 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
EpiDiff: Enhancing Multi-View Synthesis via Localized Epipolar-Constrained Diffusion
Dec 11, 2023
Generating multiview images from a single view facilitates the rapid generation of a 3D mesh conditioned on a single image. Recent methods that introduce 3D global representation into diffusion models have shown the potential to generate consistent multiviews, but they have reduced generation speed and face challenges in maintaining generalizability and quality. To address this issue, we propose EpiDiff, a localized interactive multiview diffusion model. At the core of the proposed approach is to insert a lightweight epipolar attention block into the frozen diffusion model, leveraging epipolar constraints to enable cross-view interaction among feature maps of neighboring views. The newly initialized 3D modeling module preserves the original feature distribution of the diffusion model, exhibiting compatibility with a variety of base diffusion models. Experiments show that EpiDiff generates 16 multiview images in just 12 seconds, and it surpasses previous methods in quality evaluation metrics, including PSNR, SSIM and LPIPS. Additionally, EpiDiff can generate a more diverse distribution of views, improving the reconstruction quality from generated multiviews. Please see our project page at https://huanngzh.github.io/EpiDiff/.
TrackDiffusion: Multi-object Tracking Data Generation via Diffusion Models
Dec 01, 2023Diffusion models have gained prominence in generating data for perception tasks such as image classification and object detection. However, the potential in generating high-quality tracking sequences, a crucial aspect in the field of video perception, has not been fully investigated. To address this gap, we propose TrackDiffusion, a novel architecture designed to generate continuous video sequences from the tracklets. TrackDiffusion represents a significant departure from the traditional layout-to-image (L2I) generation and copy-paste synthesis focusing on static image elements like bounding boxes by empowering image diffusion models to encompass dynamic and continuous tracking trajectories, thereby capturing complex motion nuances and ensuring instance consistency among video frames. For the first time, we demonstrate that the generated video sequences can be utilized for training multi-object tracking (MOT) systems, leading to significant improvement in tracker performance. Experimental results show that our model significantly enhances instance consistency in generated video sequences, leading to improved perceptual metrics. Our approach achieves an improvement of 8.7 in TrackAP and 11.8 in TrackAP$_{50}$ on the YTVIS dataset, underscoring its potential to redefine the standards of video data generation for MOT tasks and beyond.
DSeg: Direct Line Segments Detection
Nov 30, 2023This paper presents a model-driven approach to detect image line segments. The approach incrementally detects segments on the gradient image using a linear Kalman filter that estimates the supporting line parameters and their associated variances. The algorithm is fast and robust with respect to image noise and illumination variations, it allows the detection of longer line segments than data-driven approaches, and does not require any tedious parameters tuning. An extension of the algorithm that exploits a pyramidal approach to enhance the quality of results is proposed. Results with varying scene illumination and comparisons to classic existing approaches are presented.
NearbyPatchCL: Leveraging Nearby Patches for Self-Supervised Patch-Level Multi-Class Classification in Whole-Slide Images
Dec 12, 2023Whole-slide image (WSI) analysis plays a crucial role in cancer diagnosis and treatment. In addressing the demands of this critical task, self-supervised learning (SSL) methods have emerged as a valuable resource, leveraging their efficiency in circumventing the need for a large number of annotations, which can be both costly and time-consuming to deploy supervised methods. Nevertheless, patch-wise representation may exhibit instability in performance, primarily due to class imbalances stemming from patch selection within WSIs. In this paper, we introduce Nearby Patch Contrastive Learning (NearbyPatchCL), a novel self-supervised learning method that leverages nearby patches as positive samples and a decoupled contrastive loss for robust representation learning. Our method demonstrates a tangible enhancement in performance for downstream tasks involving patch-level multi-class classification. Additionally, we curate a new dataset derived from WSIs sourced from the Canine Cutaneous Cancer Histology, thus establishing a benchmark for the rigorous evaluation of patch-level multi-class classification methodologies. Intensive experiments show that our method significantly outperforms the supervised baseline and state-of-the-art SSL methods with top-1 classification accuracy of 87.56%. Our method also achieves comparable results while utilizing a mere 1% of labeled data, a stark contrast to the 100% labeled data requirement of other approaches. Source code: https://github.com/nvtien457/NearbyPatchCL
Super-Resolution on Rotationally Scanned Photoacoustic Microscopy Images Incorporating Scanning Prior
Dec 12, 2023Photoacoustic Microscopy (PAM) images integrating the advantages of optical contrast and acoustic resolution have been widely used in brain studies. However, there exists a trade-off between scanning speed and image resolution. Compared with traditional raster scanning, rotational scanning provides good opportunities for fast PAM imaging by optimizing the scanning mechanism. Recently, there is a trend to incorporate deep learning into the scanning process to further increase the scanning speed.Yet, most such attempts are performed for raster scanning while those for rotational scanning are relatively rare. In this study, we propose a novel and well-performing super-resolution framework for rotational scanning-based PAM imaging. To eliminate adjacent rows' displacements due to subject motion or high-frequency scanning distortion,we introduce a registration module across odd and even rows in the preprocessing and incorporate displacement degradation in the training. Besides, gradient-based patch selection is proposed to increase the probability of blood vessel patches being selected for training. A Transformer-based network with a global receptive field is applied for better performance. Experimental results on both synthetic and real datasets demonstrate the effectiveness and generalizability of our proposed framework for rotationally scanned PAM images'super-resolution, both quantitatively and qualitatively. Code is available at https://github.com/11710615/PAMSR.git.
LoRA-Enhanced Distillation on Guided Diffusion Models
Dec 12, 2023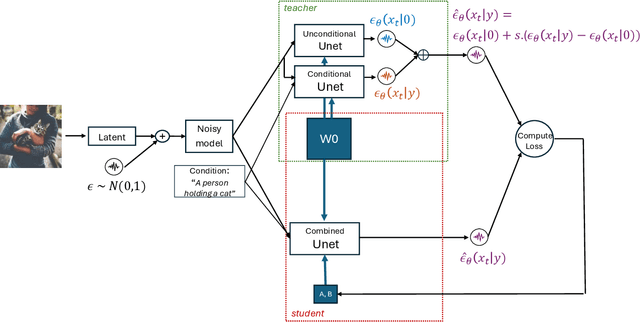


Diffusion models, such as Stable Diffusion (SD), offer the ability to generate high-resolution images with diverse features, but they come at a significant computational and memory cost. In classifier-free guided diffusion models, prolonged inference times are attributed to the necessity of computing two separate diffusion models at each denoising step. Recent work has shown promise in improving inference time through distillation techniques, teaching the model to perform similar denoising steps with reduced computations. However, the application of distillation introduces additional memory overhead to these already resource-intensive diffusion models, making it less practical. To address these challenges, our research explores a novel approach that combines Low-Rank Adaptation (LoRA) with model distillation to efficiently compress diffusion models. This approach not only reduces inference time but also mitigates memory overhead, and notably decreases memory consumption even before applying distillation. The results are remarkable, featuring a significant reduction in inference time due to the distillation process and a substantial 50% reduction in memory consumption. Our examination of the generated images underscores that the incorporation of LoRA-enhanced distillation maintains image quality and alignment with the provided prompts. In summary, while conventional distillation tends to increase memory consumption, LoRA-enhanced distillation offers optimization without any trade-offs or compromises in quality.
Diff-OP3D: Bridging 2D Diffusion for Open Pose 3D Zero-Shot Classification
Dec 12, 2023With the explosive 3D data growth, the urgency of utilizing zero-shot learning to facilitate data labeling becomes evident. Recently, the methods via transferring Contrastive Language-Image Pre-training (CLIP) to 3D vision have made great progress in the 3D zero-shot classification task. However, these methods primarily focus on aligned pose 3D objects (ap-3os), overlooking the recognition of 3D objects with open poses (op-3os) typically encountered in real-world scenarios, such as an overturned chair or a lying teddy bear. To this end, we propose a more challenging benchmark for 3D open-pose zero-shot classification. Echoing our benchmark, we design a concise angle-refinement mechanism that automatically optimizes one ideal pose as well as classifies these op-3os. Furthermore, we make a first attempt to bridge 2D pre-trained diffusion model as a classifer to 3D zero-shot classification without any additional training. Such 2D diffusion to 3D objects proves vital in improving zero-shot classification for both ap-3os and op-3os. Our model notably improves by 3.5% and 15.8% on ModelNet10$^{\ddag}$ and McGill$^{\ddag}$ open pose benchmarks, respectively, and surpasses the current state-of-the-art by 6.8% on the aligned pose ModelNet10, affirming diffusion's efficacy in 3D zero-shot tasks.
Lasagna: Layered Score Distillation for Disentangled Object Relighting
Nov 30, 2023Professional artists, photographers, and other visual content creators use object relighting to establish their photo's desired effect. Unfortunately, manual tools that allow relighting have a steep learning curve and are difficult to master. Although generative editing methods now enable some forms of image editing, relighting is still beyond today's capabilities; existing methods struggle to keep other aspects of the image -- colors, shapes, and textures -- consistent after the edit. We propose Lasagna, a method that enables intuitive text-guided relighting control. Lasagna learns a lighting prior by using score distillation sampling to distill the prior of a diffusion model, which has been finetuned on synthetic relighting data. To train Lasagna, we curate a new synthetic dataset ReLiT, which contains 3D object assets re-lit from multiple light source locations. Despite training on synthetic images, quantitative results show that Lasagna relights real-world images while preserving other aspects of the input image, outperforming state-of-the-art text-guided image editing methods. Lasagna enables realistic and controlled results on natural images and digital art pieces and is preferred by humans over other methods in over 91% of cases. Finally, we demonstrate the versatility of our learning objective by extending it to allow colorization, another form of image editing.
Think Twice Before Selection: Federated Evidential Active Learning for Medical Image Analysis with Domain Shifts
Dec 05, 2023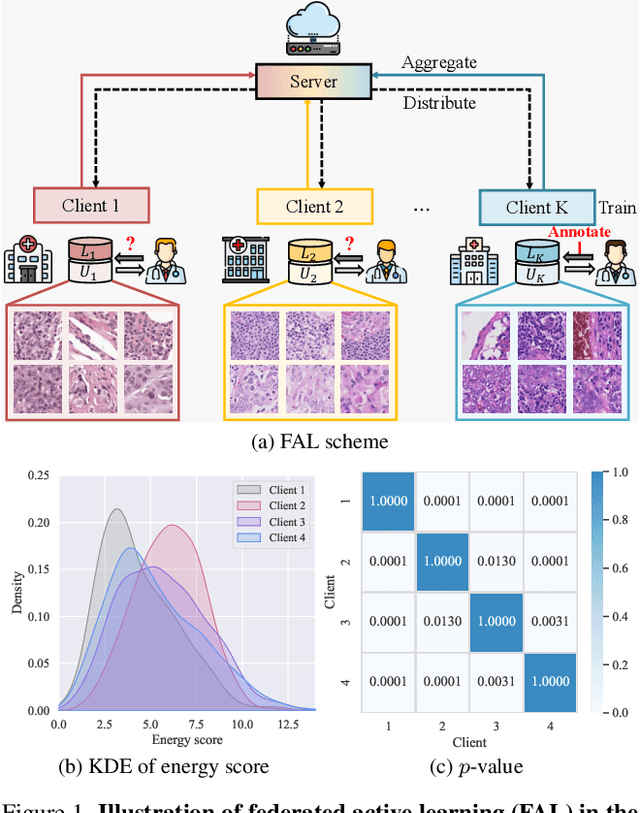
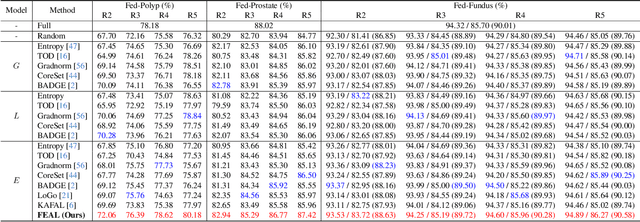
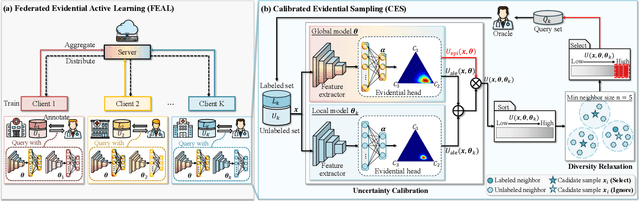
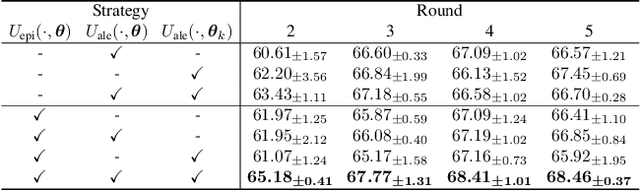
Federated learning facilitates the collaborative learning of a global model across multiple distributed medical institutions without centralizing data. Nevertheless, the expensive cost of annotation on local clients remains an obstacle to effectively utilizing local data. To mitigate this issue, federated active learning methods suggest leveraging local and global model predictions to select a relatively small amount of informative local data for annotation. However, existing methods mainly focus on all local data sampled from the same domain, making them unreliable in realistic medical scenarios with domain shifts among different clients. In this paper, we make the first attempt to assess the informativeness of local data derived from diverse domains and propose a novel methodology termed Federated Evidential Active Learning (FEAL) to calibrate the data evaluation under domain shift. Specifically, we introduce a Dirichlet prior distribution in both local and global models to treat the prediction as a distribution over the probability simplex and capture both aleatoric and epistemic uncertainties by using the Dirichlet-based evidential model. Then we employ the epistemic uncertainty to calibrate the aleatoric uncertainty. Afterward, we design a diversity relaxation strategy to reduce data redundancy and maintain data diversity. Extensive experiments and analyses are conducted to show the superiority of FEAL over the state-of-the-art active learning methods and the efficiency of FEAL under the federated active learning framework.
High-Resolution Maps of Left Atrial Displacements and Strains Estimated with 3D CINE MRI and Unsupervised Neural Networks
Dec 14, 2023The functional analysis of the left atrium (LA) is important for evaluating cardiac health and understanding diseases like atrial fibrillation. Cine MRI is ideally placed for the detailed 3D characterisation of LA motion and deformation, but it is lacking appropriate acquisition and analysis tools. In this paper, we present Analysis for Left Atrial Displacements and Deformations using unsupervIsed neural Networks, \textit{Aladdin}, to automatically and reliably characterise regional LA deformations from high-resolution 3D Cine MRI. The tool includes: an online few-shot segmentation network (Aladdin-S), an online unsupervised image registration network (Aladdin-R), and a strain calculations pipeline tailored to the LA. We create maps of LA Displacement Vector Field (DVF) magnitude and LA principal strain values from images of 10 healthy volunteers and 8 patients with cardiovascular disease (CVD). We additionally create an atlas of these biomarkers using the data from the healthy volunteers. Aladdin is able to accurately track the LA wall across the cardiac cycle and characterize its motion and deformation. The overall DVF magnitude and principal strain values are significantly higher in the healthy group vs CVD patients: $2.85 \pm 1.59~mm$ and $0.09 \pm 0.05$ vs $1.96 \pm 0.74~mm$ and $0.03 \pm 0.04$, respectively. The time course of these metrics is also different in the two groups, with a more marked active contraction phase observed in the healthy cohort. Finally, utilizing the LA atlas allows us to identify regional deviations from the population distribution that may indicate focal tissue abnormalities. The proposed tool for the quantification of novel regional LA deformation biomarkers should have important clinical applications. The source code, anonymized images, generated maps and atlas are publicly available: https://github.com/cgalaz01/aladdin_cmr_la.