 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Spectral and Polarization Vision: Spectro-polarimetric Real-world Dataset
Nov 30, 2023
Image datasets are essential not only in validating existing methods in computer vision but also in developing new methods. Most existing image datasets focus on trichromatic intensity images to mimic human vision. However, polarization and spectrum, the wave properties of light that animals in harsh environments and with limited brain capacity often rely on, remain underrepresented in existing datasets. Although spectro-polarimetric datasets exist, these datasets have insufficient object diversity, limited illumination conditions, linear-only polarization data, and inadequate image count. Here, we introduce two spectro-polarimetric datasets: trichromatic Stokes images and hyperspectral Stokes images. These novel datasets encompass both linear and circular polarization; they introduce multiple spectral channels; and they feature a broad selection of real-world scenes. With our dataset in hand, we analyze the spectro-polarimetric image statistics, develop efficient representations of such high-dimensional data, and evaluate spectral dependency of shape-from-polarization methods. As such, the proposed dataset promises a foundation for data-driven spectro-polarimetric imaging and vision research. Dataset and code will be publicly available.
Object Recognition as Next Token Prediction
Dec 04, 2023We present an approach to pose object recognition as next token prediction. The idea is to apply a language decoder that auto-regressively predicts the text tokens from image embeddings to form labels. To ground this prediction process in auto-regression, we customize a non-causal attention mask for the decoder, incorporating two key features: modeling tokens from different labels to be independent, and treating image tokens as a prefix. This masking mechanism inspires an efficient method - one-shot sampling - to simultaneously sample tokens of multiple labels in parallel and rank generated labels by their probabilities during inference. To further enhance the efficiency, we propose a simple strategy to construct a compact decoder by simply discarding the intermediate blocks of a pretrained language model. This approach yields a decoder that matches the full model's performance while being notably more efficient. The code is available at https://github.com/kaiyuyue/nxtp
A Comprehensive Literature Review on Sweet Orange Leaf Diseases
Dec 04, 2023Sweet orange leaf diseases are significant to agricultural productivity. Leaf diseases impact fruit quality in the citrus industry. The apparition of machine learning makes the development of disease finder. Early detection and diagnosis are necessary for leaf management. Sweet orange leaf disease-predicting automated systems have already been developed using different image-processing techniques. This comprehensive literature review is systematically based on leaf disease and machine learning methodologies applied to the detection of damaged leaves via image classification. The benefits and limitations of different machine learning models, including Vision Transformer (ViT), Neural Network (CNN), CNN with SoftMax and RBF SVM, Hybrid CNN-SVM, HLB-ConvMLP, EfficientNet-b0, YOLOv5, YOLOv7, Convolutional, Deep CNN. These machine learning models tested on various datasets and detected the disease. This comprehensive review study related to leaf disease compares the performance of the models; those models' accuracy, precision, recall, etc., were used in the subsisting studies
Multi-Branch Network for Imagery Emotion Prediction
Dec 12, 2023For a long time, images have proved perfect at both storing and conveying rich semantics, especially human emotions. A lot of research has been conducted to provide machines with the ability to recognize emotions in photos of people. Previous methods mostly focus on facial expressions but fail to consider the scene context, meanwhile scene context plays an important role in predicting emotions, leading to more accurate results. In addition, Valence-Arousal-Dominance (VAD) values offer a more precise quantitative understanding of continuous emotions, yet there has been less emphasis on predicting them compared to discrete emotional categories. In this paper, we present a novel Multi-Branch Network (MBN), which utilizes various source information, including faces, bodies, and scene contexts to predict both discrete and continuous emotions in an image. Experimental results on EMOTIC dataset, which contains large-scale images of people in unconstrained situations labeled with 26 discrete categories of emotions and VAD values, show that our proposed method significantly outperforms state-of-the-art methods with 28.4% in mAP and 0.93 in MAE. The results highlight the importance of utilizing multiple contextual information in emotion prediction and illustrate the potential of our proposed method in a wide range of applications, such as effective computing, human-computer interaction, and social robotics. Source code: https://github.com/BaoNinh2808/Multi-Branch-Network-for-Imagery-Emotion-Prediction
Convex Parameter Estimation of Perturbed Multivariate Generalized Gaussian Distributions
Dec 12, 2023The multivariate generalized Gaussian distribution (MGGD), also known as the multivariate exponential power (MEP) distribution, is widely used in signal and image processing. However, estimating MGGD parameters, which is required in practical applications, still faces specific theoretical challenges. In particular, establishing convergence properties for the standard fixed-point approach when both the distribution mean and the scatter (or the precision) matrix are unknown is still an open problem. In robust estimation, imposing classical constraints on the precision matrix, such as sparsity, has been limited by the non-convexity of the resulting cost function. This paper tackles these issues from an optimization viewpoint by proposing a convex formulation with well-established convergence properties. We embed our analysis in a noisy scenario where robustness is induced by modelling multiplicative perturbations. The resulting framework is flexible as it combines a variety of regularizations for the precision matrix, the mean and model perturbations. This paper presents proof of the desired theoretical properties, specifies the conditions preserving these properties for different regularization choices and designs a general proximal primal-dual optimization strategy. The experiments show a more accurate precision and covariance matrix estimation with similar performance for the mean vector parameter compared to Tyler's M-estimator. In a high-dimensional setting, the proposed method outperforms the classical GLASSO, one of its robust extensions, and the regularized Tyler's estimator.
MaxQ: Multi-Axis Query for N:M Sparsity Network
Dec 12, 2023N:M sparsity has received increasing attention due to its remarkable performance and latency trade-off compared with structured and unstructured sparsity. However, existing N:M sparsity methods do not differentiate the relative importance of weights among blocks and leave important weights underappreciated. Besides, they directly apply N:M sparsity to the whole network, which will cause severe information loss. Thus, they are still sub-optimal. In this paper, we propose an efficient and effective Multi-Axis Query methodology, dubbed as MaxQ, to rectify these problems. During the training, MaxQ employs a dynamic approach to generate soft N:M masks, considering the weight importance across multiple axes. This method enhances the weights with more importance and ensures more effective updates. Meanwhile, a sparsity strategy that gradually increases the percentage of N:M weight blocks is applied, which allows the network to heal from the pruning-induced damage progressively. During the runtime, the N:M soft masks can be precomputed as constants and folded into weights without causing any distortion to the sparse pattern and incurring additional computational overhead. Comprehensive experiments demonstrate that MaxQ achieves consistent improvements across diverse CNN architectures in various computer vision tasks, including image classification, object detection and instance segmentation. For ResNet50 with 1:16 sparse pattern, MaxQ can achieve 74.6\% top-1 accuracy on ImageNet and improve by over 2.8\% over the state-of-the-art.
X4D-SceneFormer: Enhanced Scene Understanding on 4D Point Cloud Videos through Cross-modal Knowledge Transfer
Dec 12, 2023The field of 4D point cloud understanding is rapidly developing with the goal of analyzing dynamic 3D point cloud sequences. However, it remains a challenging task due to the sparsity and lack of texture in point clouds. Moreover, the irregularity of point cloud poses a difficulty in aligning temporal information within video sequences. To address these issues, we propose a novel cross-modal knowledge transfer framework, called X4D-SceneFormer. This framework enhances 4D-Scene understanding by transferring texture priors from RGB sequences using a Transformer architecture with temporal relationship mining. Specifically, the framework is designed with a dual-branch architecture, consisting of an 4D point cloud transformer and a Gradient-aware Image Transformer (GIT). During training, we employ multiple knowledge transfer techniques, including temporal consistency losses and masked self-attention, to strengthen the knowledge transfer between modalities. This leads to enhanced performance during inference using single-modal 4D point cloud inputs. Extensive experiments demonstrate the superior performance of our framework on various 4D point cloud video understanding tasks, including action recognition, action segmentation and semantic segmentation. The results achieve 1st places, i.e., 85.3% (+7.9%) accuracy and 47.3% (+5.0%) mIoU for 4D action segmentation and semantic segmentation, on the HOI4D challenge\footnote{\url{http://www.hoi4d.top/}.}, outperforming previous state-of-the-art by a large margin. We release the code at https://github.com/jinglinglingling/X4D
EdgeSAM: Prompt-In-the-Loop Distillation for On-Device Deployment of SAM
Dec 11, 2023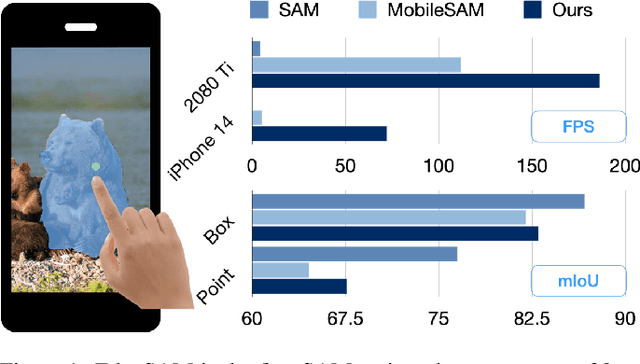
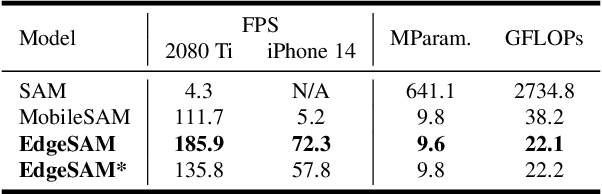
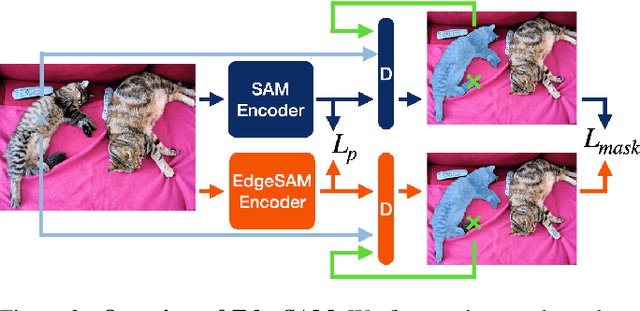
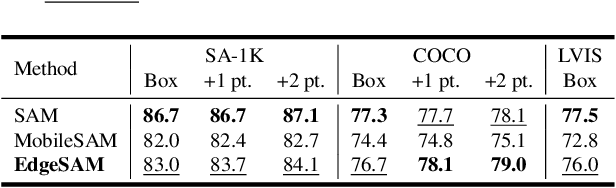
This paper presents EdgeSAM, an accelerated variant of the Segment Anything Model (SAM), optimized for efficient execution on edge devices with minimal compromise in performance. Our approach involves distilling the original ViT-based SAM image encoder into a purely CNN-based architecture, better suited for edge devices. We carefully benchmark various distillation strategies and demonstrate that task-agnostic encoder distillation fails to capture the full knowledge embodied in SAM. To overcome this bottleneck, we include both the prompt encoder and mask decoder in the distillation process, with box and point prompts in the loop, so that the distilled model can accurately capture the intricate dynamics between user input and mask generation. To mitigate dataset bias issues stemming from point prompt distillation, we incorporate a lightweight module within the encoder. EdgeSAM achieves a 40-fold speed increase compared to the original SAM, and it also outperforms MobileSAM, being 14 times as fast when deployed on edge devices while enhancing the mIoUs on COCO and LVIS by 2.3 and 3.2 respectively. It is also the first SAM variant that can run at over 30 FPS on an iPhone 14. Code and models are available at https://github.com/chongzhou96/EdgeSAM.
LightSim: Neural Lighting Simulation for Urban Scenes
Dec 11, 2023

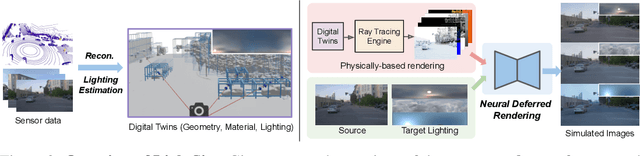
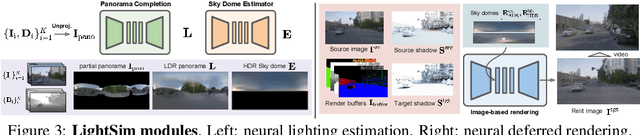
Different outdoor illumination conditions drastically alter the appearance of urban scenes, and they can harm the performance of image-based robot perception systems if not seen during training. Camera simulation provides a cost-effective solution to create a large dataset of images captured under different lighting conditions. Towards this goal, we propose LightSim, a neural lighting camera simulation system that enables diverse, realistic, and controllable data generation. LightSim automatically builds lighting-aware digital twins at scale from collected raw sensor data and decomposes the scene into dynamic actors and static background with accurate geometry, appearance, and estimated scene lighting. These digital twins enable actor insertion, modification, removal, and rendering from a new viewpoint, all in a lighting-aware manner. LightSim then combines physically-based and learnable deferred rendering to perform realistic relighting of modified scenes, such as altering the sun location and modifying the shadows or changing the sun brightness, producing spatially- and temporally-consistent camera videos. Our experiments show that LightSim generates more realistic relighting results than prior work. Importantly, training perception models on data generated by LightSim can significantly improve their performance.
DreamControl: Control-Based Text-to-3D Generation with 3D Self-Prior
Dec 11, 20233D generation has raised great attention in recent years. With the success of text-to-image diffusion models, the 2D-lifting technique becomes a promising route to controllable 3D generation. However, these methods tend to present inconsistent geometry, which is also known as the Janus problem. We observe that the problem is caused mainly by two aspects, i.e., viewpoint bias in 2D diffusion models and overfitting of the optimization objective. To address it, we propose a two-stage 2D-lifting framework, namely DreamControl, which optimizes coarse NeRF scenes as 3D self-prior and then generates fine-grained objects with control-based score distillation. Specifically, adaptive viewpoint sampling and boundary integrity metric are proposed to ensure the consistency of generated priors. The priors are then regarded as input conditions to maintain reasonable geometries, in which conditional LoRA and weighted score are further proposed to optimize detailed textures. DreamControl can generate high-quality 3D content in terms of both geometry consistency and texture fidelity. Moreover, our control-based optimization guidance is applicable to more downstream tasks, including user-guided generation and 3D animation. The project page is available at https://github.com/tyhuang0428/DreamControl.