 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Symptom-based Machine Learning Models for the Early Detection of COVID-19: A Narrative Review
Dec 08, 2023
Despite the widespread testing protocols for COVID-19, there are still significant challenges in early detection of the disease, which is crucial for preventing its spread and optimizing patient outcomes. Owing to the limited testing capacity in resource-strapped settings and the limitations of the available traditional methods of testing, it has been established that a fast and efficient strategy is important to fully stop the virus. Machine learning models can analyze large datasets, incorporating patient-reported symptoms, clinical data, and medical imaging. Symptom-based detection methods have been developed to predict COVID-19, and they have shown promising results. In this paper, we provide an overview of the landscape of symptoms-only machine learning models for predicting COVID-19, including their performance and limitations. The review will also examine the performance of symptom-based models when compared to image-based models. Because different studies used varying datasets, methodologies, and performance metrics. Selecting the model that performs best relies on the context and objectives of the research. However, based on the results, we observed that ensemble classifier performed exceptionally well in predicting the occurrence of COVID-19 based on patient symptoms with the highest overall accuracy of 97.88%. Gradient Boosting Algorithm achieved an AUC (Area Under the Curve) of 0.90 and identified key features contributing to the decision-making process. Image-based models, as observed in the analyzed studies, have consistently demonstrated higher accuracy than symptom-based models, often reaching impressive levels ranging from 96.09% to as high as 99%.
Generative Network Layer for Communication Systems with Artificial Intelligence
Dec 08, 2023The traditional role of the network layer is the transfer of packet replicas from source to destination through intermediate network nodes. We present a generative network layer that uses Generative AI (GenAI) at intermediate or edge network nodes and analyze its impact on the required data rates in the network. We conduct a case study where the GenAI-aided nodes generate images from prompts that consist of substantially compressed latent representations. The results from network flow analyses under image quality constraints show that the generative network layer can achieve an improvement of more than 100% in terms of the required data rate.
An Overview of MLCommons Cloud Mask Benchmark: Related Research and Data
Dec 08, 2023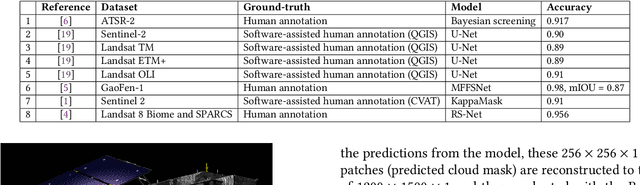
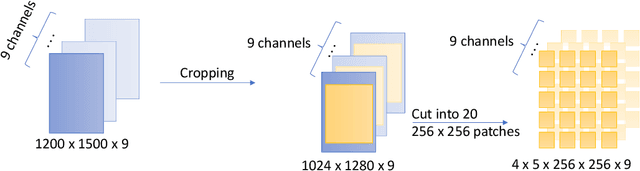
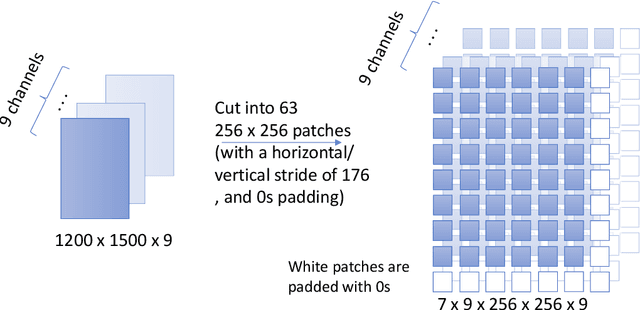
Cloud masking is a crucial task that is well-motivated for meteorology and its applications in environmental and atmospheric sciences. Its goal is, given satellite images, to accurately generate cloud masks that identify each pixel in image to contain either cloud or clear sky. In this paper, we summarize some of the ongoing research activities in cloud masking, with a focus on the research and benchmark currently conducted in MLCommons Science Working Group. This overview is produced with the hope that others will have an easier time getting started and collaborate on the activities related to MLCommons Cloud Mask Benchmark.
Suppression of the Talbot effect in Fourier transform acousto-optic imaging
Dec 01, 2023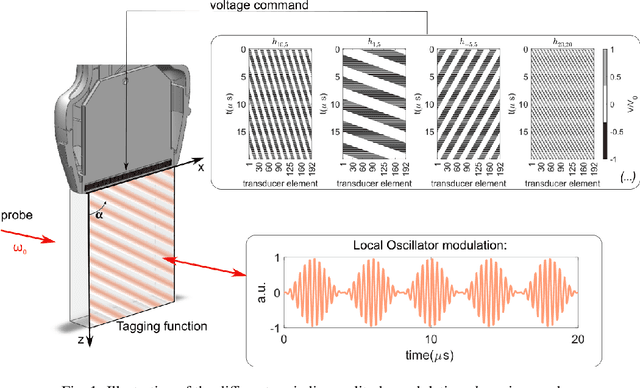
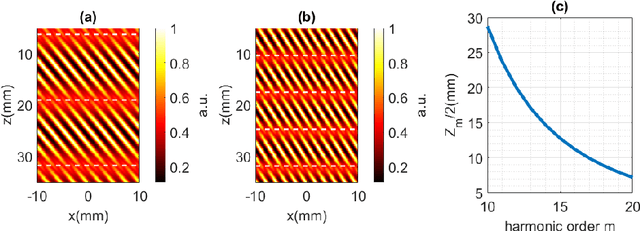
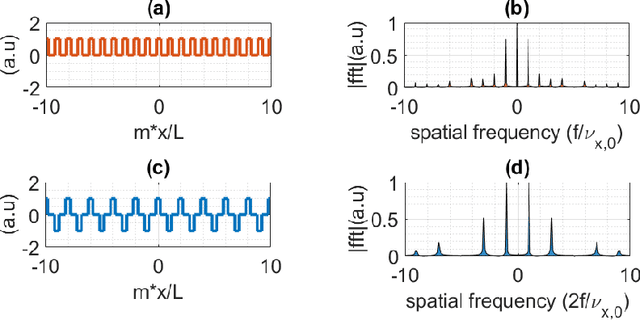
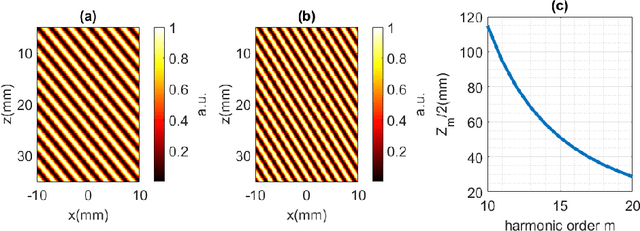
We report on the observation and correction of an imaging artifact attributed to the Talbot effect in the context of acousto-optic imaging using structured acoustic waves. When ultrasound waves are emitted with a periodic structure, the Talbot effect produces $\pi$ -phase shifts of that periodic structure at every half of the Talbot distance in propagation. This unwanted artifact is detrimental to the image reconstruction, which assumes near-field diffraction is negligible. Here, we demonstrate both theoretically and experimentally how imposing an additional phase modulation on the acoustic periodic structure induces a symmetry constraint leading to the annihilation of the Talbot effect. This will significantly improve the acousto-optic image reconstruction quality and allows for an improvement of the reachable spatial resolution of the image.
Meta ControlNet: Enhancing Task Adaptation via Meta Learning
Dec 03, 2023Diffusion-based image synthesis has attracted extensive attention recently. In particular, ControlNet that uses image-based prompts exhibits powerful capability in image tasks such as canny edge detection and generates images well aligned with these prompts. However, vanilla ControlNet generally requires extensive training of around 5000 steps to achieve a desirable control for a single task. Recent context-learning approaches have improved its adaptability, but mainly for edge-based tasks, and rely on paired examples. Thus, two important open issues are yet to be addressed to reach the full potential of ControlNet: (i) zero-shot control for certain tasks and (ii) faster adaptation for non-edge-based tasks. In this paper, we introduce a novel Meta ControlNet method, which adopts the task-agnostic meta learning technique and features a new layer freezing design. Meta ControlNet significantly reduces learning steps to attain control ability from 5000 to 1000. Further, Meta ControlNet exhibits direct zero-shot adaptability in edge-based tasks without any finetuning, and achieves control within only 100 finetuning steps in more complex non-edge tasks such as Human Pose, outperforming all existing methods. The codes is available in https://github.com/JunjieYang97/Meta-ControlNet.
Radio Signal Classification by Adversarially Robust Quantum Machine Learning
Dec 13, 2023Radio signal classification plays a pivotal role in identifying the modulation scheme used in received radio signals, which is essential for demodulation and proper interpretation of the transmitted information. Researchers have underscored the high susceptibility of ML algorithms for radio signal classification to adversarial attacks. Such vulnerability could result in severe consequences, including misinterpretation of critical messages, interception of classified information, or disruption of communication channels. Recent advancements in quantum computing have revolutionized theories and implementations of computation, bringing the unprecedented development of Quantum Machine Learning (QML). It is shown that quantum variational classifiers (QVCs) provide notably enhanced robustness against classical adversarial attacks in image classification. However, no research has yet explored whether QML can similarly mitigate adversarial threats in the context of radio signal classification. This work applies QVCs to radio signal classification and studies their robustness to various adversarial attacks. We also propose the novel application of the approximate amplitude encoding (AAE) technique to encode radio signal data efficiently. Our extensive simulation results present that attacks generated on QVCs transfer well to CNN models, indicating that these adversarial examples can fool neural networks that they are not explicitly designed to attack. However, the converse is not true. QVCs primarily resist the attacks generated on CNNs. Overall, with comprehensive simulations, our results shed new light on the growing field of QML by bridging knowledge gaps in QAML in radio signal classification and uncovering the advantages of applying QML methods in practical applications.
BESTMVQA: A Benchmark Evaluation System for Medical Visual Question Answering
Dec 13, 2023Medical Visual Question Answering (Med-VQA) is a very important task in healthcare industry, which answers a natural language question with a medical image. Existing VQA techniques in information systems can be directly applied to solving the task. However, they often suffer from (i) the data insufficient problem, which makes it difficult to train the state of the arts (SOTAs) for the domain-specific task, and (ii) the reproducibility problem, that many existing models have not been thoroughly evaluated in a unified experimental setup. To address these issues, this paper develops a Benchmark Evaluation SysTem for Medical Visual Question Answering, denoted by BESTMVQA. Given self-collected clinical data, our system provides a useful tool for users to automatically build Med-VQA datasets, which helps overcoming the data insufficient problem. Users also can conveniently select a wide spectrum of SOTA models from our model library to perform a comprehensive empirical study. With simple configurations, our system automatically trains and evaluates the selected models over a benchmark dataset, and reports the comprehensive results for users to develop new techniques or perform medical practice. Limitations of existing work are overcome (i) by the data generation tool, which automatically constructs new datasets from unstructured clinical data, and (ii) by evaluating SOTAs on benchmark datasets in a unified experimental setup. The demonstration video of our system can be found at https://youtu.be/QkEeFlu1x4A. Our code and data will be available soon.
Language-Informed Visual Concept Learning
Dec 06, 2023Our understanding of the visual world is centered around various concept axes, characterizing different aspects of visual entities. While different concept axes can be easily specified by language, e.g. color, the exact visual nuances along each axis often exceed the limitations of linguistic articulations, e.g. a particular style of painting. In this work, our goal is to learn a language-informed visual concept representation, by simply distilling large pre-trained vision-language models. Specifically, we train a set of concept encoders to encode the information pertinent to a set of language-informed concept axes, with an objective of reproducing the input image through a pre-trained Text-to-Image (T2I) model. To encourage better disentanglement of different concept encoders, we anchor the concept embeddings to a set of text embeddings obtained from a pre-trained Visual Question Answering (VQA) model. At inference time, the model extracts concept embeddings along various axes from new test images, which can be remixed to generate images with novel compositions of visual concepts. With a lightweight test-time finetuning procedure, it can also generalize to novel concepts unseen at training.
Improving the Generalization of Segmentation Foundation Model under Distribution Shift via Weakly Supervised Adaptation
Dec 06, 2023The success of large language models has inspired the computer vision community to explore image segmentation foundation model that is able to zero/few-shot generalize through prompt engineering. Segment-Anything(SAM), among others, is the state-of-the-art image segmentation foundation model demonstrating strong zero/few-shot generalization. Despite the success, recent studies reveal the weakness of SAM under strong distribution shift. In particular, SAM performs awkwardly on corrupted natural images, camouflaged images, medical images, etc. Motivated by the observations, we aim to develop a self-training based strategy to adapt SAM to target distribution. Given the unique challenges of large source dataset, high computation cost and incorrect pseudo label, we propose a weakly supervised self-training architecture with anchor regularization and low-rank finetuning to improve the robustness and computation efficiency of adaptation. We validate the effectiveness on 5 types of downstream segmentation tasks including natural clean/corrupted images, medical images, camouflaged images and robotic images. Our proposed method is task-agnostic in nature and outperforms pre-trained SAM and state-of-the-art domain adaptation methods on almost all downstream tasks with the same testing prompt inputs.
Invariant Representation Learning via Decoupling Style and Spurious Features
Dec 11, 2023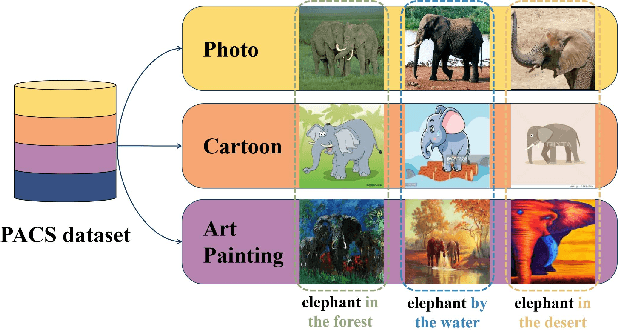
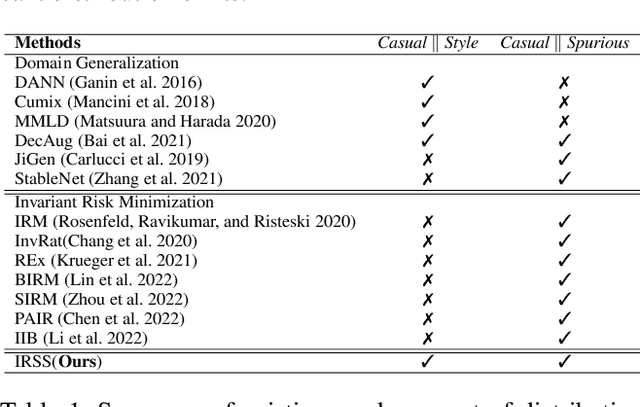
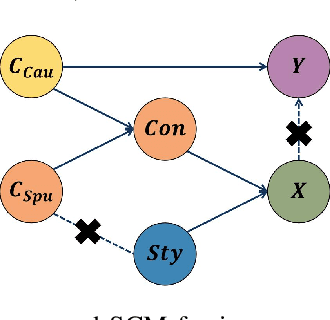
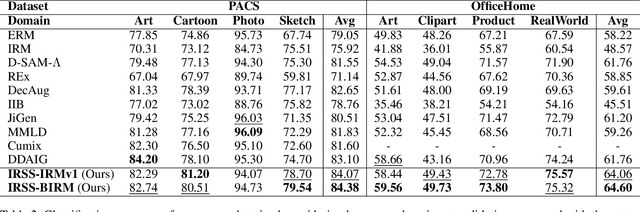
This paper considers the out-of-distribution (OOD) generalization problem under the setting that both style distribution shift and spurious features exist and domain labels are missing. This setting frequently arises in real-world applications and is underlooked because previous approaches mainly handle either of these two factors. The critical challenge is decoupling style and spurious features in the absence of domain labels. To address this challenge, we first propose a structural causal model (SCM) for the image generation process, which captures both style distribution shift and spurious features. The proposed SCM enables us to design a new framework called IRSS, which can gradually separate style distribution and spurious features from images by introducing adversarial neural networks and multi-environment optimization, thus achieving OOD generalization. Moreover, it does not require additional supervision (e.g., domain labels) other than the images and their corresponding labels. Experiments on benchmark datasets demonstrate that IRSS outperforms traditional OOD methods and solves the problem of Invariant risk minimization (IRM) degradation, enabling the extraction of invariant features under distribution shift.