 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Class-Prototype Conditional Diffusion Model for Continual Learning with Generative Replay
Dec 10, 2023
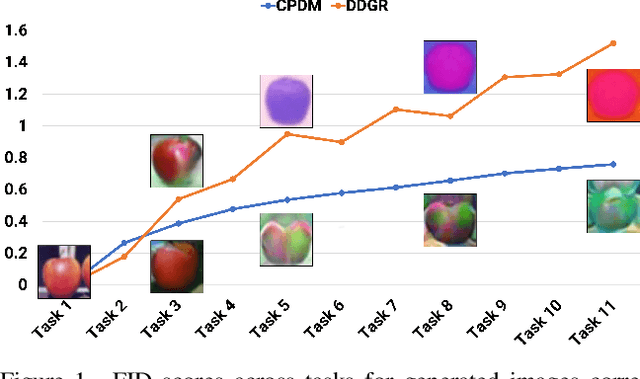
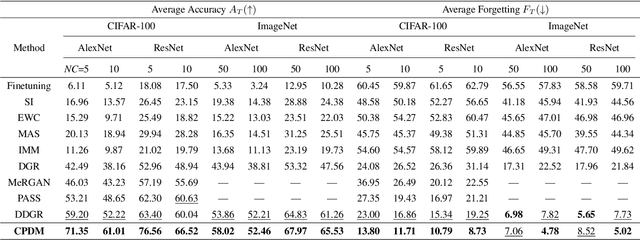
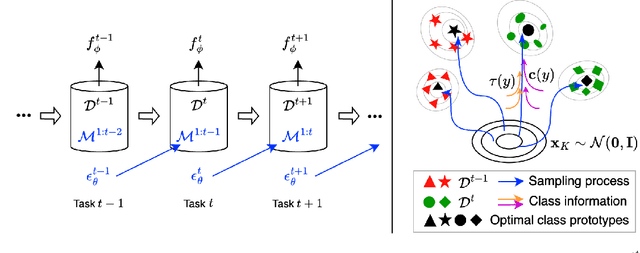
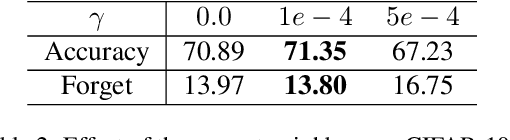
Mitigating catastrophic forgetting is a key hurdle in continual learning. Deep Generative Replay (GR) provides techniques focused on generating samples from prior tasks to enhance the model's memory capabilities. With the progression in generative AI, generative models have advanced from Generative Adversarial Networks (GANs) to the more recent Diffusion Models (DMs). A major issue is the deterioration in the quality of generated data compared to the original, as the generator continuously self-learns from its outputs. This degradation can lead to the potential risk of catastrophic forgetting occurring in the classifier. To address this, we propose the Class-Prototype Conditional Diffusion Model (CPDM), a GR-based approach for continual learning that enhances image quality in generators and thus reduces catastrophic forgetting in classifiers. The cornerstone of CPDM is a learnable class-prototype that captures the core characteristics of images in a given class. This prototype, integrated into the diffusion model's denoising process, ensures the generation of high-quality images. It maintains its effectiveness for old tasks even when new tasks are introduced, preserving image generation quality and reducing the risk of catastrophic forgetting in classifiers. Our empirical studies on diverse datasets demonstrate that our proposed method significantly outperforms existing state-of-the-art models, highlighting its exceptional ability to preserve image quality and enhance the model's memory retention.
CLIP-guided Federated Learning on Heterogeneous and Long-Tailed Data
Dec 14, 2023Federated learning (FL) provides a decentralized machine learning paradigm where a server collaborates with a group of clients to learn a global model without accessing the clients' data. User heterogeneity is a significant challenge for FL, which together with the class-distribution imbalance further enhances the difficulty of FL. Great progress has been made in large vision-language models, such as Contrastive Language-Image Pre-training (CLIP), which paves a new way for image classification and object recognition. Inspired by the success of CLIP on few-shot and zero-shot learning, we use CLIP to optimize the federated learning between server and client models under its vision-language supervision. It is promising to mitigate the user heterogeneity and class-distribution balance due to the powerful cross-modality representation and rich open-vocabulary prior knowledge. In this paper, we propose the CLIP-guided FL (CLIP2FL) method on heterogeneous and long-tailed data. In CLIP2FL, the knowledge of the off-the-shelf CLIP model is transferred to the client-server models, and a bridge is built between the client and server. Specifically, for client-side learning, knowledge distillation is conducted between client models and CLIP to improve the ability of client-side feature representation. For server-side learning, in order to mitigate the heterogeneity and class-distribution imbalance, we generate federated features to retrain the server model. A prototype contrastive learning with the supervision of the text encoder of CLIP is introduced to generate federated features depending on the client-side gradients, and they are used to retrain a balanced server classifier.
Medical Image Classification Using Transfer Learning and Chaos Game Optimization on the Internet of Medical Things
Dec 12, 2023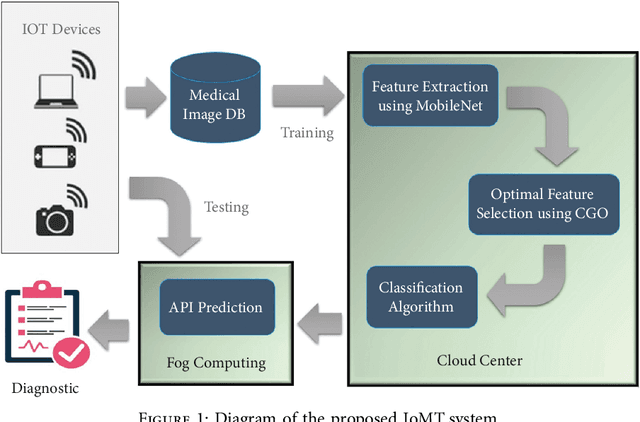
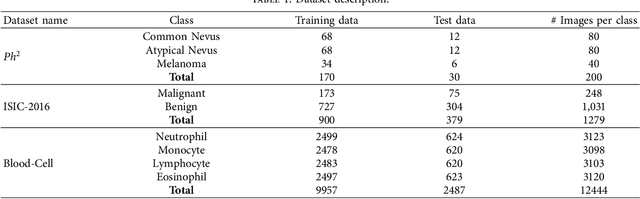
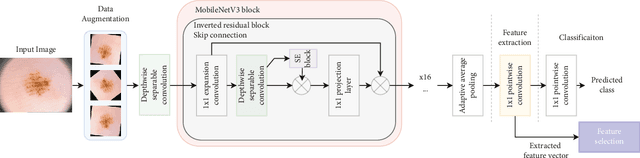

The Internet of Medical Things (IoMT) has dramatically benefited medical professionals that patients and physicians can access from all regions. Although the automatic detection and prediction of diseases such as melanoma and leukemia is still being researched and studied in IoMT, existing approaches are not able to achieve a high degree of efficiency. Thus, with a new approach that provides better results, patients would access the adequate treatments earlier and the death rate would be reduced. Therefore, this paper introduces an IoMT proposal for medical images classification that may be used anywhere, i.e. it is an ubiquitous approach. It was design in two stages: first, we employ a Transfer Learning (TL)-based method for feature extraction, which is carried out using MobileNetV3; second, we use the Chaos Game Optimization (CGO) for feature selection, with the aim of excluding unnecessary features and improving the performance, which is key in IoMT. Our methodology was evaluated using ISIC-2016, PH2, and Blood-Cell datasets. The experimental results indicated that the proposed approach obtained an accuracy of 88.39% on ISIC-2016, 97.52% on PH2, and 88.79% on Blood-cell. Moreover, our approach had successful performances for the metrics employed compared to other existing methods.
* 22 pages, 12 figures, journal
Compensation Sampling for Improved Convergence in Diffusion Models
Dec 11, 2023Diffusion models achieve remarkable quality in image generation, but at a cost. Iterative denoising requires many time steps to produce high fidelity images. We argue that the denoising process is crucially limited by an accumulation of the reconstruction error due to an initial inaccurate reconstruction of the target data. This leads to lower quality outputs, and slower convergence. To address this issue, we propose compensation sampling to guide the generation towards the target domain. We introduce a compensation term, implemented as a U-Net, which adds negligible computation overhead during training and, optionally, inference. Our approach is flexible and we demonstrate its application in unconditional generation, face inpainting, and face de-occlusion using benchmark datasets CIFAR-10, CelebA, CelebA-HQ, FFHQ-256, and FSG. Our approach consistently yields state-of-the-art results in terms of image quality, while accelerating the denoising process to converge during training by up to an order of magnitude.
RCA-NOC: Relative Contrastive Alignment for Novel Object Captioning
Dec 11, 2023In this paper, we introduce a novel approach to novel object captioning which employs relative contrastive learning to learn visual and semantic alignment. Our approach maximizes compatibility between regions and object tags in a contrastive manner. To set up a proper contrastive learning objective, for each image, we augment tags by leveraging the relative nature of positive and negative pairs obtained from foundation models such as CLIP. We then use the rank of each augmented tag in a list as a relative relevance label to contrast each top-ranked tag with a set of lower-ranked tags. This learning objective encourages the top-ranked tags to be more compatible with their image and text context than lower-ranked tags, thus improving the discriminative ability of the learned multi-modality representation. We evaluate our approach on two datasets and show that our proposed RCA-NOC approach outperforms state-of-the-art methods by a large margin, demonstrating its effectiveness in improving vision-language representation for novel object captioning.
Converting and Smoothing False Negatives for Vision-Language Pre-training
Dec 11, 2023We consider the critical issue of false negatives in Vision-Language Pre-training (VLP), a challenge that arises from the inherent many-to-many correspondence of image-text pairs in large-scale web-crawled datasets. The presence of false negatives can impede achieving optimal performance and even lead to learning failures. To address this challenge, we propose a method called COSMO (COnverting and SMOoothing false negatives) that manages the false negative issues, especially powerful in hard negative sampling. Building upon the recently developed GRouped mIni-baTch sampling (GRIT) strategy, our approach consists of two pivotal components: 1) an efficient connection mining process that identifies and converts false negatives into positives, and 2) label smoothing for the image-text contrastive loss (ITC). Our comprehensive experiments verify the effectiveness of COSMO across multiple downstream tasks, emphasizing the crucial role of addressing false negatives in VLP, potentially even surpassing the importance of addressing false positives. In addition, the compatibility of COSMO with the recent BLIP-family model is also demonstrated.
Memory-Efficient Reversible Spiking Neural Networks
Dec 13, 2023Spiking neural networks (SNNs) are potential competitors to artificial neural networks (ANNs) due to their high energy-efficiency on neuromorphic hardware. However, SNNs are unfolded over simulation time steps during the training process. Thus, SNNs require much more memory than ANNs, which impedes the training of deeper SNN models. In this paper, we propose the reversible spiking neural network to reduce the memory cost of intermediate activations and membrane potentials during training. Firstly, we extend the reversible architecture along temporal dimension and propose the reversible spiking block, which can reconstruct the computational graph and recompute all intermediate variables in forward pass with a reverse process. On this basis, we adopt the state-of-the-art SNN models to the reversible variants, namely reversible spiking ResNet (RevSResNet) and reversible spiking transformer (RevSFormer). Through experiments on static and neuromorphic datasets, we demonstrate that the memory cost per image of our reversible SNNs does not increase with the network depth. On CIFAR10 and CIFAR100 datasets, our RevSResNet37 and RevSFormer-4-384 achieve comparable accuracies and consume 3.79x and 3.00x lower GPU memory per image than their counterparts with roughly identical model complexity and parameters. We believe that this work can unleash the memory constraints in SNN training and pave the way for training extremely large and deep SNNs. The code is available at https://github.com/mi804/RevSNN.git.
EZ-CLIP: Efficient Zeroshot Video Action Recognition
Dec 13, 2023Recent advancements in large-scale pre-training of visual-language models on paired image-text data have demonstrated impressive generalization capabilities for zero-shot tasks. Building on this success, efforts have been made to adapt these image-based visual-language models, such as CLIP, for videos extending their zero-shot capabilities to the video domain. While these adaptations have shown promising results, they come at a significant computational cost and struggle with effectively modeling the crucial temporal aspects inherent to the video domain. In this study, we present EZ-CLIP, a simple and efficient adaptation of CLIP that addresses these challenges. EZ-CLIP leverages temporal visual prompting for seamless temporal adaptation, requiring no fundamental alterations to the core CLIP architecture while preserving its remarkable generalization abilities. Moreover, we introduce a novel learning objective that guides the temporal visual prompts to focus on capturing motion, thereby enhancing its learning capabilities from video data. We conducted extensive experiments on five different benchmark datasets, thoroughly evaluating EZ-CLIP for zero-shot learning and base-to-novel video action recognition, and also demonstrating its potential for few-shot generalization.Impressively, with a mere 5.2 million learnable parameters (as opposed to the 71.1 million in the prior best model), EZ-CLIP can be efficiently trained on a single GPU, outperforming existing approaches in several evaluations.
See, Say, and Segment: Teaching LMMs to Overcome False Premises
Dec 13, 2023Current open-source Large Multimodal Models (LMMs) excel at tasks such as open-vocabulary language grounding and segmentation but can suffer under false premises when queries imply the existence of something that is not actually present in the image. We observe that existing methods that fine-tune an LMM to segment images significantly degrade their ability to reliably determine ("see") if an object is present and to interact naturally with humans ("say"), a form of catastrophic forgetting. In this work, we propose a cascading and joint training approach for LMMs to solve this task, avoiding catastrophic forgetting of previous skills. Our resulting model can "see" by detecting whether objects are present in an image, "say" by telling the user if they are not, proposing alternative queries or correcting semantic errors in the query, and finally "segment" by outputting the mask of the desired objects if they exist. Additionally, we introduce a novel False Premise Correction benchmark dataset, an extension of existing RefCOCO(+/g) referring segmentation datasets (which we call FP-RefCOCO(+/g)). The results show that our method not only detects false premises up to 55% better than existing approaches, but under false premise conditions produces relative cIOU improvements of more than 31% over baselines, and produces natural language feedback judged helpful up to 67% of the time.
Multimodal Machine Learning in Image-Based and Clinical Biomedicine: Survey and Prospects
Nov 20, 2023Machine learning (ML) applications in medical artificial intelligence (AI) systems have shifted from traditional and statistical methods to increasing application of deep learning models. This survey navigates the current landscape of multimodal ML, focusing on its profound impact on medical image analysis and clinical decision support systems. Emphasizing challenges and innovations in addressing multimodal representation, fusion, translation, alignment, and co-learning, the paper explores the transformative potential of multimodal models for clinical predictions. It also questions practical implementation of such models, bringing attention to the dynamics between decision support systems and healthcare providers. Despite advancements, challenges such as data biases and the scarcity of "big data" in many biomedical domains persist. We conclude with a discussion on effective innovation and collaborative efforts to further the miss