 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Learning transformer-based heterogeneously salient graph representation for multimodal fusion classification of hyperspectral image and LiDAR data
Nov 17, 2023
Data collected by different modalities can provide a wealth of complementary information, such as hyperspectral image (HSI) to offer rich spectral-spatial properties, synthetic aperture radar (SAR) to provide structural information about the Earth's surface, and light detection and ranging (LiDAR) to cover altitude information about ground elevation. Therefore, a natural idea is to combine multimodal images for refined and accurate land-cover interpretation. Although many efforts have been attempted to achieve multi-source remote sensing image classification, there are still three issues as follows: 1) indiscriminate feature representation without sufficiently considering modal heterogeneity, 2) abundant features and complex computations associated with modeling long-range dependencies, and 3) overfitting phenomenon caused by sparsely labeled samples. To overcome the above barriers, a transformer-based heterogeneously salient graph representation (THSGR) approach is proposed in this paper. First, a multimodal heterogeneous graph encoder is presented to encode distinctively non-Euclidean structural features from heterogeneous data. Then, a self-attention-free multi-convolutional modulator is designed for effective and efficient long-term dependency modeling. Finally, a mean forward is put forward in order to avoid overfitting. Based on the above structures, the proposed model is able to break through modal gaps to obtain differentiated graph representation with competitive time cost, even for a small fraction of training samples. Experiments and analyses on three benchmark datasets with various state-of-the-art (SOTA) methods show the performance of the proposed approach.
Lego: Learning to Disentangle and Invert Concepts Beyond Object Appearance in Text-to-Image Diffusion Models
Nov 23, 2023Diffusion models have revolutionized generative content creation and text-to-image (T2I) diffusion models in particular have increased the creative freedom of users by allowing scene synthesis using natural language. T2I models excel at synthesizing concepts such as nouns, appearances, and styles. To enable customized content creation based on a few example images of a concept, methods such as Textual Inversion and DreamBooth invert the desired concept and enable synthesizing it in new scenes. However, inverting more general concepts that go beyond object appearance and style (adjectives and verbs) through natural language, remains a challenge. Two key characteristics of these concepts contribute to the limitations of current inversion methods. 1) Adjectives and verbs are entangled with nouns (subject) and can hinder appearance-based inversion methods, where the subject appearance leaks into the concept embedding and 2) describing such concepts often extends beyond single word embeddings (being frozen in ice, walking on a tightrope, etc.) that current methods do not handle. In this study, we introduce Lego, a textual inversion method designed to invert subject entangled concepts from a few example images. Lego disentangles concepts from their associated subjects using a simple yet effective Subject Separation step and employs a Context Loss that guides the inversion of single/multi-embedding concepts. In a thorough user study, Lego-generated concepts were preferred over 70% of the time when compared to the baseline. Additionally, visual question answering using a large language model suggested Lego-generated concepts are better aligned with the text description of the concept.
IMProv: Inpainting-based Multimodal Prompting for Computer Vision Tasks
Dec 04, 2023
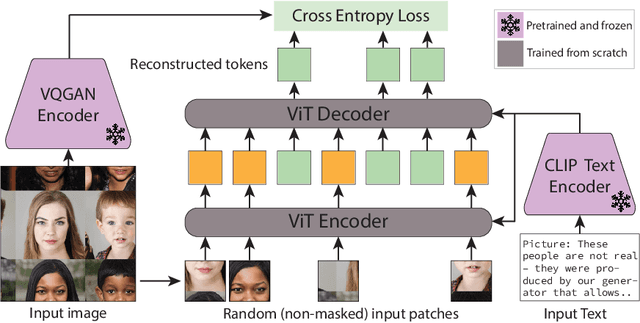
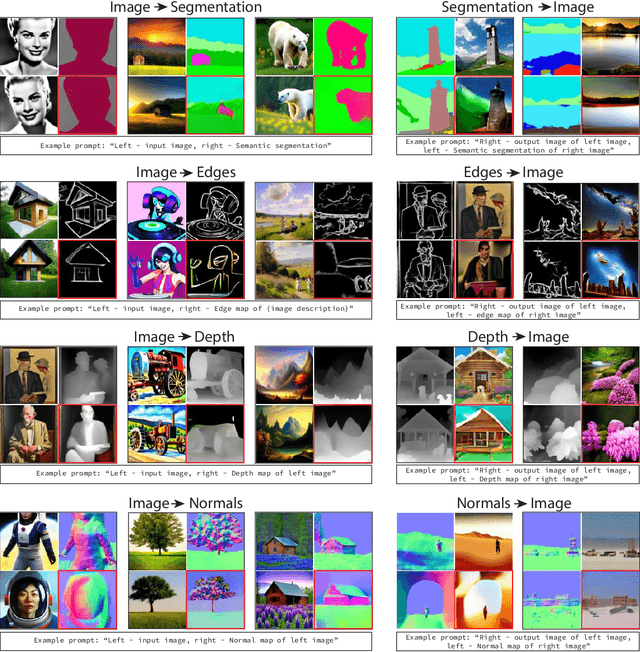

In-context learning allows adapting a model to new tasks given a task description at test time. In this paper, we present IMProv - a generative model that is able to in-context learn visual tasks from multimodal prompts. Given a textual description of a visual task (e.g. "Left: input image, Right: foreground segmentation"), a few input-output visual examples, or both, the model in-context learns to solve it for a new test input. We train a masked generative transformer on a new dataset of figures from computer vision papers and their associated captions, together with a captioned large-scale image-text dataset. During inference time, we prompt the model with text and/or image task example(s) and have the model inpaint the corresponding output. We show that training our model with text conditioning and scaling the dataset size improves in-context learning for computer vision tasks by over +10\% AP for Foreground Segmentation, over +5\% gains in AP for Single Object Detection, and almost 20\% lower LPIPS in Colorization. Our empirical results suggest that vision and language prompts are complementary and it is advantageous to use both to achieve better in-context learning performance. Project page is available at https://jerryxu.net/IMProv .
NDELS: A Novel Approach for Nighttime Dehazing, Low-Light Enhancement, and Light Suppression
Dec 11, 2023This paper tackles the intricate challenge of improving the quality of nighttime images under hazy and low-light conditions. Overcoming issues including nonuniform illumination glows, texture blurring, glow effects, color distortion, noise disturbance, and overall, low light have proven daunting. Despite the inherent difficulties, this paper introduces a pioneering solution named Nighttime Dehazing, Low-Light Enhancement, and Light Suppression (NDELS). NDELS utilizes a unique network that combines three essential processes to enhance visibility, brighten low-light regions, and effectively suppress glare from bright light sources. In contrast to limited progress in nighttime dehazing, unlike its daytime counterpart, NDELS presents a comprehensive and innovative approach. The efficacy of NDELS is rigorously validated through extensive comparisons with eight state-of-the-art algorithms across four diverse datasets. Experimental results showcase the superior performance of our method, demonstrating its outperformance in terms of overall image quality, including color and edge enhancement. Quantitative (PSNR, SSIM) and qualitative metrics (CLIPIQA, MANIQA, TRES), measure these results.
Shape Matters: Detecting Vertebral Fractures Using Differentiable Point-Based Shape Decoding
Dec 08, 2023Degenerative spinal pathologies are highly prevalent among the elderly population. Timely diagnosis of osteoporotic fractures and other degenerative deformities facilitates proactive measures to mitigate the risk of severe back pain and disability. In this study, we specifically explore the use of shape auto-encoders for vertebrae, taking advantage of advancements in automated multi-label segmentation and the availability of large datasets for unsupervised learning. Our shape auto-encoders are trained on a large set of vertebrae surface patches, leveraging the vast amount of available data for vertebra segmentation. This addresses the label scarcity problem faced when learning shape information of vertebrae from image intensities. Based on the learned shape features we train an MLP to detect vertebral body fractures. Using segmentation masks that were automatically generated using the TotalSegmentator, our proposed method achieves an AUC of 0.901 on the VerSe19 testset. This outperforms image-based and surface-based end-to-end trained models. Additionally, our results demonstrate that pre-training the models in an unsupervised manner enhances geometric methods like PointNet and DGCNN. Our findings emphasise the advantages of explicitly learning shape features for diagnosing osteoporotic vertebrae fractures. This approach improves the reliability of classification results and reduces the need for annotated labels. This study provides novel insights into the effectiveness of various encoder-decoder models for shape analysis of vertebrae and proposes a new decoder architecture: the point-based shape decoder.
HiFi Tuner: High-Fidelity Subject-Driven Fine-Tuning for Diffusion Models
Nov 30, 2023This paper explores advancements in high-fidelity personalized image generation through the utilization of pre-trained text-to-image diffusion models. While previous approaches have made significant strides in generating versatile scenes based on text descriptions and a few input images, challenges persist in maintaining the subject fidelity within the generated images. In this work, we introduce an innovative algorithm named HiFi Tuner to enhance the appearance preservation of objects during personalized image generation. Our proposed method employs a parameter-efficient fine-tuning framework, comprising a denoising process and a pivotal inversion process. Key enhancements include the utilization of mask guidance, a novel parameter regularization technique, and the incorporation of step-wise subject representations to elevate the sample fidelity. Additionally, we propose a reference-guided generation approach that leverages the pivotal inversion of a reference image to mitigate unwanted subject variations and artifacts. We further extend our method to a novel image editing task: substituting the subject in an image through textual manipulations. Experimental evaluations conducted on the DreamBooth dataset using the Stable Diffusion model showcase promising results. Fine-tuning solely on textual embeddings improves CLIP-T score by 3.6 points and improves DINO score by 9.6 points over Textual Inversion. When fine-tuning all parameters, HiFi Tuner improves CLIP-T score by 1.2 points and improves DINO score by 1.2 points over DreamBooth, establishing a new state of the art.
Make-A-Storyboard: A General Framework for Storyboard with Disentangled and Merged Control
Dec 06, 2023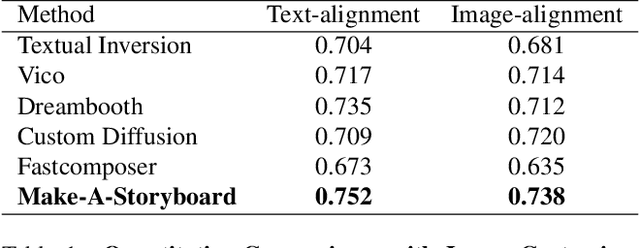
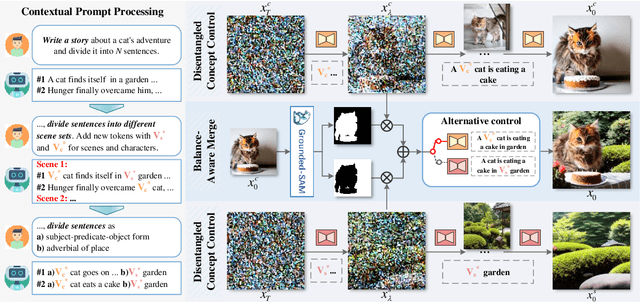


Story Visualization aims to generate images aligned with story prompts, reflecting the coherence of storybooks through visual consistency among characters and scenes.Whereas current approaches exclusively concentrate on characters and neglect the visual consistency among contextually correlated scenes, resulting in independent character images without inter-image coherence.To tackle this issue, we propose a new presentation form for Story Visualization called Storyboard, inspired by film-making, as illustrated in Fig.1.Specifically, a Storyboard unfolds a story into visual representations scene by scene. Within each scene in Storyboard, characters engage in activities at the same location, necessitating both visually consistent scenes and characters.For Storyboard, we design a general framework coined as Make-A-Storyboard that applies disentangled control over the consistency of contextual correlated characters and scenes and then merge them to form harmonized images.Extensive experiments demonstrate 1) Effectiveness.the effectiveness of the method in story alignment, character consistency, and scene correlation; 2) Generalization. Our method could be seamlessly integrated into mainstream Image Customization methods, empowering them with the capability of story visualization.
BenchLMM: Benchmarking Cross-style Visual Capability of Large Multimodal Models
Dec 06, 2023Large Multimodal Models (LMMs) such as GPT-4V and LLaVA have shown remarkable capabilities in visual reasoning with common image styles. However, their robustness against diverse style shifts, crucial for practical applications, remains largely unexplored. In this paper, we propose a new benchmark, BenchLMM, to assess the robustness of LMMs against three different styles: artistic image style, imaging sensor style, and application style, where each style has five sub-styles. Utilizing BenchLMM, we comprehensively evaluate state-of-the-art LMMs and reveal: 1) LMMs generally suffer performance degradation when working with other styles; 2) An LMM performs better than another model in common style does not guarantee its superior performance in other styles; 3) LMMs' reasoning capability can be enhanced by prompting LMMs to predict the style first, based on which we propose a versatile and training-free method for improving LMMs; 4) An intelligent LMM is expected to interpret the causes of its errors when facing stylistic variations. We hope that our benchmark and analysis can shed new light on developing more intelligent and versatile LMMs.
GCFA:Geodesic Curve Feature Augmentation via Shape Space Theory
Dec 06, 2023Deep learning has yielded remarkable outcomes in various domains. However, the challenge of requiring large-scale labeled samples still persists in deep learning. Thus, data augmentation has been introduced as a critical strategy to train deep learning models. However, data augmentation suffers from information loss and poor performance in small sample environments. To overcome these drawbacks, we propose a feature augmentation method based on shape space theory, i.e., Geodesic curve feature augmentation, called GCFA in brevity. First, we extract features from the image with the neural network model. Then, the multiple image features are projected into a pre-shape space as features. In the pre-shape space, a Geodesic curve is built to fit the features. Finally, the many generated features on the Geodesic curve are used to train the various machine learning models. The GCFA module can be seamlessly integrated with most machine learning methods. And the proposed method is simple, effective and insensitive for the small sample datasets. Several examples demonstrate that the GCFA method can greatly improve the performance of the data preprocessing model in a small sample environment.
Novel class discovery meets foundation models for 3D semantic segmentation
Dec 06, 2023The task of Novel Class Discovery (NCD) in semantic segmentation entails training a model able to accurately segment unlabelled (novel) classes, relying on the available supervision from annotated (base) classes. Although extensively investigated in 2D image data, the extension of the NCD task to the domain of 3D point clouds represents a pioneering effort, characterized by assumptions and challenges that are not present in the 2D case. This paper represents an advancement in the analysis of point cloud data in four directions. Firstly, it introduces the novel task of NCD for point cloud semantic segmentation. Secondly, it demonstrates that directly transposing the only existing NCD method for 2D image semantic segmentation to 3D data yields suboptimal results. Thirdly, a new NCD approach based on online clustering, uncertainty estimation, and semantic distillation is presented. Lastly, a novel evaluation protocol is proposed to rigorously assess the performance of NCD in point cloud semantic segmentation. Through comprehensive evaluations on the SemanticKITTI, SemanticPOSS, and S3DIS datasets, the paper demonstrates substantial superiority of the proposed method over the considered baselines.