 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Sound Source Localization for a Source inside a Structure using Ac-CycleGAN
Dec 08, 2023
We propose a method for sound source localization (SSL) for a source inside a structure using Ac-CycleGAN under unpaired data conditions. The proposed method utilizes a large amount of simulated data and a small amount of actual experimental data to locate a sound source inside a structure in a real environment. An Ac-CycleGAN generator contributes to the transformation of simulated data into real data, or vice versa, using unpaired data from both domains. The discriminator of an Ac-CycleGAN model is designed to differentiate between the transformed data generated by the generator and real data, while also predicting the location of the sound source. Vectors representing the frequency spectrum of the accelerometers (FSAs) measured at three points outside the structure are used as input data and the source areas inside the structure are used as labels. The input data vectors are concatenated vertically to form an image. Labels are defined by dividing the interior of the structure into eight areas with one-hot encoding for each area. Thus, the SSL problem is redefined as an image-classification problem to stochastically estimate the location of the sound source. We show that it is possible to estimate the sound source location using the Ac-CycleGAN discriminator for unpaired data across domains. Furthermore, we analyze the discriminative factors for distinguishing the data. The proposed model exhibited an accuracy exceeding 90\% when trained on 80\% of actual data (12.5\% of simulated data). Despite potential imperfections in the domain transformation process carried out by the Ac-CycleGAN generator, the discriminator can effectively distinguish between transferred and real data by selectively utilizing only those features that generate a relatively small transformation error.
Depth Insight -- Contribution of Different Features to Indoor Single-image Depth Estimation
Nov 16, 2023Depth estimation from a single image is a challenging problem in computer vision because binocular disparity or motion information is absent. Whereas impressive performances have been reported in this area recently using end-to-end trained deep neural architectures, as to what cues in the images that are being exploited by these black box systems is hard to know. To this end, in this work, we quantify the relative contributions of the known cues of depth in a monocular depth estimation setting using an indoor scene data set. Our work uses feature extraction techniques to relate the single features of shape, texture, colour and saturation, taken in isolation, to predict depth. We find that the shape of objects extracted by edge detection substantially contributes more than others in the indoor setting considered, while the other features also have contributions in varying degrees. These insights will help optimise depth estimation models, boosting their accuracy and robustness. They promise to broaden the practical applications of vision-based depth estimation. The project code is attached to the supplementary material and will be published on GitHub.
Self-correcting LLM-controlled Diffusion Models
Nov 27, 2023Text-to-image generation has witnessed significant progress with the advent of diffusion models. Despite the ability to generate photorealistic images, current text-to-image diffusion models still often struggle to accurately interpret and follow complex input text prompts. In contrast to existing models that aim to generate images only with their best effort, we introduce Self-correcting LLM-controlled Diffusion (SLD). SLD is a framework that generates an image from the input prompt, assesses its alignment with the prompt, and performs self-corrections on the inaccuracies in the generated image. Steered by an LLM controller, SLD turns text-to-image generation into an iterative closed-loop process, ensuring correctness in the resulting image. SLD is not only training-free but can also be seamlessly integrated with diffusion models behind API access, such as DALL-E 3, to further boost the performance of state-of-the-art diffusion models. Experimental results show that our approach can rectify a majority of incorrect generations, particularly in generative numeracy, attribute binding, and spatial relationships. Furthermore, by simply adjusting the instructions to the LLM, SLD can perform image editing tasks, bridging the gap between text-to-image generation and image editing pipelines. We will make our code available for future research and applications.
Comparing YOLOv8 and Mask RCNN for object segmentation in complex orchard environments
Dec 13, 2023Instance segmentation, an important image processing operation for automation in agriculture, is used to precisely delineate individual objects of interest within images, which provides foundational information for various automated or robotic tasks such as selective harvesting and precision pruning. This study compares the one-stage YOLOv8 and the two-stage Mask R-CNN machine learning models for instance segmentation under varying orchard conditions across two datasets. Dataset 1, collected in dormant season, includes images of dormant apple trees, which were used to train multi-object segmentation models delineating tree branches and trunks. Dataset 2, collected in the early growing season, includes images of apple tree canopies with green foliage and immature (green) apples (also called fruitlet), which were used to train single-object segmentation models delineating only immature green apples. The results showed that YOLOv8 performed better than Mask R-CNN, achieving good precision and near-perfect recall across both datasets at a confidence threshold of 0.5. Specifically, for Dataset 1, YOLOv8 achieved a precision of 0.90 and a recall of 0.95 for all classes. In comparison, Mask R-CNN demonstrated a precision of 0.81 and a recall of 0.81 for the same dataset. With Dataset 2, YOLOv8 achieved a precision of 0.93 and a recall of 0.97. Mask R-CNN, in this single-class scenario, achieved a precision of 0.85 and a recall of 0.88. Additionally, the inference times for YOLOv8 were 10.9 ms for multi-class segmentation (Dataset 1) and 7.8 ms for single-class segmentation (Dataset 2), compared to 15.6 ms and 12.8 ms achieved by Mask R-CNN's, respectively.
NeVRF: Neural Video-based Radiance Fields for Long-duration Sequences
Dec 10, 2023Adopting Neural Radiance Fields (NeRF) to long-duration dynamic sequences has been challenging. Existing methods struggle to balance between quality and storage size and encounter difficulties with complex scene changes such as topological changes and large motions. To tackle these issues, we propose a novel neural video-based radiance fields (NeVRF) representation. NeVRF marries neural radiance field with image-based rendering to support photo-realistic novel view synthesis on long-duration dynamic inward-looking scenes. We introduce a novel multi-view radiance blending approach to predict radiance directly from multi-view videos. By incorporating continual learning techniques, NeVRF can efficiently reconstruct frames from sequential data without revisiting previous frames, enabling long-duration free-viewpoint video. Furthermore, with a tailored compression approach, NeVRF can compactly represent dynamic scenes, making dynamic radiance fields more practical in real-world scenarios. Our extensive experiments demonstrate the effectiveness of NeVRF in enabling long-duration sequence rendering, sequential data reconstruction, and compact data storage.
MVHumanNet: A Large-scale Dataset of Multi-view Daily Dressing Human Captures
Dec 05, 2023In this era, the success of large language models and text-to-image models can be attributed to the driving force of large-scale datasets. However, in the realm of 3D vision, while remarkable progress has been made with models trained on large-scale synthetic and real-captured object data like Objaverse and MVImgNet, a similar level of progress has not been observed in the domain of human-centric tasks partially due to the lack of a large-scale human dataset. Existing datasets of high-fidelity 3D human capture continue to be mid-sized due to the significant challenges in acquiring large-scale high-quality 3D human data. To bridge this gap, we present MVHumanNet, a dataset that comprises multi-view human action sequences of 4,500 human identities. The primary focus of our work is on collecting human data that features a large number of diverse identities and everyday clothing using a multi-view human capture system, which facilitates easily scalable data collection. Our dataset contains 9,000 daily outfits, 60,000 motion sequences and 645 million frames with extensive annotations, including human masks, camera parameters, 2D and 3D keypoints, SMPL/SMPLX parameters, and corresponding textual descriptions. To explore the potential of MVHumanNet in various 2D and 3D visual tasks, we conducted pilot studies on view-consistent action recognition, human NeRF reconstruction, text-driven view-unconstrained human image generation, as well as 2D view-unconstrained human image and 3D avatar generation. Extensive experiments demonstrate the performance improvements and effective applications enabled by the scale provided by MVHumanNet. As the current largest-scale 3D human dataset, we hope that the release of MVHumanNet data with annotations will foster further innovations in the domain of 3D human-centric tasks at scale.
GPT4Point: A Unified Framework for Point-Language Understanding and Generation
Dec 05, 2023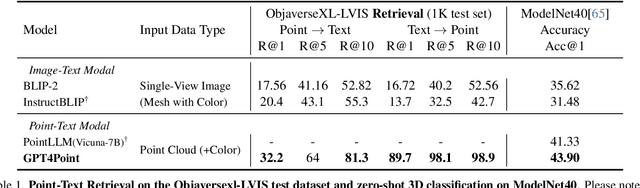
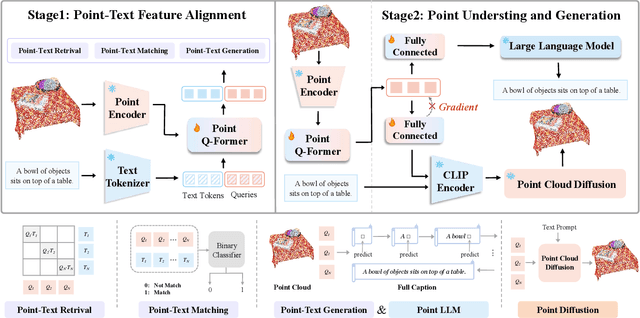
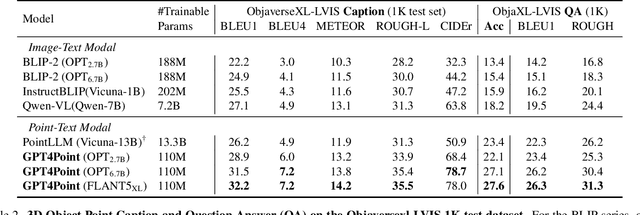
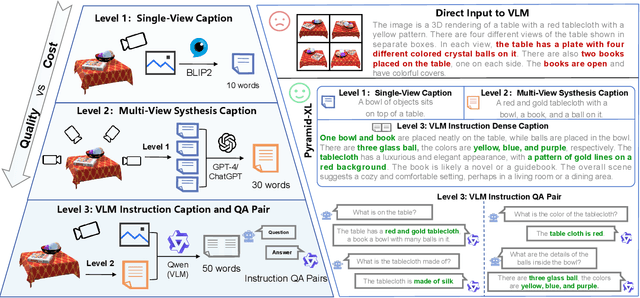
Multimodal Large Language Models (MLLMs) have excelled in 2D image-text comprehension and image generation, but their understanding of the 3D world is notably deficient, limiting progress in 3D language understanding and generation. To solve this problem, we introduce GPT4Point, an innovative groundbreaking point-language multimodal model designed specifically for unified 3D object understanding and generation within the MLLM framework. GPT4Point as a powerful 3D MLLM seamlessly can execute a variety of point-text reference tasks such as point-cloud captioning and Q&A. Additionally, GPT4Point is equipped with advanced capabilities for controllable 3D generation, it can get high-quality results through a low-quality point-text feature maintaining the geometric shapes and colors. To support the expansive needs of 3D object-text pairs, we develop Pyramid-XL, a point-language dataset annotation engine. It constructs a large-scale database over 1M objects of varied text granularity levels from the Objaverse-XL dataset, essential for training GPT4Point. A comprehensive benchmark has been proposed to evaluate 3D point-language understanding capabilities. In extensive evaluations, GPT4Point has demonstrated superior performance in understanding and generation.
Low-Dose CT Image Enhancement Using Deep Learning
Oct 31, 2023The application of ionizing radiation for diagnostic imaging is common around the globe. However, the process of imaging, itself, remains to be a relatively hazardous operation. Therefore, it is preferable to use as low a dose of ionizing radiation as possible, particularly in computed tomography (CT) imaging systems, where multiple x-ray operations are performed for the reconstruction of slices of body tissues. A popular method for radiation dose reduction in CT imaging is known as the quarter-dose technique, which reduces the x-ray dose but can cause a loss of image sharpness. Since CT image reconstruction from directional x-rays is a nonlinear process, it is analytically difficult to correct the effect of dose reduction on image quality. Recent and popular deep-learning approaches provide an intriguing possibility of image enhancement for low-dose artifacts. Some recent works propose combinations of multiple deep-learning and classical methods for this purpose, which over-complicate the process. However, it is observed here that the straight utilization of the well-known U-NET provides very successful results for the correction of low-dose artifacts. Blind tests with actual radiologists reveal that the U-NET enhanced quarter-dose CT images not only provide an immense visual improvement over the low-dose versions, but also become diagnostically preferable images, even when compared to their full-dose CT versions.
MicroCinema: A Divide-and-Conquer Approach for Text-to-Video Generation
Nov 30, 2023We present MicroCinema, a straightforward yet effective framework for high-quality and coherent text-to-video generation. Unlike existing approaches that align text prompts with video directly, MicroCinema introduces a Divide-and-Conquer strategy which divides the text-to-video into a two-stage process: text-to-image generation and image\&text-to-video generation. This strategy offers two significant advantages. a) It allows us to take full advantage of the recent advances in text-to-image models, such as Stable Diffusion, Midjourney, and DALLE, to generate photorealistic and highly detailed images. b) Leveraging the generated image, the model can allocate less focus to fine-grained appearance details, prioritizing the efficient learning of motion dynamics. To implement this strategy effectively, we introduce two core designs. First, we propose the Appearance Injection Network, enhancing the preservation of the appearance of the given image. Second, we introduce the Appearance Noise Prior, a novel mechanism aimed at maintaining the capabilities of pre-trained 2D diffusion models. These design elements empower MicroCinema to generate high-quality videos with precise motion, guided by the provided text prompts. Extensive experiments demonstrate the superiority of the proposed framework. Concretely, MicroCinema achieves SOTA zero-shot FVD of 342.86 on UCF-101 and 377.40 on MSR-VTT. See https://wangyanhui666.github.io/MicroCinema.github.io/ for video samples.
StyleCrafter: Enhancing Stylized Text-to-Video Generation with Style Adapter
Dec 01, 2023Text-to-video (T2V) models have shown remarkable capabilities in generating diverse videos. However, they struggle to produce user-desired stylized videos due to (i) text's inherent clumsiness in expressing specific styles and (ii) the generally degraded style fidelity. To address these challenges, we introduce StyleCrafter, a generic method that enhances pre-trained T2V models with a style control adapter, enabling video generation in any style by providing a reference image. Considering the scarcity of stylized video datasets, we propose to first train a style control adapter using style-rich image datasets, then transfer the learned stylization ability to video generation through a tailor-made finetuning paradigm. To promote content-style disentanglement, we remove style descriptions from the text prompt and extract style information solely from the reference image using a decoupling learning strategy. Additionally, we design a scale-adaptive fusion module to balance the influences of text-based content features and image-based style features, which helps generalization across various text and style combinations. StyleCrafter efficiently generates high-quality stylized videos that align with the content of the texts and resemble the style of the reference images. Experiments demonstrate that our approach is more flexible and efficient than existing competitors.