 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Deep Internal Learning: Deep Learning from a Single Input
Dec 12, 2023
Deep learning in general focuses on training a neural network from large labeled datasets. Yet, in many cases there is value in training a network just from the input at hand. This may involve training a network from scratch using a single input or adapting an already trained network to a provided input example at inference time. This survey paper aims at covering deep internal-learning techniques that have been proposed in the past few years for these two important directions. While our main focus will be on image processing problems, most of the approaches that we survey are derived for general signals (vectors with recurring patterns that can be distinguished from noise) and are therefore applicable to other modalities. We believe that the topic of internal-learning is very important in many signal and image processing problems where training data is scarce and diversity is large on the one hand, and on the other, there is a lot of structure in the data that can be exploited.
Template Free Reconstruction of Human-object Interaction with Procedural Interaction Generation
Dec 12, 2023Reconstructing human-object interaction in 3D from a single RGB image is a challenging task and existing data driven methods do not generalize beyond the objects present in the carefully curated 3D interaction datasets. Capturing large-scale real data to learn strong interaction and 3D shape priors is very expensive due to the combinatorial nature of human-object interactions. In this paper, we propose ProciGen (Procedural interaction Generation), a method to procedurally generate datasets with both, plausible interaction and diverse object variation. We generate 1M+ human-object interaction pairs in 3D and leverage this large-scale data to train our HDM (Hierarchical Diffusion Model), a novel method to reconstruct interacting human and unseen objects, without any templates. Our HDM is an image-conditioned diffusion model that learns both realistic interaction and highly accurate human and object shapes. Experiments show that our HDM trained with ProciGen significantly outperforms prior methods that requires template meshes and that our dataset allows training methods with strong generalization ability to unseen object instances. Our code and data will be publicly released at: https://virtualhumans.mpi-inf.mpg.de/procigen-hdm.
ToViLaG: Your Visual-Language Generative Model is Also An Evildoer
Dec 13, 2023Warning: this paper includes model outputs showing offensive content. Recent large-scale Visual-Language Generative Models (VLGMs) have achieved unprecedented improvement in multimodal image/text generation. However, these models might also generate toxic content, e.g., offensive text and pornography images, raising significant ethical risks. Despite exhaustive studies on toxic degeneration of language models, this problem remains largely unexplored within the context of visual-language generation. This work delves into the propensity for toxicity generation and susceptibility to toxic data across various VLGMs. For this purpose, we built ToViLaG, a dataset comprising 32K co-toxic/mono-toxic text-image pairs and 1K innocuous but evocative text that tends to stimulate toxicity. Furthermore, we propose WInToRe, a novel toxicity metric tailored to visual-language generation, which theoretically reflects different aspects of toxicity considering both input and output. On such a basis, we benchmarked the toxicity of a diverse spectrum of VLGMs and discovered that some models do more evil than expected while some are more vulnerable to infection, underscoring the necessity of VLGMs detoxification. Therefore, we develop an innovative bottleneck-based detoxification method. Our method could reduce toxicity while maintaining comparable generation quality, providing a promising initial solution to this line of research.
Steal My Artworks for Fine-tuning? A Watermarking Framework for Detecting Art Theft Mimicry in Text-to-Image Models
Nov 22, 2023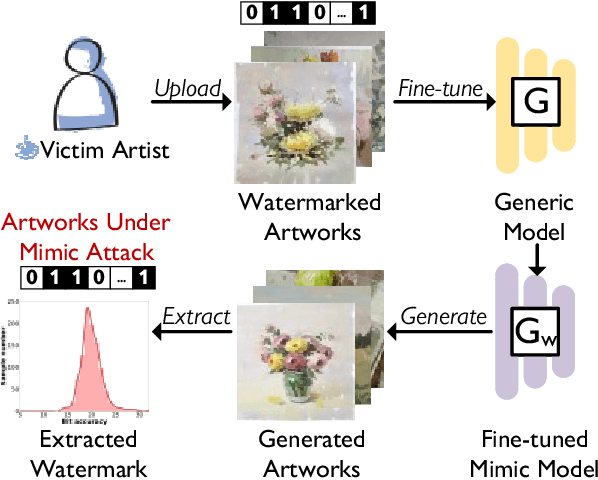
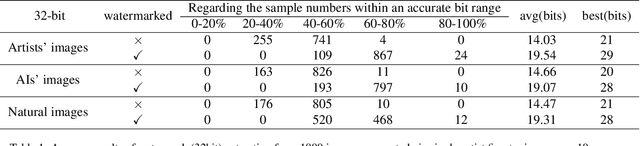
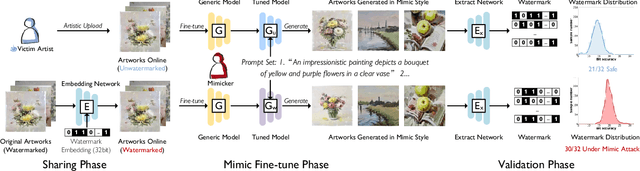
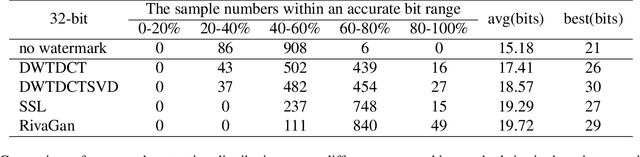
The advancement in text-to-image models has led to astonishing artistic performances. However, several studios and websites illegally fine-tune these models using artists' artworks to mimic their styles for profit, which violates the copyrights of artists and diminishes their motivation to produce original works. Currently, there is a notable lack of research focusing on this issue. In this paper, we propose a novel watermarking framework that detects mimicry in text-to-image models through fine-tuning. This framework embeds subtle watermarks into digital artworks to protect their copyrights while still preserving the artist's visual expression. If someone takes watermarked artworks as training data to mimic an artist's style, these watermarks can serve as detectable indicators. By analyzing the distribution of these watermarks in a series of generated images, acts of fine-tuning mimicry using stolen victim data will be exposed. In various fine-tune scenarios and against watermark attack methods, our research confirms that analyzing the distribution of watermarks in artificially generated images reliably detects unauthorized mimicry.
Attribute-Aware Deep Hashing with Self-Consistency for Large-Scale Fine-Grained Image Retrieval
Nov 21, 2023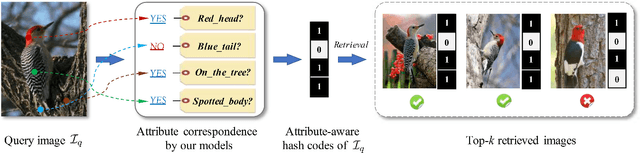
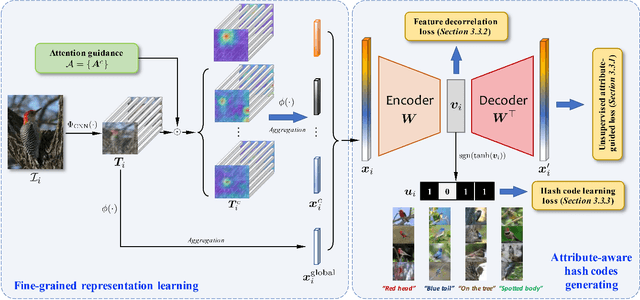


Our work focuses on tackling large-scale fine-grained image retrieval as ranking the images depicting the concept of interests (i.e., the same sub-category labels) highest based on the fine-grained details in the query. It is desirable to alleviate the challenges of both fine-grained nature of small inter-class variations with large intra-class variations and explosive growth of fine-grained data for such a practical task. In this paper, we propose attribute-aware hashing networks with self-consistency for generating attribute-aware hash codes to not only make the retrieval process efficient, but also establish explicit correspondences between hash codes and visual attributes. Specifically, based on the captured visual representations by attention, we develop an encoder-decoder structure network of a reconstruction task to unsupervisedly distill high-level attribute-specific vectors from the appearance-specific visual representations without attribute annotations. Our models are also equipped with a feature decorrelation constraint upon these attribute vectors to strengthen their representative abilities. Then, driven by preserving original entities' similarity, the required hash codes can be generated from these attribute-specific vectors and thus become attribute-aware. Furthermore, to combat simplicity bias in deep hashing, we consider the model design from the perspective of the self-consistency principle and propose to further enhance models' self-consistency by equipping an additional image reconstruction path. Comprehensive quantitative experiments under diverse empirical settings on six fine-grained retrieval datasets and two generic retrieval datasets show the superiority of our models over competing methods.
Long-MIL: Scaling Long Contextual Multiple Instance Learning for Histopathology Whole Slide Image Analysis
Nov 21, 2023Histopathology image analysis is the golden standard of clinical diagnosis for Cancers. In doctors daily routine and computer-aided diagnosis, the Whole Slide Image (WSI) of histopathology tissue is used for analysis. Because of the extremely large scale of resolution, previous methods generally divide the WSI into a large number of patches, then aggregate all patches within a WSI by Multi-Instance Learning (MIL) to make the slide-level prediction when developing computer-aided diagnosis tools. However, most previous WSI-MIL models using global-attention without pairwise interaction and any positional information, or self-attention with absolute position embedding can not well handle shape varying large WSIs, e.g. testing WSIs after model deployment may be larger than training WSIs, since the model development set is always limited due to the difficulty of histopathology WSIs collection. To deal with the problem, in this paper, we propose to amend position embedding for shape varying long-contextual WSI by introducing Linear Bias into Attention, and adapt it from 1-d long sequence into 2-d long-contextual WSI which helps model extrapolate position embedding to unseen or under-fitted positions. We further utilize Flash-Attention module to tackle the computational complexity of Transformer, which also keep full self-attention performance compared to previous attention approximation work. Our method, Long-contextual MIL (Long-MIL) are evaluated on extensive experiments including 4 dataset including WSI classification and survival prediction tasks to validate the superiority on shape varying WSIs. The source code will be open-accessed soon.
Context Disentangling and Prototype Inheriting for Robust Visual Grounding
Dec 19, 2023Visual grounding (VG) aims to locate a specific target in an image based on a given language query. The discriminative information from context is important for distinguishing the target from other objects, particularly for the targets that have the same category as others. However, most previous methods underestimate such information. Moreover, they are usually designed for the standard scene (without any novel object), which limits their generalization to the open-vocabulary scene. In this paper, we propose a novel framework with context disentangling and prototype inheriting for robust visual grounding to handle both scenes. Specifically, the context disentangling disentangles the referent and context features, which achieves better discrimination between them. The prototype inheriting inherits the prototypes discovered from the disentangled visual features by a prototype bank to fully utilize the seen data, especially for the open-vocabulary scene. The fused features, obtained by leveraging Hadamard product on disentangled linguistic and visual features of prototypes to avoid sharp adjusting the importance between the two types of features, are then attached with a special token and feed to a vision Transformer encoder for bounding box regression. Extensive experiments are conducted on both standard and open-vocabulary scenes. The performance comparisons indicate that our method outperforms the state-of-the-art methods in both scenarios. {The code is available at https://github.com/WayneTomas/TransCP.
EVI-SAM: Robust, Real-time, Tightly-coupled Event-Visual-Inertial State Estimation and 3D Dense Mapping
Dec 19, 2023Event cameras are bio-inspired, motion-activated sensors that demonstrate substantial potential in handling challenging situations, such as motion blur and high-dynamic range. In this paper, we proposed EVI-SAM to tackle the problem of 6 DoF pose tracking and 3D reconstruction using monocular event camera. A novel event-based hybrid tracking framework is designed to estimate the pose, leveraging the robustness of feature matching and the precision of direct alignment. Specifically, we develop an event-based 2D-2D alignment to construct the photometric constraint, and tightly integrate it with the event-based reprojection constraint. The mapping module recovers the dense and colorful depth of the scene through the image-guided event-based mapping method. Subsequently, the appearance, texture, and surface mesh of the 3D scene can be reconstructed by fusing the dense depth map from multiple viewpoints using truncated signed distance function (TSDF) fusion. To the best of our knowledge, this is the first non-learning work to realize event-based dense mapping. Numerical evaluations are performed on both publicly available and self-collected datasets, which qualitatively and quantitatively demonstrate the superior performance of our method. Our EVI-SAM effectively balances accuracy and robustness while maintaining computational efficiency, showcasing superior pose tracking and dense mapping performance in challenging scenarios. Video Demo: https://youtu.be/Nn40U4e5Si8.
A Powerful Face Preprocessing For Robust Kinship Verification based Tensor Analyses
Dec 18, 2023Kinship verification using facial photographs captured in the wild is difficult area of research in the science of computer vision. It might be used for a variety of applications, including image annotation and searching for missing children, etc. The largest challenge to kinship verification in practice is the fact that parent and child photos frequently differ significantly from one another. How to effectively respond to such a challenge is important improving the efficiency of kinship verification. For this purpose, we introduce a system to check relatedness that starts with a pair of face images of a child and a parent, after which it is revealed whether two people are related or not. The first step in our approach is face preprocessing with two methods, a Retinex filter and an ellipse mask, then a feature extraction step based on hist-Gabor wavelets, which is used before an efficient dimensionality reduction method called TXQDA. Finally, determine if there is a relationship. By using Cornell KinFace benchmark database, we ran a number of tests to show the efficacy of our strategy. Our findings show that, in comparison to other strategies currently in use, our system is robust.
Dirichlet-based Uncertainty Quantification for Personalized Federated Learning with Improved Posterior Networks
Dec 18, 2023In modern federated learning, one of the main challenges is to account for inherent heterogeneity and the diverse nature of data distributions for different clients. This problem is often addressed by introducing personalization of the models towards the data distribution of the particular client. However, a personalized model might be unreliable when applied to the data that is not typical for this client. Eventually, it may perform worse for these data than the non-personalized global model trained in a federated way on the data from all the clients. This paper presents a new approach to federated learning that allows selecting a model from global and personalized ones that would perform better for a particular input point. It is achieved through a careful modeling of predictive uncertainties that helps to detect local and global in- and out-of-distribution data and use this information to select the model that is confident in a prediction. The comprehensive experimental evaluation on the popular real-world image datasets shows the superior performance of the model in the presence of out-of-distribution data while performing on par with state-of-the-art personalized federated learning algorithms in the standard scenarios.