 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
CL2CM: Improving Cross-Lingual Cross-Modal Retrieval via Cross-Lingual Knowledge Transfer
Dec 14, 2023
Cross-lingual cross-modal retrieval has garnered increasing attention recently, which aims to achieve the alignment between vision and target language (V-T) without using any annotated V-T data pairs. Current methods employ machine translation (MT) to construct pseudo-parallel data pairs, which are then used to learn a multi-lingual and multi-modal embedding space that aligns visual and target-language representations. However, the large heterogeneous gap between vision and text, along with the noise present in target language translations, poses significant challenges in effectively aligning their representations. To address these challenges, we propose a general framework, Cross-Lingual to Cross-Modal (CL2CM), which improves the alignment between vision and target language using cross-lingual transfer. This approach allows us to fully leverage the merits of multi-lingual pre-trained models (e.g., mBERT) and the benefits of the same modality structure, i.e., smaller gap, to provide reliable and comprehensive semantic correspondence (knowledge) for the cross-modal network. We evaluate our proposed approach on two multilingual image-text datasets, Multi30K and MSCOCO, and one video-text dataset, VATEX. The results clearly demonstrate the effectiveness of our proposed method and its high potential for large-scale retrieval.
HeadRecon: High-Fidelity 3D Head Reconstruction from Monocular Video
Dec 14, 2023Recently, the reconstruction of high-fidelity 3D head models from static portrait image has made great progress. However, most methods require multi-view or multi-illumination information, which therefore put forward high requirements for data acquisition. In this paper, we study the reconstruction of high-fidelity 3D head models from arbitrary monocular videos. Non-rigid structure from motion (NRSFM) methods have been widely used to solve such problems according to the two-dimensional correspondence between different frames. However, the inaccurate correspondence caused by high-complex hair structures and various facial expression changes would heavily influence the reconstruction accuracy. To tackle these problems, we propose a prior-guided dynamic implicit neural network. Specifically, we design a two-part dynamic deformation field to transform the current frame space to the canonical one. We further model the head geometry in the canonical space with a learnable signed distance field (SDF) and optimize it using the volumetric rendering with the guidance of two-main head priors to improve the reconstruction accuracy and robustness. Extensive ablation studies and comparisons with state-of-the-art methods demonstrate the effectiveness and robustness of our proposed method.
GOEnFusion: Gradient Origin Encodings for 3D Forward Diffusion Models
Dec 14, 2023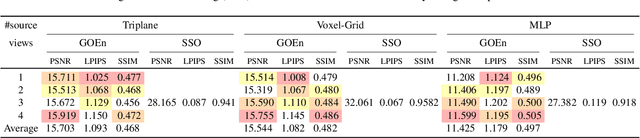
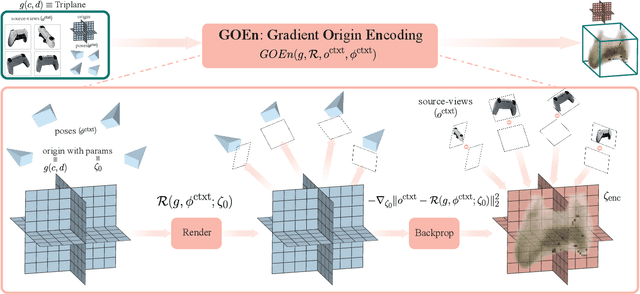
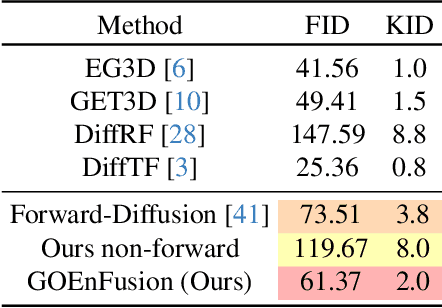
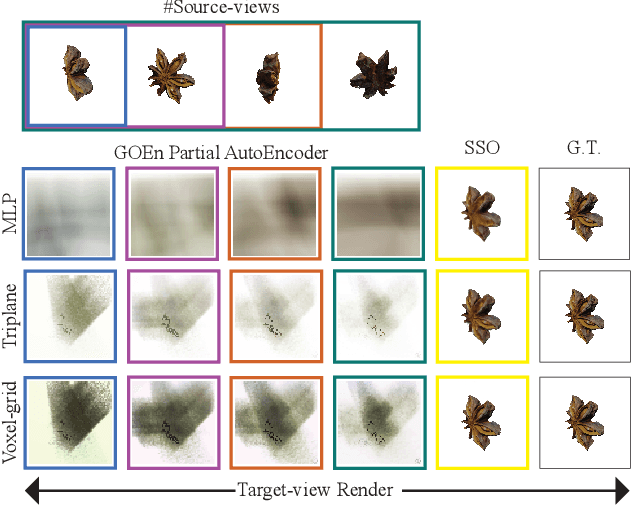
The recently introduced Forward-Diffusion method allows to train a 3D diffusion model using only 2D images for supervision. However, it does not easily generalise to different 3D representations and requires a computationally expensive auto-regressive sampling process to generate the underlying 3D scenes. In this paper, we propose GOEn: Gradient Origin Encoding (pronounced "gone"). GOEn can encode input images into any type of 3D representation without the need to use a pre-trained image feature extractor. It can also handle single, multiple or no source view(s) alike, by design, and tries to maximise the information transfer from the views to the encodings. Our proposed GOEnFusion model pairs GOEn encodings with a realisation of the Forward-Diffusion model which addresses the limitations of the vanilla Forward-Diffusion realisation. We evaluate how much information the GOEn mechanism transfers to the encoded representations, and how well it captures the prior distribution over the underlying 3D scenes, through the lens of a partial AutoEncoder. Lastly, the efficacy of the GOEnFusion model is evaluated on the recently proposed OmniObject3D dataset while comparing to the state-of-the-art Forward and non-Forward-Diffusion models and other 3D generative models.
ResEnsemble-DDPM: Residual Denoising Diffusion Probabilistic Models for Ensemble Learning
Dec 04, 2023Nowadays, denoising diffusion probabilistic models have been adapted for many image segmentation tasks. However, existing end-to-end models have already demonstrated remarkable capabilities. Rather than using denoising diffusion probabilistic models alone, integrating the abilities of both denoising diffusion probabilistic models and existing end-to-end models can better improve the performance of image segmentation. Based on this, we implicitly introduce residual term into the diffusion process and propose ResEnsemble-DDPM, which seamlessly integrates the diffusion model and the end-to-end model through ensemble learning. The output distributions of these two models are strictly symmetric with respect to the ground truth distribution, allowing us to integrate the two models by reducing the residual term. Experimental results demonstrate that our ResEnsemble-DDPM can further improve the capabilities of existing models. Furthermore, its ensemble learning strategy can be generalized to other downstream tasks in image generation and get strong competitiveness.
Implicit Learning of Scene Geometry from Poses for Global Localization
Dec 04, 2023Global visual localization estimates the absolute pose of a camera using a single image, in a previously mapped area. Obtaining the pose from a single image enables many robotics and augmented/virtual reality applications. Inspired by latest advances in deep learning, many existing approaches directly learn and regress 6 DoF pose from an input image. However, these methods do not fully utilize the underlying scene geometry for pose regression. The challenge in monocular relocalization is the minimal availability of supervised training data, which is just the corresponding 6 DoF poses of the images. In this paper, we propose to utilize these minimal available labels (.i.e, poses) to learn the underlying 3D geometry of the scene and use the geometry to estimate the 6 DoF camera pose. We present a learning method that uses these pose labels and rigid alignment to learn two 3D geometric representations (\textit{X, Y, Z coordinates}) of the scene, one in camera coordinate frame and the other in global coordinate frame. Given a single image, it estimates these two 3D scene representations, which are then aligned to estimate a pose that matches the pose label. This formulation allows for the active inclusion of additional learning constraints to minimize 3D alignment errors between the two 3D scene representations, and 2D re-projection errors between the 3D global scene representation and 2D image pixels, resulting in improved localization accuracy. During inference, our model estimates the 3D scene geometry in camera and global frames and aligns them rigidly to obtain pose in real-time. We evaluate our work on three common visual localization datasets, conduct ablation studies, and show that our method exceeds state-of-the-art regression methods' pose accuracy on all datasets.
VCISR: Blind Single Image Super-Resolution with Video Compression Synthetic Data
Nov 02, 2023

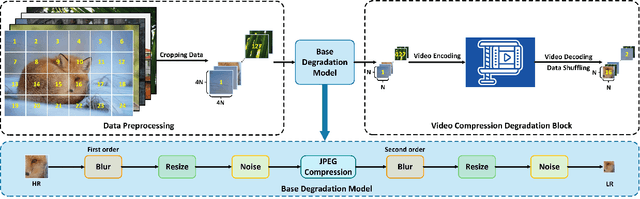

In the blind single image super-resolution (SISR) task, existing works have been successful in restoring image-level unknown degradations. However, when a single video frame becomes the input, these works usually fail to address degradations caused by video compression, such as mosquito noise, ringing, blockiness, and staircase noise. In this work, we for the first time, present a video compression-based degradation model to synthesize low-resolution image data in the blind SISR task. Our proposed image synthesizing method is widely applicable to existing image datasets, so that a single degraded image can contain distortions caused by the lossy video compression algorithms. This overcomes the leak of feature diversity in video data and thus retains the training efficiency. By introducing video coding artifacts to SISR degradation models, neural networks can super-resolve images with the ability to restore video compression degradations, and achieve better results on restoring generic distortions caused by image compression as well. Our proposed approach achieves superior performance in SOTA no-reference Image Quality Assessment, and shows better visual quality on various datasets. In addition, we evaluate the SISR neural network trained with our degradation model on video super-resolution (VSR) datasets. Compared to architectures specifically designed for the VSR purpose, our method exhibits similar or better performance, evidencing that the presented strategy on infusing video-based degradation is generalizable to address more complicated compression artifacts even without temporal cues.
Filling the Image Information Gap for VQA: Prompting Large Language Models to Proactively Ask Questions
Nov 20, 2023

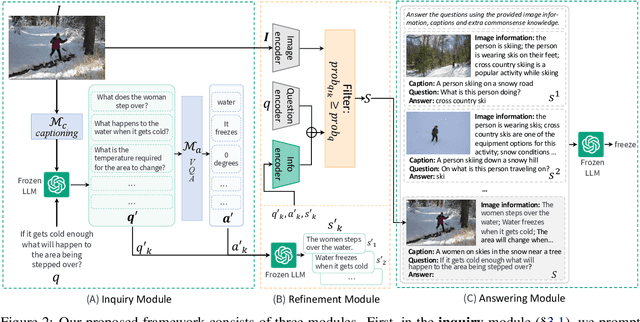
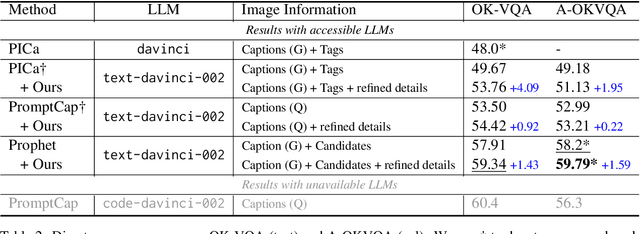
Large Language Models (LLMs) demonstrate impressive reasoning ability and the maintenance of world knowledge not only in natural language tasks, but also in some vision-language tasks such as open-domain knowledge-based visual question answering (OK-VQA). As images are invisible to LLMs, researchers convert images to text to engage LLMs into the visual question reasoning procedure. This leads to discrepancies between images and their textual representations presented to LLMs, which consequently impedes final reasoning performance. To fill the information gap and better leverage the reasoning capability, we design a framework that enables LLMs to proactively ask relevant questions to unveil more details in the image, along with filters for refining the generated information. We validate our idea on OK-VQA and A-OKVQA. Our method continuously boosts the performance of baselines methods by an average gain of 2.15% on OK-VQA, and achieves consistent improvements across different LLMs.
Deep learning as a tool for quantum error reduction in quantum image processing
Nov 08, 2023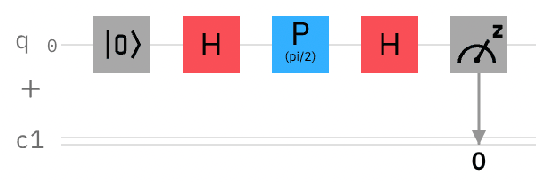
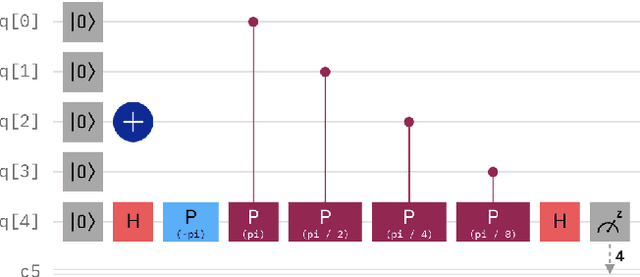

Despite the limited availability and quantum volume of quantum computers, quantum image representation is a widely researched area. Currently developed methods use quantum entanglement to encode information about pixel positions. These methods range from using the angle parameter of the rotation gate (e.g., the Flexible Representation of Quantum Images, FRQI), sequences of qubits (e.g., Novel Enhanced Quantum Representation, NEQR), or the angle parameter of the phase shift gates (e.g., Local Phase Image Quantum Encoding, LPIQE) for storing color information. All these methods are significantly affected by decoherence and other forms of quantum noise, which is an inseparable part of quantum computing in the noisy intermediate-scale quantum era. These phenomena can highly influence the measurements and result in extracted images that are visually dissimilar to the originals. Because this process is at its foundation quantum, the computational reversal of this process is possible. There are many methods for error correction, mitigation, and reduction, but all of them use quantum computer time or additional qubits to achieve the desired result. We report the successful use of a generative adversarial network trained for image-to-image translation, in conjunction with Phase Distortion Unraveling error reduction method, for reducing overall error in images encoded using LPIQE.
MixerFlow for Image Modelling
Oct 25, 2023Normalising flows are statistical models that transform a complex density into a simpler density through the use of bijective transformations enabling both density estimation and data generation from a single model. In the context of image modelling, the predominant choice has been the Glow-based architecture, whereas alternative architectures remain largely unexplored in the research community. In this work, we propose a novel architecture called MixerFlow, based on the MLP-Mixer architecture, further unifying the generative and discriminative modelling architectures. MixerFlow offers an effective mechanism for weight sharing for flow-based models. Our results demonstrate better density estimation on image datasets under a fixed computational budget and scales well as the image resolution increases, making MixeFlow a powerful yet simple alternative to the Glow-based architectures. We also show that MixerFlow provides more informative embeddings than Glow-based architectures.
A Simple Interpretable Transformer for Fine-Grained Image Classification and Analysis
Nov 07, 2023We present a novel usage of Transformers to make image classification interpretable. Unlike mainstream classifiers that wait until the last fully-connected layer to incorporate class information to make predictions, we investigate a proactive approach, asking each class to search for itself in an image. We realize this idea via a Transformer encoder-decoder inspired by DEtection TRansformer (DETR). We learn ``class-specific'' queries (one for each class) as input to the decoder, enabling each class to localize its patterns in an image via cross-attention. We name our approach INterpretable TRansformer (INTR), which is fairly easy to implement and exhibits several compelling properties. We show that INTR intrinsically encourages each class to attend distinctively; the cross-attention weights thus provide a faithful interpretation of the prediction. Interestingly, via ``multi-head'' cross-attention, INTR could identify different ``attributes'' of a class, making it particularly suitable for fine-grained classification and analysis, which we demonstrate on eight datasets. Our code and pre-trained model are publicly accessible at https://github.com/Imageomics/INTR.