 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
UpFusion: Novel View Diffusion from Unposed Sparse View Observations
Dec 11, 2023
We propose UpFusion, a system that can perform novel view synthesis and infer 3D representations for an object given a sparse set of reference images without corresponding pose information. Current sparse-view 3D inference methods typically rely on camera poses to geometrically aggregate information from input views, but are not robust in-the-wild when such information is unavailable/inaccurate. In contrast, UpFusion sidesteps this requirement by learning to implicitly leverage the available images as context in a conditional generative model for synthesizing novel views. We incorporate two complementary forms of conditioning into diffusion models for leveraging the input views: a) via inferring query-view aligned features using a scene-level transformer, b) via intermediate attentional layers that can directly observe the input image tokens. We show that this mechanism allows generating high-fidelity novel views while improving the synthesis quality given additional (unposed) images. We evaluate our approach on the Co3Dv2 and Google Scanned Objects datasets and demonstrate the benefits of our method over pose-reliant sparse-view methods as well as single-view methods that cannot leverage additional views. Finally, we also show that our learned model can generalize beyond the training categories and even allow reconstruction from self-captured images of generic objects in-the-wild.
Deep Imbalanced Learning for Multimodal Emotion Recognition in Conversations
Dec 11, 2023The main task of Multimodal Emotion Recognition in Conversations (MERC) is to identify the emotions in modalities, e.g., text, audio, image and video, which is a significant development direction for realizing machine intelligence. However, many data in MERC naturally exhibit an imbalanced distribution of emotion categories, and researchers ignore the negative impact of imbalanced data on emotion recognition. To tackle this problem, we systematically analyze it from three aspects: data augmentation, loss sensitivity, and sampling strategy, and propose the Class Boundary Enhanced Representation Learning (CBERL) model. Concretely, we first design a multimodal generative adversarial network to address the imbalanced distribution of {emotion} categories in raw data. Secondly, a deep joint variational autoencoder is proposed to fuse complementary semantic information across modalities and obtain discriminative feature representations. Finally, we implement a multi-task graph neural network with mask reconstruction and classification optimization to solve the problem of overfitting and underfitting in class boundary learning, and achieve cross-modal emotion recognition. We have conducted extensive experiments on the IEMOCAP and MELD benchmark datasets, and the results show that CBERL has achieved a certain performance improvement in the effectiveness of emotion recognition. Especially on the minority class fear and disgust emotion labels, our model improves the accuracy and F1 value by 10% to 20%.
ArtBank: Artistic Style Transfer with Pre-trained Diffusion Model and Implicit Style Prompt Bank
Dec 11, 2023Artistic style transfer aims to repaint the content image with the learned artistic style. Existing artistic style transfer methods can be divided into two categories: small model-based approaches and pre-trained large-scale model-based approaches. Small model-based approaches can preserve the content strucuture, but fail to produce highly realistic stylized images and introduce artifacts and disharmonious patterns; Pre-trained large-scale model-based approaches can generate highly realistic stylized images but struggle with preserving the content structure. To address the above issues, we propose ArtBank, a novel artistic style transfer framework, to generate highly realistic stylized images while preserving the content structure of the content images. Specifically, to sufficiently dig out the knowledge embedded in pre-trained large-scale models, an Implicit Style Prompt Bank (ISPB), a set of trainable parameter matrices, is designed to learn and store knowledge from the collection of artworks and behave as a visual prompt to guide pre-trained large-scale models to generate highly realistic stylized images while preserving content structure. Besides, to accelerate training the above ISPB, we propose a novel Spatial-Statistical-based self-Attention Module (SSAM). The qualitative and quantitative experiments demonstrate the superiority of our proposed method over state-of-the-art artistic style transfer methods.
The Blessing of Randomness: SDE Beats ODE in General Diffusion-based Image Editing
Nov 02, 2023
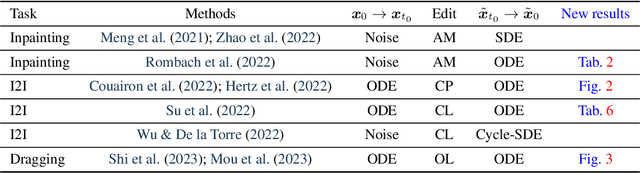

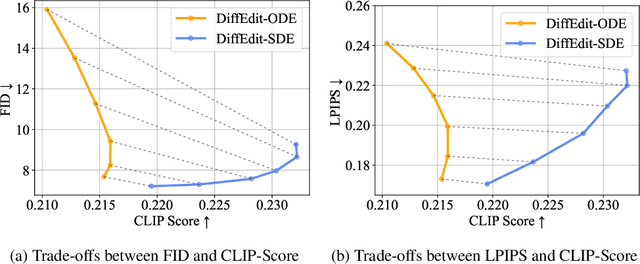
We present a unified probabilistic formulation for diffusion-based image editing, where a latent variable is edited in a task-specific manner and generally deviates from the corresponding marginal distribution induced by the original stochastic or ordinary differential equation (SDE or ODE). Instead, it defines a corresponding SDE or ODE for editing. In the formulation, we prove that the Kullback-Leibler divergence between the marginal distributions of the two SDEs gradually decreases while that for the ODEs remains as the time approaches zero, which shows the promise of SDE in image editing. Inspired by it, we provide the SDE counterparts for widely used ODE baselines in various tasks including inpainting and image-to-image translation, where SDE shows a consistent and substantial improvement. Moreover, we propose SDE-Drag -- a simple yet effective method built upon the SDE formulation for point-based content dragging. We build a challenging benchmark (termed DragBench) with open-set natural, art, and AI-generated images for evaluation. A user study on DragBench indicates that SDE-Drag significantly outperforms our ODE baseline, existing diffusion-based methods, and the renowned DragGAN. Our results demonstrate the superiority and versatility of SDE in image editing and push the boundary of diffusion-based editing methods.
Heteroscedastic Uncertainty Estimation for Probabilistic Unsupervised Registration of Noisy Medical Images
Dec 01, 2023This paper proposes a heteroscedastic uncertainty estimation framework for unsupervised medical image registration. Existing methods rely on objectives (e.g. mean-squared error) that assume a uniform noise level across the image, disregarding the heteroscedastic and input-dependent characteristics of noise distribution in real-world medical images. This further introduces noisy gradients due to undesired penalization on outliers, causing unnatural deformation and performance degradation. To mitigate this, we propose an adaptive weighting scheme with a relative $\gamma$-exponentiated signal-to-noise ratio (SNR) for the displacement estimator after modeling the heteroscedastic noise using a separate variance estimator to prevent the model from being driven away by spurious gradients from error residuals, leading to more accurate displacement estimation. To illustrate the versatility and effectiveness of the proposed method, we tested our framework on two representative registration architectures across three medical image datasets. Our proposed framework consistently outperforms other baselines both quantitatively and qualitatively while also providing accurate and sensible uncertainty measures. Paired t-tests show that our improvements in registration accuracy are statistically significant. The code will be publicly available at \url{https://voldemort108x.github.io/hetero_uncertainty/}.
Visual Anagrams: Generating Multi-View Optical Illusions with Diffusion Models
Nov 29, 2023We address the problem of synthesizing multi-view optical illusions: images that change appearance upon a transformation, such as a flip or rotation. We propose a simple, zero-shot method for obtaining these illusions from off-the-shelf text-to-image diffusion models. During the reverse diffusion process, we estimate the noise from different views of a noisy image. We then combine these noise estimates together and denoise the image. A theoretical analysis suggests that this method works precisely for views that can be written as orthogonal transformations, of which permutations are a subset. This leads to the idea of a visual anagram--an image that changes appearance under some rearrangement of pixels. This includes rotations and flips, but also more exotic pixel permutations such as a jigsaw rearrangement. Our approach also naturally extends to illusions with more than two views. We provide both qualitative and quantitative results demonstrating the effectiveness and flexibility of our method. Please see our project webpage for additional visualizations and results: https://dangeng.github.io/visual_anagrams/
AnyLens: A Generative Diffusion Model with Any Rendering Lens
Nov 29, 2023

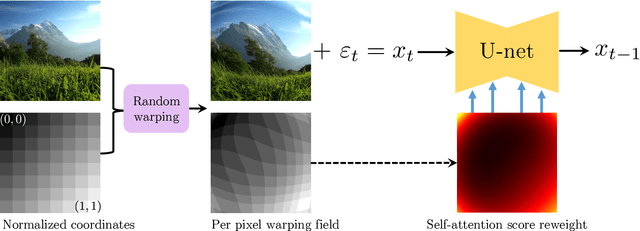
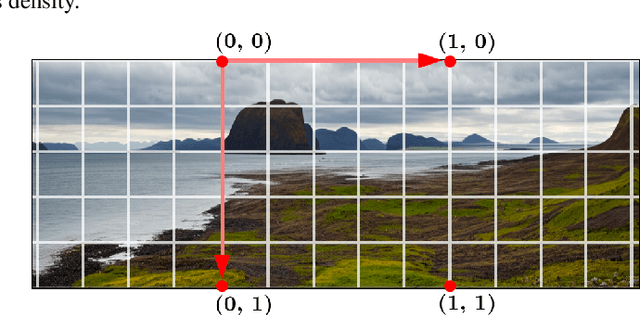
State-of-the-art diffusion models can generate highly realistic images based on various conditioning like text, segmentation, and depth. However, an essential aspect often overlooked is the specific camera geometry used during image capture. The influence of different optical systems on the final scene appearance is frequently overlooked. This study introduces a framework that intimately integrates a text-to-image diffusion model with the particular lens geometry used in image rendering. Our method is based on a per-pixel coordinate conditioning method, enabling the control over the rendering geometry. Notably, we demonstrate the manipulation of curvature properties, achieving diverse visual effects, such as fish-eye, panoramic views, and spherical texturing using a single diffusion model.
PixelLM: Pixel Reasoning with Large Multimodal Model
Dec 04, 2023While large multimodal models (LMMs) have achieved remarkable progress, generating pixel-level masks for image reasoning tasks involving multiple open-world targets remains a challenge. To bridge this gap, we introduce PixelLM, an effective and efficient LMM for pixel-level reasoning and understanding. Central to PixelLM is a novel, lightweight pixel decoder and a comprehensive segmentation codebook. The decoder efficiently produces masks from the hidden embeddings of the codebook tokens, which encode detailed target-relevant information. With this design, PixelLM harmonizes with the structure of popular LMMs and avoids the need for additional costly segmentation models. Furthermore, we propose a target refinement loss to enhance the model's ability to differentiate between multiple targets, leading to substantially improved mask quality. To advance research in this area, we construct MUSE, a high-quality multi-target reasoning segmentation benchmark. PixelLM excels across various pixel-level image reasoning and understanding tasks, outperforming well-established methods in multiple benchmarks, including MUSE, single- and multi-referring segmentation. Comprehensive ablations confirm the efficacy of each proposed component. All code, models, and datasets will be publicly available.
PECANN: Parallel Efficient Clustering with Graph-Based Approximate Nearest Neighbor Search
Dec 13, 2023
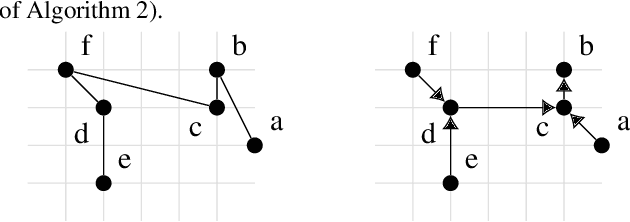
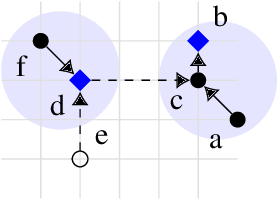
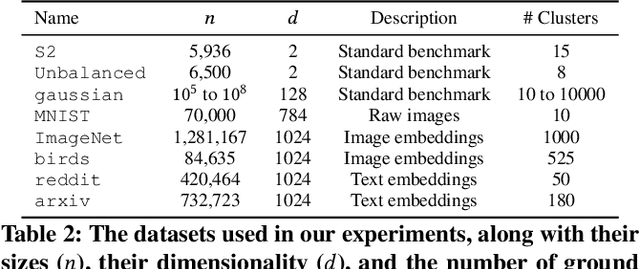
This paper studies density-based clustering of point sets. These methods use dense regions of points to detect clusters of arbitrary shapes. In particular, we study variants of density peaks clustering, a popular type of algorithm that has been shown to work well in practice. Our goal is to cluster large high-dimensional datasets, which are prevalent in practice. Prior solutions are either sequential, and cannot scale to large data, or are specialized for low-dimensional data. This paper unifies the different variants of density peaks clustering into a single framework, PECANN, by abstracting out several key steps common to this class of algorithms. One such key step is to find nearest neighbors that satisfy a predicate function, and one of the main contributions of this paper is an efficient way to do this predicate search using graph-based approximate nearest neighbor search (ANNS). To provide ample parallelism, we propose a doubling search technique that enables points to find an approximate nearest neighbor satisfying the predicate in a small number of rounds. Our technique can be applied to many existing graph-based ANNS algorithms, which can all be plugged into PECANN. We implement five clustering algorithms with PECANN and evaluate them on synthetic and real-world datasets with up to 1.28 million points and up to 1024 dimensions on a 30-core machine with two-way hyper-threading. Compared to the state-of-the-art FASTDP algorithm for high-dimensional density peaks clustering, which is sequential, our best algorithm is 45x-734x faster while achieving competitive ARI scores. Compared to the state-of-the-art parallel DPC-based algorithm, which is optimized for low dimensions, we show that PECANN is two orders of magnitude faster. As far as we know, our work is the first to evaluate DPC variants on large high-dimensional real-world image and text embedding datasets.
Rethinking Mixup for Improving the Adversarial Transferability
Nov 28, 2023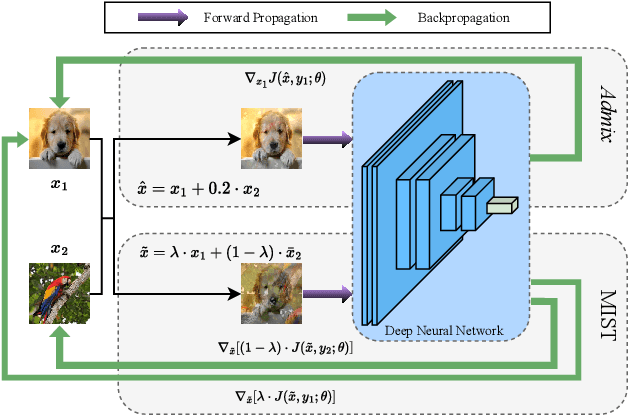
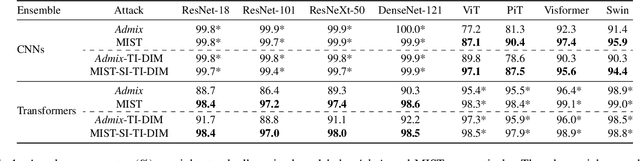
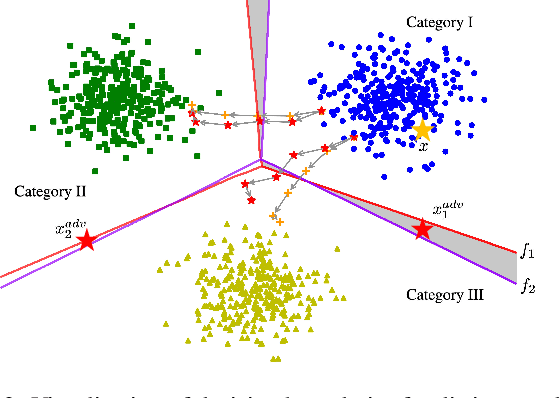
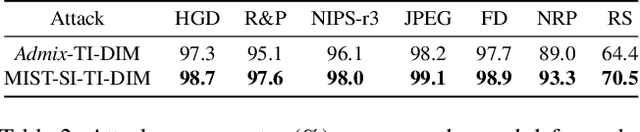
Mixup augmentation has been widely integrated to generate adversarial examples with superior adversarial transferability when immigrating from a surrogate model to other models. However, the underlying mechanism influencing the mixup's effect on transferability remains unexplored. In this work, we posit that the adversarial examples located at the convergence of decision boundaries across various categories exhibit better transferability and identify that Admix tends to steer the adversarial examples towards such regions. However, we find the constraint on the added image in Admix decays its capability, resulting in limited transferability. To address such an issue, we propose a new input transformation-based attack called Mixing the Image but Separating the gradienT (MIST). Specifically, MIST randomly mixes the input image with a randomly shifted image and separates the gradient of each loss item for each mixed image. To counteract the imprecise gradient, MIST calculates the gradient on several mixed images for each input sample. Extensive experimental results on the ImageNet dataset demonstrate that MIST outperforms existing SOTA input transformation-based attacks with a clear margin on both Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) w/wo defense mechanisms, supporting MIST's high effectiveness and generality.