustering. IC$|$TC requires a minimal and practical degree of human intervention and grants the user significant control over the clustering results in return. Our experiments show that IC$|$TC can effectively cluster images with various criteria, such as human action, physical location, or the person's mood, while significantly outperforming baselines.