 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Universal Incomplete-View CT Reconstruction with Prompted Contextual Transformer
Dec 13, 2023
Despite the reduced radiation dose, suitability for objects with physical constraints, and accelerated scanning procedure, incomplete-view computed tomography (CT) images suffer from severe artifacts, hampering their value for clinical diagnosis. The incomplete-view CT can be divided into two scenarios depending on the sampling of projection, sparse-view CT and limited-angle CT, each encompassing various settings for different clinical requirements. Existing methods tackle with these settings separately and individually due to their significantly different artifact patterns; this, however, gives rise to high computational and storage costs, hindering its flexible adaptation to new settings. To address this challenge, we present the first-of-its-kind all-in-one incomplete-view CT reconstruction model with PROmpted Contextual Transformer, termed ProCT. More specifically, we first devise the projection view-aware prompting to provide setting-discriminative information, enabling a single model to handle diverse incomplete-view CT settings. Then, we propose artifact-aware contextual learning to provide the contextual guidance of image pairs from either CT phantom or publicly available datasets, making ProCT capable of accurately removing the complex artifacts from the incomplete-view CT images. Extensive experiments demonstrate that ProCT can achieve superior performance on a wide range of incomplete-view CT settings using a single model. Remarkably, our model with only image-domain information surpasses the state-of-the-art dual-domain methods that require the access to raw data. The code is available at: https://github.com/Masaaki-75/proct
GPT4SGG: Synthesizing Scene Graphs from Holistic and Region-specific Narratives
Dec 07, 2023Learning scene graphs from natural language descriptions has proven to be a cheap and promising scheme for Scene Graph Generation (SGG). However, such unstructured caption data and its processing are troubling the learning an acurrate and complete scene graph. This dilema can be summarized as three points. First, traditional language parsers often fail to extract meaningful relationship triplets from caption data. Second, grounding unlocalized objects in parsed triplets will meet ambiguity in visual-language alignment. Last, caption data typically are sparse and exhibit bias to partial observations of image content. These three issues make it hard for the model to generate comprehensive and accurate scene graphs. To fill this gap, we propose a simple yet effective framework, GPT4SGG, to synthesize scene graphs from holistic and region-specific narratives. The framework discards traditional language parser, and localize objects before obtaining relationship triplets. To obtain relationship triplets, holistic and dense region-specific narratives are generated from the image. With such textual representation of image data and a task-specific prompt, an LLM, particularly GPT-4, directly synthesizes a scene graph as "pseudo labels". Experimental results showcase GPT4SGG significantly improves the performance of SGG models trained on image-caption data. We believe this pioneering work can motivate further research into mining the visual reasoning capabilities of LLMs.
Catastrophic Forgetting in Deep Learning: A Comprehensive Taxonomy
Dec 16, 2023Deep Learning models have achieved remarkable performance in tasks such as image classification or generation, often surpassing human accuracy. However, they can struggle to learn new tasks and update their knowledge without access to previous data, leading to a significant loss of accuracy known as Catastrophic Forgetting (CF). This phenomenon was first observed by McCloskey and Cohen in 1989 and remains an active research topic. Incremental learning without forgetting is widely recognized as a crucial aspect in building better AI systems, as it allows models to adapt to new tasks without losing the ability to perform previously learned ones. This article surveys recent studies that tackle CF in modern Deep Learning models that use gradient descent as their learning algorithm. Although several solutions have been proposed, a definitive solution or consensus on assessing CF is yet to be established. The article provides a comprehensive review of recent solutions, proposes a taxonomy to organize them, and identifies research gaps in this area.
VDIP-TGV: Blind Image Deconvolution via Variational Deep Image Prior Empowered by Total Generalized Variation
Oct 30, 2023Recovering clear images from blurry ones with an unknown blur kernel is a challenging problem. Deep image prior (DIP) proposes to use the deep network as a regularizer for a single image rather than as a supervised model, which achieves encouraging results in the nonblind deblurring problem. However, since the relationship between images and the network architectures is unclear, it is hard to find a suitable architecture to provide sufficient constraints on the estimated blur kernels and clean images. Also, DIP uses the sparse maximum a posteriori (MAP), which is insufficient to enforce the selection of the recovery image. Recently, variational deep image prior (VDIP) was proposed to impose constraints on both blur kernels and recovery images and take the standard deviation of the image into account during the optimization process by the variational principle. However, we empirically find that VDIP struggles with processing image details and tends to generate suboptimal results when the blur kernel is large. Therefore, we combine total generalized variational (TGV) regularization with VDIP in this paper to overcome these shortcomings of VDIP. TGV is a flexible regularization that utilizes the characteristics of partial derivatives of varying orders to regularize images at different scales, reducing oil painting artifacts while maintaining sharp edges. The proposed VDIP-TGV effectively recovers image edges and details by supplementing extra gradient information through TGV. Additionally, this model is solved by the alternating direction method of multipliers (ADMM), which effectively combines traditional algorithms and deep learning methods. Experiments show that our proposed VDIP-TGV surpasses various state-of-the-art models quantitatively and qualitatively.
QuickQuakeBuildings: Post-earthquake SAR-Optical Dataset for Quick Damaged-building Detection
Dec 11, 2023

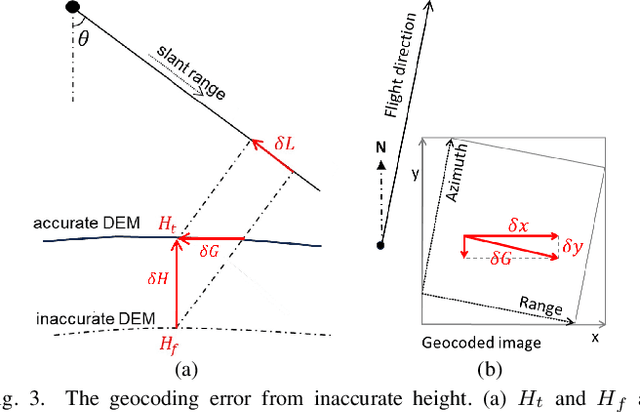
Quick and automated earthquake-damaged building detection from post-event satellite imagery is crucial, yet it is challenging due to the scarcity of training data required to develop robust algorithms. This letter presents the first dataset dedicated to detecting earthquake-damaged buildings from post-event very high resolution (VHR) Synthetic Aperture Radar (SAR) and optical imagery. Utilizing open satellite imagery and annotations acquired after the 2023 Turkey-Syria earthquakes, we deliver a dataset of coregistered building footprints and satellite image patches of both SAR and optical data, encompassing more than four thousand buildings. The task of damaged building detection is formulated as a binary image classification problem, that can also be treated as an anomaly detection problem due to extreme class imbalance. We provide baseline methods and results to serve as references for comparison. Researchers can utilize this dataset to expedite algorithm development, facilitating the rapid detection of damaged buildings in response to future events. The dataset and codes together with detailed explanations are made publicly available at \url{https://github.com/ya0-sun/PostEQ-SARopt-BuildingDamage}.
NutritionVerse-Synth: An Open Access Synthetically Generated 2D Food Scene Dataset for Dietary Intake Estimation
Dec 11, 2023Manually tracking nutritional intake via food diaries is error-prone and burdensome. Automated computer vision techniques show promise for dietary monitoring but require large and diverse food image datasets. To address this need, we introduce NutritionVerse-Synth (NV-Synth), a large-scale synthetic food image dataset. NV-Synth contains 84,984 photorealistic meal images rendered from 7,082 dynamically plated 3D scenes. Each scene is captured from 12 viewpoints and includes perfect ground truth annotations such as RGB, depth, semantic, instance, and amodal segmentation masks, bounding boxes, and detailed nutritional information per food item. We demonstrate the diversity of NV-Synth across foods, compositions, viewpoints, and lighting. As the largest open-source synthetic food dataset, NV-Synth highlights the value of physics-based simulations for enabling scalable and controllable generation of diverse photorealistic meal images to overcome data limitations and drive advancements in automated dietary assessment using computer vision. In addition to the dataset, the source code for our data generation framework is also made publicly available at https://saeejithnair.github.io/nvsynth.
Movement Primitive Diffusion: Learning Gentle Robotic Manipulation of Deformable Objects
Dec 15, 2023Policy learning in robot-assisted surgery (RAS) lacks data efficient and versatile methods that exhibit the desired motion quality for delicate surgical interventions. To this end, we introduce Movement Primitive Diffusion (MPD), a novel method for imitation learning (IL) in RAS that focuses on gentle manipulation of deformable objects. The approach combines the versatility of diffusion-based imitation learning (DIL) with the high-quality motion generation capabilities of Probabilistic Dynamic Movement Primitives (ProDMPs). This combination enables MPD to achieve gentle manipulation of deformable objects, while maintaining data efficiency critical for RAS applications where demonstration data is scarce. We evaluate MPD across various simulated tasks and a real world robotic setup on both state and image observations. MPD outperforms state-of-the-art DIL methods in success rate, motion quality, and data efficiency.
COVIDx CXR-4: An Expanded Multi-Institutional Open-Source Benchmark Dataset for Chest X-ray Image-Based Computer-Aided COVID-19 Diagnostics
Nov 29, 2023The global ramifications of the COVID-19 pandemic remain significant, exerting persistent pressure on nations even three years after its initial outbreak. Deep learning models have shown promise in improving COVID-19 diagnostics but require diverse and larger-scale datasets to improve performance. In this paper, we introduce COVIDx CXR-4, an expanded multi-institutional open-source benchmark dataset for chest X-ray image-based computer-aided COVID-19 diagnostics. COVIDx CXR-4 expands significantly on the previous COVIDx CXR-3 dataset by increasing the total patient cohort size by greater than 2.66 times, resulting in 84,818 images from 45,342 patients across multiple institutions. We provide extensive analysis on the diversity of the patient demographic, imaging metadata, and disease distributions to highlight potential dataset biases. To the best of the authors' knowledge, COVIDx CXR-4 is the largest and most diverse open-source COVID-19 CXR dataset and is made publicly available as part of an open initiative to advance research to aid clinicians against the COVID-19 disease.
An adversarial attack approach for eXplainable AI evaluation on deepfake detection models
Dec 08, 2023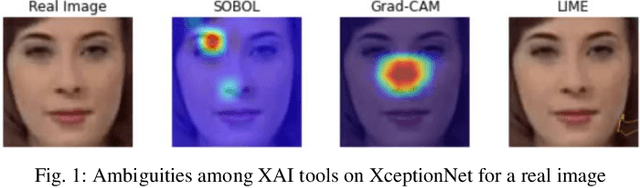


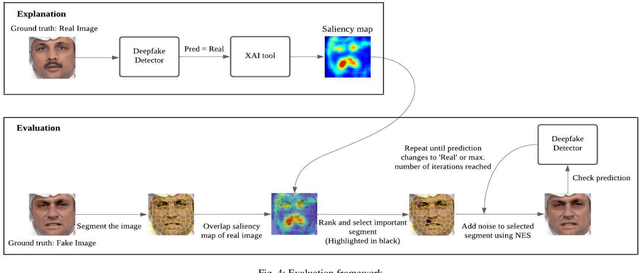
With the rising concern on model interpretability, the application of eXplainable AI (XAI) tools on deepfake detection models has been a topic of interest recently. In image classification tasks, XAI tools highlight pixels influencing the decision given by a model. This helps in troubleshooting the model and determining areas that may require further tuning of parameters. With a wide range of tools available in the market, choosing the right tool for a model becomes necessary as each one may highlight different sets of pixels for a given image. There is a need to evaluate different tools and decide the best performing ones among them. Generic XAI evaluation methods like insertion or removal of salient pixels/segments are applicable for general image classification tasks but may produce less meaningful results when applied on deepfake detection models due to their functionality. In this paper, we perform experiments to show that generic removal/insertion XAI evaluation methods are not suitable for deepfake detection models. We also propose and implement an XAI evaluation approach specifically suited for deepfake detection models.
XC-NAS: A New Cellular Encoding Approach for Neural Architecture Search of Multi-path Convolutional Neural Networks
Dec 12, 2023Convolutional Neural Networks (CNNs) continue to achieve great success in classification tasks as innovative techniques and complex multi-path architecture topologies are introduced. Neural Architecture Search (NAS) aims to automate the design of these complex architectures, reducing the need for costly manual design work by human experts. Cellular Encoding (CE) is an evolutionary computation technique which excels in constructing novel multi-path topologies of varying complexity and has recently been applied with NAS to evolve CNN architectures for various classification tasks. However, existing CE approaches have severe limitations. They are restricted to only one domain, only partially implement the theme of CE, or only focus on the micro-architecture search space. This paper introduces a new CE representation and algorithm capable of evolving novel multi-path CNN architectures of varying depth, width, and complexity for image and text classification tasks. The algorithm explicitly focuses on the macro-architecture search space. Furthermore, by using a surrogate model approach, we show that the algorithm can evolve a performant CNN architecture in less than one GPU day, thereby allowing a sufficient number of experiment runs to be conducted to achieve scientific robustness. Experiment results show that the approach is highly competitive, defeating several state-of-the-art methods, and is generalisable to both the image and text domains.