 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Clean-image Backdoor Attacks
Mar 26, 2024
To gather a significant quantity of annotated training data for high-performance image classification models, numerous companies opt to enlist third-party providers to label their unlabeled data. This practice is widely regarded as secure, even in cases where some annotated errors occur, as the impact of these minor inaccuracies on the final performance of the models is negligible and existing backdoor attacks require attacker's ability to poison the training images. Nevertheless, in this paper, we propose clean-image backdoor attacks which uncover that backdoors can still be injected via a fraction of incorrect labels without modifying the training images. Specifically, in our attacks, the attacker first seeks a trigger feature to divide the training images into two parts: those with the feature and those without it. Subsequently, the attacker falsifies the labels of the former part to a backdoor class. The backdoor will be finally implanted into the target model after it is trained on the poisoned data. During the inference phase, the attacker can activate the backdoor in two ways: slightly modifying the input image to obtain the trigger feature, or taking an image that naturally has the trigger feature as input. We conduct extensive experiments to demonstrate the effectiveness and practicality of our attacks. According to the experimental results, we conclude that our attacks seriously jeopardize the fairness and robustness of image classification models, and it is necessary to be vigilant about the incorrect labels in outsourced labeling.
Meply: A Large-scale Dataset and Baseline Evaluations for Metastatic Perirectal Lymph Node Detection and Segmentation
Apr 13, 2024Accurate segmentation of metastatic lymph nodes in rectal cancer is crucial for the staging and treatment of rectal cancer. However, existing segmentation approaches face challenges due to the absence of pixel-level annotated datasets tailored for lymph nodes around the rectum. Additionally, metastatic lymph nodes are characterized by their relatively small size, irregular shapes, and lower contrast compared to the background, further complicating the segmentation task. To address these challenges, we present the first large-scale perirectal metastatic lymph node CT image dataset called Meply, which encompasses pixel-level annotations of 269 patients diagnosed with rectal cancer. Furthermore, we introduce a novel lymph-node segmentation model named CoSAM. The CoSAM utilizes sequence-based detection to guide the segmentation of metastatic lymph nodes in rectal cancer, contributing to improved localization performance for the segmentation model. It comprises three key components: sequence-based detection module, segmentation module, and collaborative convergence unit. To evaluate the effectiveness of CoSAM, we systematically compare its performance with several popular segmentation methods using the Meply dataset. Our code and dataset will be publicly available at: https://github.com/kanydao/CoSAM.
THQA: A Perceptual Quality Assessment Database for Talking Heads
Apr 13, 2024In the realm of media technology, digital humans have gained prominence due to rapid advancements in computer technology. However, the manual modeling and control required for the majority of digital humans pose significant obstacles to efficient development. The speech-driven methods offer a novel avenue for manipulating the mouth shape and expressions of digital humans. Despite the proliferation of driving methods, the quality of many generated talking head (TH) videos remains a concern, impacting user visual experiences. To tackle this issue, this paper introduces the Talking Head Quality Assessment (THQA) database, featuring 800 TH videos generated through 8 diverse speech-driven methods. Extensive experiments affirm the THQA database's richness in character and speech features. Subsequent subjective quality assessment experiments analyze correlations between scoring results and speech-driven methods, ages, and genders. In addition, experimental results show that mainstream image and video quality assessment methods have limitations for the THQA database, underscoring the imperative for further research to enhance TH video quality assessment. The THQA database is publicly accessible at https://github.com/zyj-2000/THQA.
Img2Loc: Revisiting Image Geolocalization using Multi-modality Foundation Models and Image-based Retrieval-Augmented Generation
Mar 28, 2024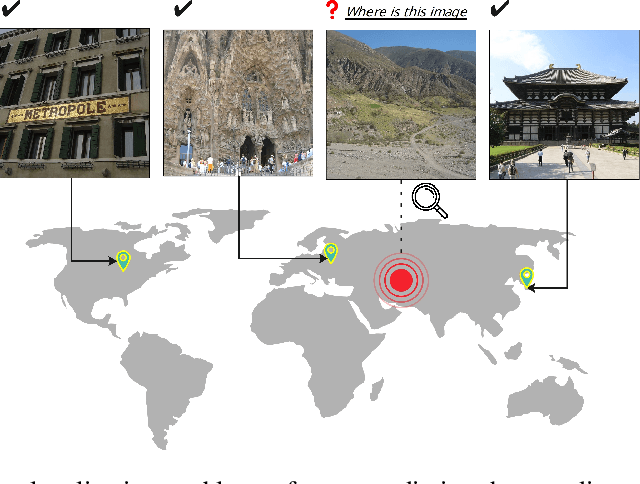
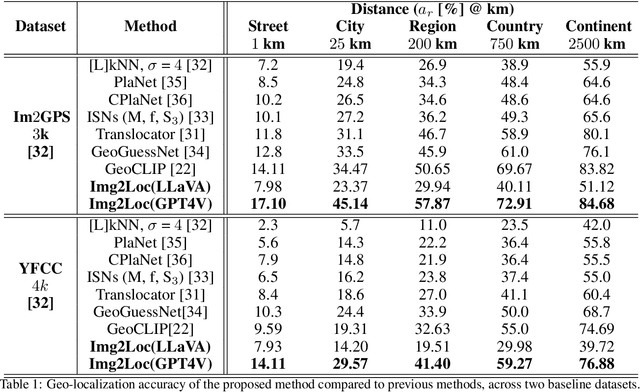
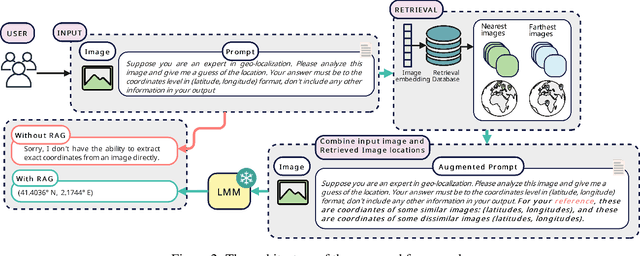
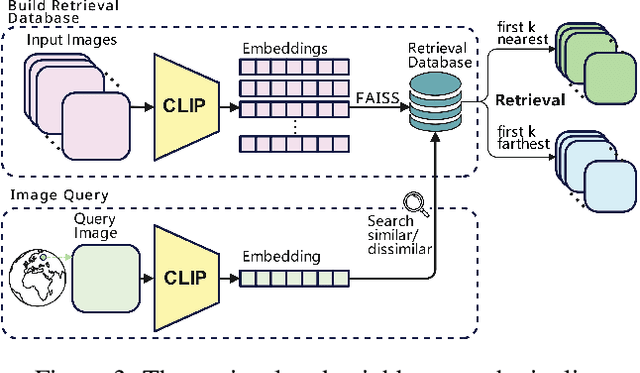
Geolocating precise locations from images presents a challenging problem in computer vision and information retrieval.Traditional methods typically employ either classification, which dividing the Earth surface into grid cells and classifying images accordingly, or retrieval, which identifying locations by matching images with a database of image-location pairs. However, classification-based approaches are limited by the cell size and cannot yield precise predictions, while retrieval-based systems usually suffer from poor search quality and inadequate coverage of the global landscape at varied scale and aggregation levels. To overcome these drawbacks, we present Img2Loc, a novel system that redefines image geolocalization as a text generation task. This is achieved using cutting-edge large multi-modality models like GPT4V or LLaVA with retrieval augmented generation. Img2Loc first employs CLIP-based representations to generate an image-based coordinate query database. It then uniquely combines query results with images itself, forming elaborate prompts customized for LMMs. When tested on benchmark datasets such as Im2GPS3k and YFCC4k, Img2Loc not only surpasses the performance of previous state-of-the-art models but does so without any model training.
Score-Based Diffusion Models for Photoacoustic Tomography Image Reconstruction
Mar 30, 2024Photoacoustic tomography (PAT) is a rapidly-evolving medical imaging modality that combines optical absorption contrast with ultrasound imaging depth. One challenge in PAT is image reconstruction with inadequate acoustic signals due to limited sensor coverage or due to the density of the transducer array. Such cases call for solving an ill-posed inverse reconstruction problem. In this work, we use score-based diffusion models to solve the inverse problem of reconstructing an image from limited PAT measurements. The proposed approach allows us to incorporate an expressive prior learned by a diffusion model on simulated vessel structures while still being robust to varying transducer sparsity conditions.
* 5 pages
Colorful Cutout: Enhancing Image Data Augmentation with Curriculum Learning
Mar 29, 2024
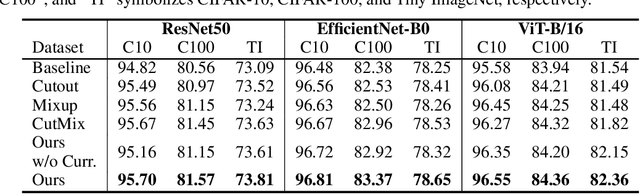

Data augmentation is one of the regularization strategies for the training of deep learning models, which enhances generalizability and prevents overfitting, leading to performance improvement. Although researchers have proposed various data augmentation techniques, they often lack consideration for the difficulty of augmented data. Recently, another line of research suggests incorporating the concept of curriculum learning with data augmentation in the field of natural language processing. In this study, we adopt curriculum data augmentation for image data augmentation and propose colorful cutout, which gradually increases the noise and difficulty introduced in the augmented image. Our experimental results highlight the possibility of curriculum data augmentation for image data. We publicly released our source code to improve the reproducibility of our study.
Visual Context-Aware Person Fall Detection
Apr 11, 2024As the global population ages, the number of fall-related incidents is on the rise. Effective fall detection systems, specifically in healthcare sector, are crucial to mitigate the risks associated with such events. This study evaluates the role of visual context, including background objects, on the accuracy of fall detection classifiers. We present a segmentation pipeline to semi-automatically separate individuals and objects in images. Well-established models like ResNet-18, EfficientNetV2-S, and Swin-Small are trained and evaluated. During training, pixel-based transformations are applied to segmented objects, and the models are then evaluated on raw images without segmentation. Our findings highlight the significant influence of visual context on fall detection. The application of Gaussian blur to the image background notably improves the performance and generalization capabilities of all models. Background objects such as beds, chairs, or wheelchairs can challenge fall detection systems, leading to false positive alarms. However, we demonstrate that object-specific contextual transformations during training effectively mitigate this challenge. Further analysis using saliency maps supports our observation that visual context is crucial in classification tasks. We create both dataset processing API and segmentation pipeline, available at https://github.com/A-NGJ/image-segmentation-cli.
Reconstructing Hand-Held Objects in 3D
Apr 10, 2024Objects manipulated by the hand (i.e., manipulanda) are particularly challenging to reconstruct from in-the-wild RGB images or videos. Not only does the hand occlude much of the object, but also the object is often only visible in a small number of image pixels. At the same time, two strong anchors emerge in this setting: (1) estimated 3D hands help disambiguate the location and scale of the object, and (2) the set of manipulanda is small relative to all possible objects. With these insights in mind, we present a scalable paradigm for handheld object reconstruction that builds on recent breakthroughs in large language/vision models and 3D object datasets. Our model, MCC-Hand-Object (MCC-HO), jointly reconstructs hand and object geometry given a single RGB image and inferred 3D hand as inputs. Subsequently, we use GPT-4(V) to retrieve a 3D object model that matches the object in the image and rigidly align the model to the network-inferred geometry; we call this alignment Retrieval-Augmented Reconstruction (RAR). Experiments demonstrate that MCC-HO achieves state-of-the-art performance on lab and Internet datasets, and we show how RAR can be used to automatically obtain 3D labels for in-the-wild images of hand-object interactions.
EPL: Evidential Prototype Learning for Semi-supervised Medical Image Segmentation
Apr 09, 2024Although current semi-supervised medical segmentation methods can achieve decent performance, they are still affected by the uncertainty in unlabeled data and model predictions, and there is currently a lack of effective strategies that can explore the uncertain aspects of both simultaneously. To address the aforementioned issues, we propose Evidential Prototype Learning (EPL), which utilizes an extended probabilistic framework to effectively fuse voxel probability predictions from different sources and achieves prototype fusion utilization of labeled and unlabeled data under a generalized evidential framework, leveraging voxel-level dual uncertainty masking. The uncertainty not only enables the model to self-correct predictions but also improves the guided learning process with pseudo-labels and is able to feed back into the construction of hidden features. The method proposed in this paper has been experimented on LA, Pancreas-CT and TBAD datasets, achieving the state-of-the-art performance in three different labeled ratios, which strongly demonstrates the effectiveness of our strategy.
Taming Lookup Tables for Efficient Image Retouching
Mar 28, 2024The widespread use of high-definition screens in edge devices, such as end-user cameras, smartphones, and televisions, is spurring a significant demand for image enhancement. Existing enhancement models often optimize for high performance while falling short of reducing hardware inference time and power consumption, especially on edge devices with constrained computing and storage resources. To this end, we propose Image Color Enhancement Lookup Table (ICELUT) that adopts LUTs for extremely efficient edge inference, without any convolutional neural network (CNN). During training, we leverage pointwise (1x1) convolution to extract color information, alongside a split fully connected layer to incorporate global information. Both components are then seamlessly converted into LUTs for hardware-agnostic deployment. ICELUT achieves near-state-of-the-art performance and remarkably low power consumption. We observe that the pointwise network structure exhibits robust scalability, upkeeping the performance even with a heavily downsampled 32x32 input image. These enable ICELUT, the first-ever purely LUT-based image enhancer, to reach an unprecedented speed of 0.4ms on GPU and 7ms on CPU, at least one order faster than any CNN solution. Codes are available at https://github.com/Stephen0808/ICELUT.