 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Attention-Challenging Multiple Instance Learning for Whole Slide Image Classification
Nov 13, 2023
Overfitting remains a significant challenge in the application of Multiple Instance Learning (MIL) methods for Whole Slide Image (WSI) analysis. Visualizing heatmaps reveals that current MIL methods focus on a subset of predictive instances, hindering effective model generalization. To tackle this, we propose Attention-Challenging MIL (ACMIL), aimed at forcing the attention mechanism to capture more challenging predictive instances. ACMIL incorporates two techniques, Multiple Branch Attention (MBA) to capture richer predictive instances and Stochastic Top-K Instance Masking (STKIM) to suppress simple predictive instances. Evaluation on three WSI datasets outperforms state-of-the-art methods. Additionally, through heatmap visualization, UMAP visualization, and attention value statistics, this paper comprehensively illustrates ACMIL's effectiveness in overcoming the overfitting challenge. The source code is available at \url{https://github.com/dazhangyu123/ACMIL}.
GIVT: Generative Infinite-Vocabulary Transformers
Dec 04, 2023We introduce generative infinite-vocabulary transformers (GIVT) which generate vector sequences with real-valued entries, instead of discrete tokens from a finite vocabulary. To this end, we propose two surprisingly simple modifications to decoder-only transformers: 1) at the input, we replace the finite-vocabulary lookup table with a linear projection of the input vectors; and 2) at the output, we replace the logits prediction (usually mapped to a categorical distribution) with the parameters of a multivariate Gaussian mixture model. Inspired by the image-generation paradigm of VQ-GAN and MaskGIT, where transformers are used to model the discrete latent sequences of a VQ-VAE, we use GIVT to model the unquantized real-valued latent sequences of a VAE. When applying GIVT to class-conditional image generation with iterative masked modeling, we show competitive results with MaskGIT, while our approach outperforms both VQ-GAN and MaskGIT when using it for causal modeling. Finally, we obtain competitive results outside of image generation when applying our approach to panoptic segmentation and depth estimation with a VAE-based variant of the UViM framework.
Mitigating Fine-Grained Hallucination by Fine-Tuning Large Vision-Language Models with Caption Rewrites
Dec 04, 2023Large language models (LLMs) have shown remarkable performance in natural language processing (NLP) tasks. To comprehend and execute diverse human instructions over image data, instruction-tuned large vision-language models (LVLMs) have been introduced. However, LVLMs may suffer from different types of object hallucinations. Nevertheless, LVLMs are evaluated for coarse-grained object hallucinations only (i.e., generated objects non-existent in the input image). The fine-grained object attributes and behaviors non-existent in the image may still be generated but not measured by the current evaluation methods. In this paper, we thus focus on reducing fine-grained hallucinations of LVLMs. We propose \textit{ReCaption}, a framework that consists of two components: rewriting captions using ChatGPT and fine-tuning the instruction-tuned LVLMs on the rewritten captions. We also propose a fine-grained probing-based evaluation method named \textit{Fine-Grained Object Hallucination Evaluation} (\textit{FGHE}). Our experiment results demonstrate that ReCaption effectively reduces fine-grained object hallucination for different LVLM options and improves their text generation quality. The code can be found at https://github.com/Anonymousanoy/FOHE.
SCLIP: Rethinking Self-Attention for Dense Vision-Language Inference
Dec 04, 2023Recent advances in contrastive language-image pretraining (CLIP) have demonstrated strong capabilities in zero-shot classification by aligning visual representations with target text embeddings in an image level. However, in dense prediction tasks, CLIP often struggles to localize visual features within an image and fails to give accurate pixel-level predictions, which prevents it from functioning as a generalized visual foundation model. In this work, we aim to enhance CLIP's potential for semantic segmentation with minimal modifications to its pretrained models. By rethinking self-attention, we surprisingly find that CLIP can adapt to dense prediction tasks by simply introducing a novel Correlative Self-Attention (CSA) mechanism. Specifically, we replace the traditional self-attention block of CLIP vision encoder's last layer by our CSA module and reuse its pretrained projection matrices of query, key, and value, leading to a training-free adaptation approach for CLIP's zero-shot semantic segmentation. Extensive experiments show the advantage of CSA: we obtain a 38.2% average zero-shot mIoU across eight semantic segmentation benchmarks highlighted in this paper, significantly outperforming the existing SoTA's 33.9% and the vanilla CLIP's 14.1%.
Light Field Imaging in the Restrictive Object Space based on Flexible Angular Plane
Dec 04, 2023In some applications, the object space of light field imaging system is restrictive, such as industrial and medical endoscopes. If the traditional light field imaging system is used in the restrictive object space (ROS) directly but without any specific considerations, the ROS will lead to severe microlens image distortions and then affects light field decoding, calibration and 3D reconstruction. The light field imaging in restrictive object space (ROS-LF) is complicated but significant. In this paper, we first deduce that the reason of the microlens image deviation is the position variation of the angular plane, then we propose the flexible angular plane for ROS-LF, while in the traditional light field the angular plane always coincides with the main lens plane. Subsequently, we propose the microlens image non-distortion principle for ROS-LF and introduce the ROS-LF imaging principle. We demonstrate that the difference is an aperture constant term between the ROS-LF and traditional light field imaging models. At last, we design a ROS-LF simulated system and calibrate it to verify principles proposed in this paper.
Ricci-Notation Tensor Framework for Model-Based Approaches to Imaging
Dec 07, 2023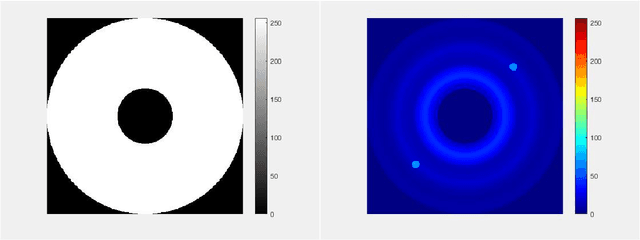
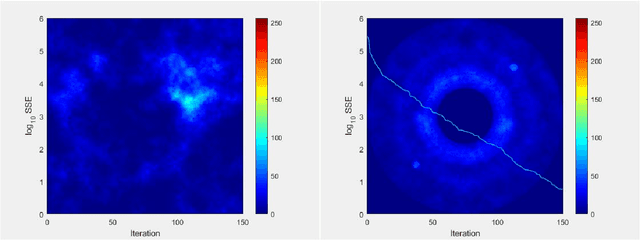
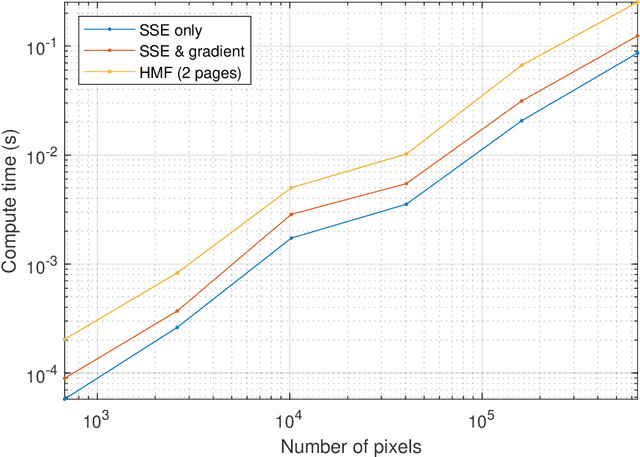
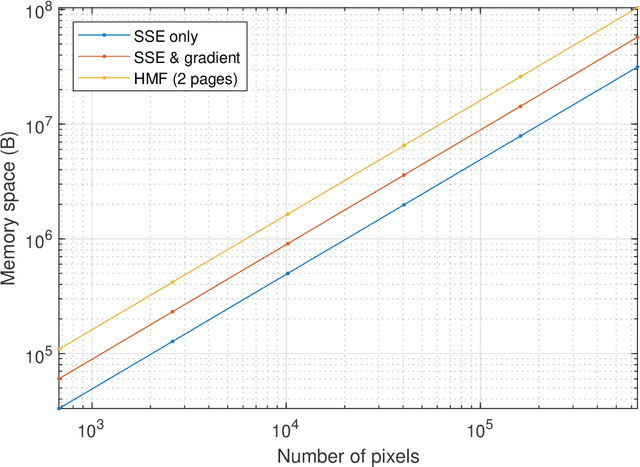
Model-based approaches to imaging, like specialized image enhancements in astronomy, favour physics-based models which facilitate explanations of relationships between observed inputs and computed outputs. While this paper features a tutorial example, inspired by exoplanet imaging, that reveals embedded 2D fast Fourier transforms in an image enhancement model, the work is actually about the tensor algebra and software, or tensor frameworks, available for model-based imaging. The paper proposes a Ricci-notation tensor (RT) framework, comprising an extended Ricci notation, which aligns well with the symbolic dual-index algebra of non-Euclidean geometry, and codesigned object-oriented software, called the RTToolbox for MATLAB. Extensions offer novel representations for entrywise, pagewise, and broadcasting operations popular in extended matrix-vector (EMV) frameworks for imaging. Complementing the EMV algebra computable with MATLAB, the RTToolbox demonstrates programmatic and computational efficiency thanks to careful design of tensor and dual-index classes. Compared to a numeric tensor predecessor, the RT framework enables superior ways to model imaging problems and, thereby, to develop solutions.
A global optimization SAR image segmentation model can be easily transformed to a general ROF denoising model
Dec 08, 2023In this paper, we propose a novel locally statistical active contour model (LACM) based on Aubert-Aujol (AA) denoising model and variational level set method, which can be used for SAR images segmentation with intensity inhomogeneity. Then we transform the proposed model into a global optimization model by using convex relaxation technique. Firstly, we apply the Split Bregman technique to transform the global optimization model into two alternating optimization processes of Shrink operator and Laplace operator, which is called SB_LACM model. Moreover, we propose two fast models to solve the global optimization model , which are more efficient than the SB_LACM model. The first model is: we add the proximal function to transform the global optimization model to a general ROF model[29], which can be solved by a fast denoising algorithm proposed by R.-Q.Jia, and H.Zhao; Thus we obtain a fast segmentation algorithm with global optimization solver that does not involve partial differential equations or difference equation, and only need simple difference computation. The second model is: we use a different splitting approach than one model to transform the global optimization model into a differentiable term and a general ROF model term, which can be solved by the same technique as the first model. Experiments using some challenging synthetic images and Envisat SAR images demonstrate the superiority of our proposed models with respect to the state-of-the-art models.
Prompt-based Distribution Alignment for Unsupervised Domain Adaptation
Dec 15, 2023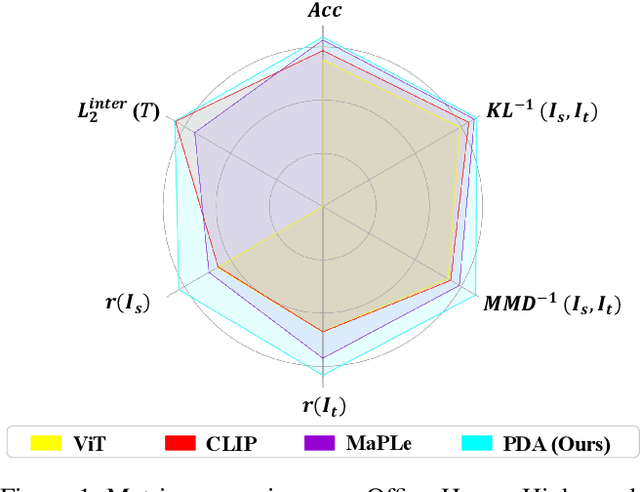
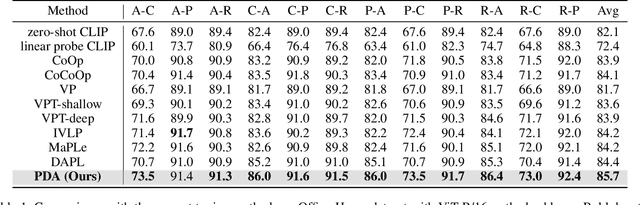
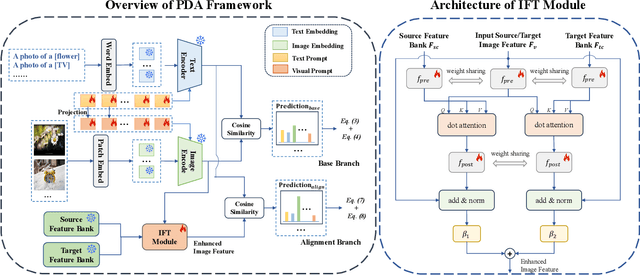
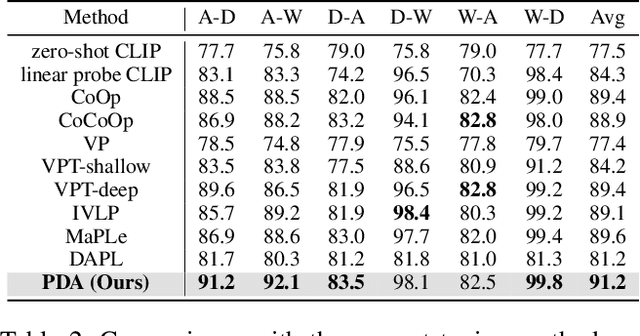
Recently, despite the unprecedented success of large pre-trained visual-language models (VLMs) on a wide range of downstream tasks, the real-world unsupervised domain adaptation (UDA) problem is still not well explored. Therefore, in this paper, we first experimentally demonstrate that the unsupervised-trained VLMs can significantly reduce the distribution discrepancy between source and target domains, thereby improving the performance of UDA. However, a major challenge for directly deploying such models on downstream UDA tasks is prompt engineering, which requires aligning the domain knowledge of source and target domains, since the performance of UDA is severely influenced by a good domain-invariant representation. We further propose a Prompt-based Distribution Alignment (PDA) method to incorporate the domain knowledge into prompt learning. Specifically, PDA employs a two-branch prompt-tuning paradigm, namely base branch and alignment branch. The base branch focuses on integrating class-related representation into prompts, ensuring discrimination among different classes. To further minimize domain discrepancy, for the alignment branch, we construct feature banks for both the source and target domains and propose image-guided feature tuning (IFT) to make the input attend to feature banks, which effectively integrates self-enhanced and cross-domain features into the model. In this way, these two branches can be mutually promoted to enhance the adaptation of VLMs for UDA. We conduct extensive experiments on three benchmarks to demonstrate that our proposed PDA achieves state-of-the-art performance. The code is available at https://github.com/BaiShuanghao/Prompt-based-Distribution-Alignment.
GMTalker: Gaussian Mixture based Emotional talking video Portraits
Dec 12, 2023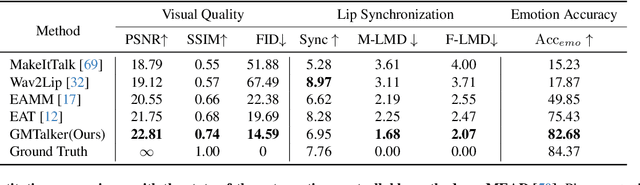
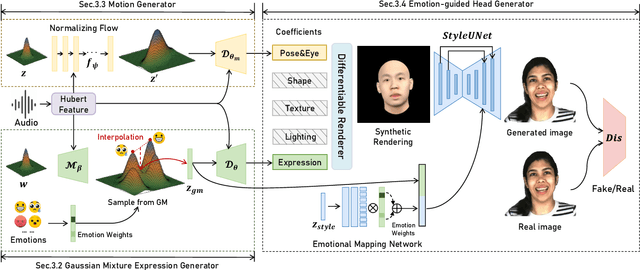
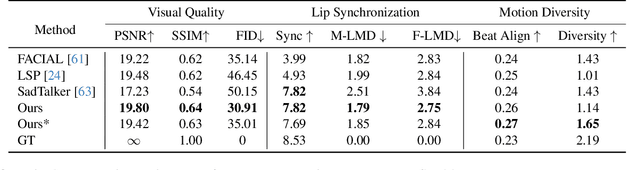
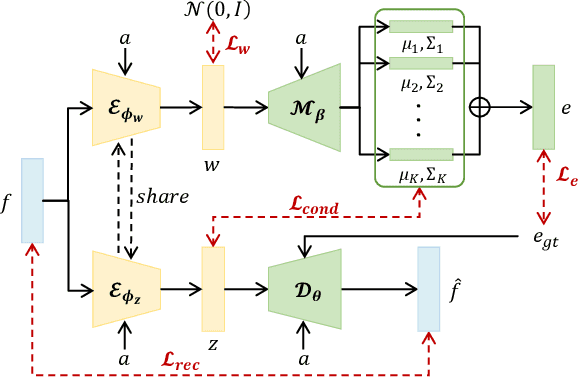
Synthesizing high-fidelity and emotion-controllable talking video portraits, with audio-lip sync, vivid expression, realistic head pose, and eye blink, is an important and challenging task in recent years. Most of the existing methods suffer in achieving personalized precise emotion control or continuously interpolating between different emotions and generating diverse motion. To address these problems, we present GMTalker, a Gaussian mixture based emotional talking portraits generation framework. Specifically, we propose a Gaussian Mixture based Expression Generator (GMEG) which can construct a continuous and multi-modal latent space, achieving more flexible emotion manipulation. Furthermore, we introduce a normalizing flow based motion generator pretrained on the dataset with a wide-range motion to generate diverse motions. Finally, we propose a personalized emotion-guided head generator with an Emotion Mapping Network (EMN) which can synthesize high-fidelity and faithful emotional video portraits. Both quantitative and qualitative experiments demonstrate our method outperforms previous methods in image quality, photo-realism, emotion accuracy and motion diversity.
Neural Video Fields Editing
Dec 12, 2023Diffusion models have revolutionized text-driven video editing. However, applying these methods to real-world editing encounters two significant challenges: (1) the rapid increase in graphics memory demand as the number of frames grows, and (2) the inter-frame inconsistency in edited videos. To this end, we propose NVEdit, a novel text-driven video editing framework designed to mitigate memory overhead and improve consistent editing for real-world long videos. Specifically, we construct a neural video field, powered by tri-plane and sparse grid, to enable encoding long videos with hundreds of frames in a memory-efficient manner. Next, we update the video field through off-the-shelf Text-to-Image (T2I) models to impart text-driven editing effects. A progressive optimization strategy is developed to preserve original temporal priors. Importantly, both the neural video field and T2I model are adaptable and replaceable, thus inspiring future research. Experiments demonstrate that our approach successfully edits hundreds of frames with impressive inter-frame consistency.