 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Comprehensive Literature Review on Sweet Orange Leaf Diseases
Dec 04, 2023
Sweet orange leaf diseases are significant to agricultural productivity. Leaf diseases impact fruit quality in the citrus industry. The apparition of machine learning makes the development of disease finder. Early detection and diagnosis are necessary for leaf management. Sweet orange leaf disease-predicting automated systems have already been developed using different image-processing techniques. This comprehensive literature review is systematically based on leaf disease and machine learning methodologies applied to the detection of damaged leaves via image classification. The benefits and limitations of different machine learning models, including Vision Transformer (ViT), Neural Network (CNN), CNN with SoftMax and RBF SVM, Hybrid CNN-SVM, HLB-ConvMLP, EfficientNet-b0, YOLOv5, YOLOv7, Convolutional, Deep CNN. These machine learning models tested on various datasets and detected the disease. This comprehensive review study related to leaf disease compares the performance of the models; those models' accuracy, precision, recall, etc., were used in the subsisting studies
Medical Image Denosing via Explainable AI Feature Preserving Loss
Oct 31, 2023Denoising algorithms play a crucial role in medical image processing and analysis. However, classical denoising algorithms often ignore explanatory and critical medical features preservation, which may lead to misdiagnosis and legal liabilities.In this work, we propose a new denoising method for medical images that not only efficiently removes various types of noise, but also preserves key medical features throughout the process. To achieve this goal, we utilize a gradient-based eXplainable Artificial Intelligence (XAI) approach to design a feature preserving loss function. Our feature preserving loss function is motivated by the characteristic that gradient-based XAI is sensitive to noise. Through backpropagation, medical image features before and after denoising can be kept consistent. We conducted extensive experiments on three available medical image datasets, including synthesized 13 different types of noise and artifacts. The experimental results demonstrate the superiority of our method in terms of denoising performance, model explainability, and generalization.
NeVRF: Neural Video-based Radiance Fields for Long-duration Sequences
Dec 10, 2023Adopting Neural Radiance Fields (NeRF) to long-duration dynamic sequences has been challenging. Existing methods struggle to balance between quality and storage size and encounter difficulties with complex scene changes such as topological changes and large motions. To tackle these issues, we propose a novel neural video-based radiance fields (NeVRF) representation. NeVRF marries neural radiance field with image-based rendering to support photo-realistic novel view synthesis on long-duration dynamic inward-looking scenes. We introduce a novel multi-view radiance blending approach to predict radiance directly from multi-view videos. By incorporating continual learning techniques, NeVRF can efficiently reconstruct frames from sequential data without revisiting previous frames, enabling long-duration free-viewpoint video. Furthermore, with a tailored compression approach, NeVRF can compactly represent dynamic scenes, making dynamic radiance fields more practical in real-world scenarios. Our extensive experiments demonstrate the effectiveness of NeVRF in enabling long-duration sequence rendering, sequential data reconstruction, and compact data storage.
Raising the Bar of AI-generated Image Detection with CLIP
Nov 30, 2023Aim of this work is to explore the potential of pre-trained vision-language models (VLMs) for universal detection of AI-generated images. We develop a lightweight detection strategy based on CLIP features and study its performance in a wide variety of challenging scenarios. We find that, unlike previous belief, it is neither necessary nor convenient to use a large domain-specific dataset for training. On the contrary, by using only a handful of example images from a single generative model, a CLIP-based detector exhibits a surprising generalization ability and high robustness across several different architectures, including recent commercial tools such as Dalle-3, Midjourney v5, and Firefly. We match the SoTA on in-distribution data, and improve largely above it in terms of generalization to out-of-distribution data (+6% in terms of AUC) and robustness to impaired/laundered data (+13%). Our project is available at https://grip-unina.github.io/ClipBased-SyntheticImageDetection/
Comparing YOLOv8 and Mask RCNN for object segmentation in complex orchard environments
Dec 13, 2023Instance segmentation, an important image processing operation for automation in agriculture, is used to precisely delineate individual objects of interest within images, which provides foundational information for various automated or robotic tasks such as selective harvesting and precision pruning. This study compares the one-stage YOLOv8 and the two-stage Mask R-CNN machine learning models for instance segmentation under varying orchard conditions across two datasets. Dataset 1, collected in dormant season, includes images of dormant apple trees, which were used to train multi-object segmentation models delineating tree branches and trunks. Dataset 2, collected in the early growing season, includes images of apple tree canopies with green foliage and immature (green) apples (also called fruitlet), which were used to train single-object segmentation models delineating only immature green apples. The results showed that YOLOv8 performed better than Mask R-CNN, achieving good precision and near-perfect recall across both datasets at a confidence threshold of 0.5. Specifically, for Dataset 1, YOLOv8 achieved a precision of 0.90 and a recall of 0.95 for all classes. In comparison, Mask R-CNN demonstrated a precision of 0.81 and a recall of 0.81 for the same dataset. With Dataset 2, YOLOv8 achieved a precision of 0.93 and a recall of 0.97. Mask R-CNN, in this single-class scenario, achieved a precision of 0.85 and a recall of 0.88. Additionally, the inference times for YOLOv8 were 10.9 ms for multi-class segmentation (Dataset 1) and 7.8 ms for single-class segmentation (Dataset 2), compared to 15.6 ms and 12.8 ms achieved by Mask R-CNN's, respectively.
Super-Resolution through StyleGAN Regularized Latent Search: A Realism-Fidelity Trade-off
Nov 28, 2023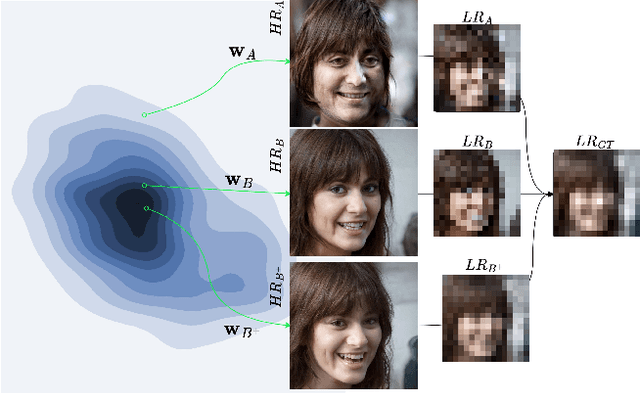
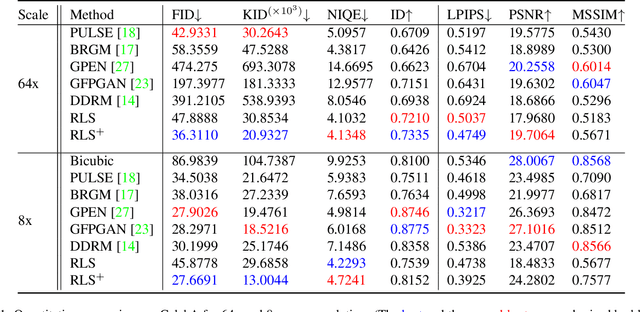

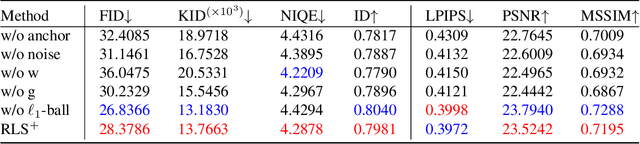
This paper addresses the problem of super-resolution: constructing a highly resolved (HR) image from a low resolved (LR) one. Recent unsupervised approaches search the latent space of a StyleGAN pre-trained on HR images, for the image that best downscales to the input LR image. However, they tend to produce out-of-domain images and fail to accurately reconstruct HR images that are far from the original domain. Our contribution is twofold. Firstly, we introduce a new regularizer to constrain the search in the latent space, ensuring that the inverted code lies in the original image manifold. Secondly, we further enhanced the reconstruction through expanding the image prior around the optimal latent code. Our results show that the proposed approach recovers realistic high-quality images for large magnification factors. Furthermore, for low magnification factors, it can still reconstruct details that the generator could not have produced otherwise. Altogether, our approach achieves a good trade-off between fidelity and realism for the super-resolution task.
EdgeSAM: Prompt-In-the-Loop Distillation for On-Device Deployment of SAM
Dec 11, 2023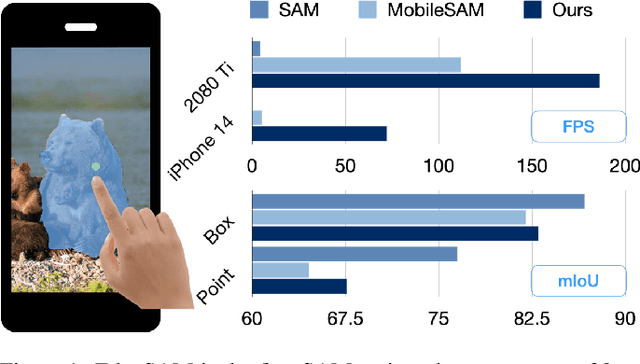
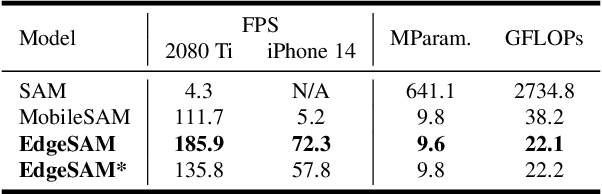
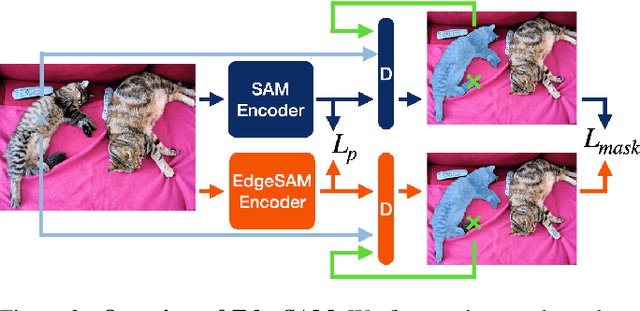
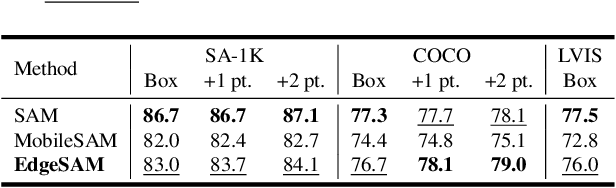
This paper presents EdgeSAM, an accelerated variant of the Segment Anything Model (SAM), optimized for efficient execution on edge devices with minimal compromise in performance. Our approach involves distilling the original ViT-based SAM image encoder into a purely CNN-based architecture, better suited for edge devices. We carefully benchmark various distillation strategies and demonstrate that task-agnostic encoder distillation fails to capture the full knowledge embodied in SAM. To overcome this bottleneck, we include both the prompt encoder and mask decoder in the distillation process, with box and point prompts in the loop, so that the distilled model can accurately capture the intricate dynamics between user input and mask generation. To mitigate dataset bias issues stemming from point prompt distillation, we incorporate a lightweight module within the encoder. EdgeSAM achieves a 40-fold speed increase compared to the original SAM, and it also outperforms MobileSAM, being 14 times as fast when deployed on edge devices while enhancing the mIoUs on COCO and LVIS by 2.3 and 3.2 respectively. It is also the first SAM variant that can run at over 30 FPS on an iPhone 14. Code and models are available at https://github.com/chongzhou96/EdgeSAM.
LightSim: Neural Lighting Simulation for Urban Scenes
Dec 11, 2023

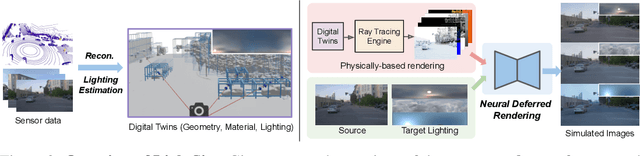
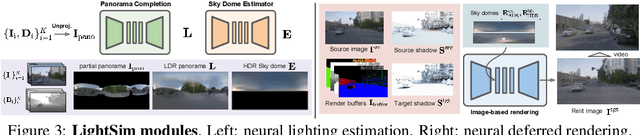
Different outdoor illumination conditions drastically alter the appearance of urban scenes, and they can harm the performance of image-based robot perception systems if not seen during training. Camera simulation provides a cost-effective solution to create a large dataset of images captured under different lighting conditions. Towards this goal, we propose LightSim, a neural lighting camera simulation system that enables diverse, realistic, and controllable data generation. LightSim automatically builds lighting-aware digital twins at scale from collected raw sensor data and decomposes the scene into dynamic actors and static background with accurate geometry, appearance, and estimated scene lighting. These digital twins enable actor insertion, modification, removal, and rendering from a new viewpoint, all in a lighting-aware manner. LightSim then combines physically-based and learnable deferred rendering to perform realistic relighting of modified scenes, such as altering the sun location and modifying the shadows or changing the sun brightness, producing spatially- and temporally-consistent camera videos. Our experiments show that LightSim generates more realistic relighting results than prior work. Importantly, training perception models on data generated by LightSim can significantly improve their performance.
DreamControl: Control-Based Text-to-3D Generation with 3D Self-Prior
Dec 11, 20233D generation has raised great attention in recent years. With the success of text-to-image diffusion models, the 2D-lifting technique becomes a promising route to controllable 3D generation. However, these methods tend to present inconsistent geometry, which is also known as the Janus problem. We observe that the problem is caused mainly by two aspects, i.e., viewpoint bias in 2D diffusion models and overfitting of the optimization objective. To address it, we propose a two-stage 2D-lifting framework, namely DreamControl, which optimizes coarse NeRF scenes as 3D self-prior and then generates fine-grained objects with control-based score distillation. Specifically, adaptive viewpoint sampling and boundary integrity metric are proposed to ensure the consistency of generated priors. The priors are then regarded as input conditions to maintain reasonable geometries, in which conditional LoRA and weighted score are further proposed to optimize detailed textures. DreamControl can generate high-quality 3D content in terms of both geometry consistency and texture fidelity. Moreover, our control-based optimization guidance is applicable to more downstream tasks, including user-guided generation and 3D animation. The project page is available at https://github.com/tyhuang0428/DreamControl.
Deciphering 'What' and 'Where' Visual Pathways from Spectral Clustering of Layer-Distributed Neural Representations
Dec 11, 2023We present an approach for analyzing grouping information contained within a neural network's activations, permitting extraction of spatial layout and semantic segmentation from the behavior of large pre-trained vision models. Unlike prior work, our method conducts a wholistic analysis of a network's activation state, leveraging features from all layers and obviating the need to guess which part of the model contains relevant information. Motivated by classic spectral clustering, we formulate this analysis in terms of an optimization objective involving a set of affinity matrices, each formed by comparing features within a different layer. Solving this optimization problem using gradient descent allows our technique to scale from single images to dataset-level analysis, including, in the latter, both intra- and inter-image relationships. Analyzing a pre-trained generative transformer provides insight into the computational strategy learned by such models. Equating affinity with key-query similarity across attention layers yields eigenvectors encoding scene spatial layout, whereas defining affinity by value vector similarity yields eigenvectors encoding object identity. This result suggests that key and query vectors coordinate attentional information flow according to spatial proximity (a `where' pathway), while value vectors refine a semantic category representation (a `what' pathway).