 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
ST(OR)2: Spatio-Temporal Object Level Reasoning for Activity Recognition in the Operating Room
Dec 19, 2023
Surgical robotics holds much promise for improving patient safety and clinician experience in the Operating Room (OR). However, it also comes with new challenges, requiring strong team coordination and effective OR management. Automatic detection of surgical activities is a key requirement for developing AI-based intelligent tools to tackle these challenges. The current state-of-the-art surgical activity recognition methods however operate on image-based representations and depend on large-scale labeled datasets whose collection is time-consuming and resource-expensive. This work proposes a new sample-efficient and object-based approach for surgical activity recognition in the OR. Our method focuses on the geometric arrangements between clinicians and surgical devices, thus utilizing the significant object interaction dynamics in the OR. We conduct experiments in a low-data regime study for long video activity recognition. We also benchmark our method againstother object-centric approaches on clip-level action classification and show superior performance.
On Inference Stability for Diffusion Models
Dec 19, 2023Denoising Probabilistic Models (DPMs) represent an emerging domain of generative models that excel in generating diverse and high-quality images. However, most current training methods for DPMs often neglect the correlation between timesteps, limiting the model's performance in generating images effectively. Notably, we theoretically point out that this issue can be caused by the cumulative estimation gap between the predicted and the actual trajectory. To minimize that gap, we propose a novel \textit{sequence-aware} loss that aims to reduce the estimation gap to enhance the sampling quality. Furthermore, we theoretically show that our proposed loss function is a tighter upper bound of the estimation loss in comparison with the conventional loss in DPMs. Experimental results on several benchmark datasets including CIFAR10, CelebA, and CelebA-HQ consistently show a remarkable improvement of our proposed method regarding the image generalization quality measured by FID and Inception Score compared to several DPM baselines. Our code and pre-trained checkpoints are available at \url{https://github.com/viettmab/SA-DPM}.
GeomVerse: A Systematic Evaluation of Large Models for Geometric Reasoning
Dec 19, 2023Large language models have shown impressive results for multi-hop mathematical reasoning when the input question is only textual. Many mathematical reasoning problems, however, contain both text and image. With the ever-increasing adoption of vision language models (VLMs), understanding their reasoning abilities for such problems is crucial. In this paper, we evaluate the reasoning capabilities of VLMs along various axes through the lens of geometry problems. We procedurally create a synthetic dataset of geometry questions with controllable difficulty levels along multiple axes, thus enabling a systematic evaluation. The empirical results obtained using our benchmark for state-of-the-art VLMs indicate that these models are not as capable in subjects like geometry (and, by generalization, other topics requiring similar reasoning) as suggested by previous benchmarks. This is made especially clear by the construction of our benchmark at various depth levels, since solving higher-depth problems requires long chains of reasoning rather than additional memorized knowledge. We release the dataset for further research in this area.
IPAD: Iterative, Parallel, and Diffusion-based Network for Scene Text Recognition
Dec 19, 2023Nowadays, scene text recognition has attracted more and more attention due to its diverse applications. Most state-of-the-art methods adopt an encoder-decoder framework with the attention mechanism, autoregressively generating text from left to right. Despite the convincing performance, this sequential decoding strategy constrains inference speed. Conversely, non-autoregressive models provide faster, simultaneous predictions but often sacrifice accuracy. Although utilizing an explicit language model can improve performance, it burdens the computational load. Besides, separating linguistic knowledge from vision information may harm the final prediction. In this paper, we propose an alternative solution, using a parallel and iterative decoder that adopts an easy-first decoding strategy. Furthermore, we regard text recognition as an image-based conditional text generation task and utilize the discrete diffusion strategy, ensuring exhaustive exploration of bidirectional contextual information. Extensive experiments demonstrate that the proposed approach achieves superior results on the benchmark datasets, including both Chinese and English text images.
Leveraging CNNs and Ensemble Learning for Automated Disaster Image Classification
Nov 22, 2023

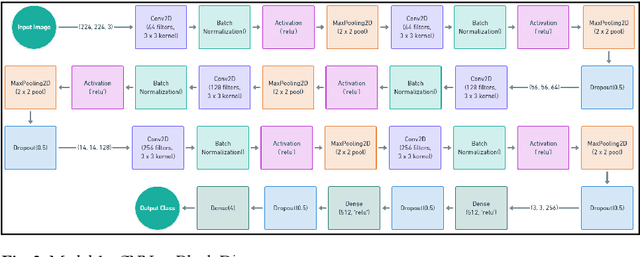
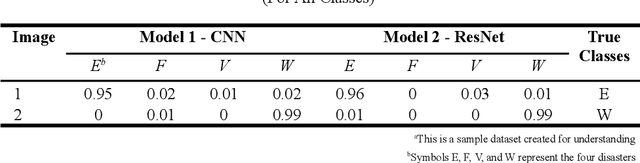
Natural disasters act as a serious threat globally, requiring effective and efficient disaster management and recovery. This paper focuses on classifying natural disaster images using Convolutional Neural Networks (CNNs). Multiple CNN architectures were built and trained on a dataset containing images of earthquakes, floods, wildfires, and volcanoes. A stacked CNN ensemble approach proved to be the most effective, achieving 95% accuracy and an F1 score going up to 0.96 for individual classes. Tuning hyperparameters of individual models for optimization was critical to maximize the models' performance. The stacking of CNNs with XGBoost acting as the meta-model utilizes the strengths of the CNN and ResNet models to improve the overall accuracy of the classification. Results obtained from the models illustrated the potency of CNN-based models for automated disaster image classification. This lays the foundation for expanding these techniques to build robust systems for disaster response, damage assessment, and recovery management.
Implicit Affordance Acquisition via Causal Action-Effect Modeling in the Video Domain
Dec 18, 2023Affordance knowledge is a fundamental aspect of commonsense knowledge. Recent findings indicate that world knowledge emerges through large-scale self-supervised pretraining, motivating our exploration of acquiring affordance knowledge from the visual domain. To this end, we augment an existing instructional video resource to create the new Causal Action-Effect (CAE) dataset and design two novel pretraining tasks -- Masked Action Modeling (MAM) and Masked Effect Modeling (MEM) -- promoting the acquisition of two affordance properties in models: behavior and entity equivalence, respectively. We empirically demonstrate the effectiveness of our proposed methods in learning affordance properties. Furthermore, we show that a model pretrained on both tasks outperforms a strong image-based visual-linguistic foundation model (FLAVA) as well as pure linguistic models on a zero-shot physical reasoning probing task.
Loss Functions in the Era of Semantic Segmentation: A Survey and Outlook
Dec 08, 2023Semantic image segmentation, the process of classifying each pixel in an image into a particular class, plays an important role in many visual understanding systems. As the predominant criterion for evaluating the performance of statistical models, loss functions are crucial for shaping the development of deep learning-based segmentation algorithms and improving their overall performance. To aid researchers in identifying the optimal loss function for their particular application, this survey provides a comprehensive and unified review of $25$ loss functions utilized in image segmentation. We provide a novel taxonomy and thorough review of how these loss functions are customized and leveraged in image segmentation, with a systematic categorization emphasizing their significant features and applications. Furthermore, to evaluate the efficacy of these methods in real-world scenarios, we propose unbiased evaluations of some distinct and renowned loss functions on established medical and natural image datasets. We conclude this review by identifying current challenges and unveiling future research opportunities. Finally, we have compiled the reviewed studies that have open-source implementations on our GitHub page.
Scientific Preparation for CSST: Classification of Galaxy and Nebula/Star Cluster Based on Deep Learning
Dec 08, 2023The Chinese Space Station Telescope (abbreviated as CSST) is a future advanced space telescope. Real-time identification of galaxy and nebula/star cluster (abbreviated as NSC) images is of great value during CSST survey. While recent research on celestial object recognition has progressed, the rapid and efficient identification of high-resolution local celestial images remains challenging. In this study, we conducted galaxy and NSC image classification research using deep learning methods based on data from the Hubble Space Telescope. We built a Local Celestial Image Dataset and designed a deep learning model named HR-CelestialNet for classifying images of the galaxy and NSC. HR-CelestialNet achieved an accuracy of 89.09% on the testing set, outperforming models such as AlexNet, VGGNet and ResNet, while demonstrating faster recognition speeds. Furthermore, we investigated the factors influencing CSST image quality and evaluated the generalization ability of HR-CelestialNet on the blurry image dataset, demonstrating its robustness to low image quality. The proposed method can enable real-time identification of celestial images during CSST survey mission.
Language-Guided Transformer for Federated Multi-Label Classification
Dec 12, 2023Federated Learning (FL) is an emerging paradigm that enables multiple users to collaboratively train a robust model in a privacy-preserving manner without sharing their private data. Most existing approaches of FL only consider traditional single-label image classification, ignoring the impact when transferring the task to multi-label image classification. Nevertheless, it is still challenging for FL to deal with user heterogeneity in their local data distribution in the real-world FL scenario, and this issue becomes even more severe in multi-label image classification. Inspired by the recent success of Transformers in centralized settings, we propose a novel FL framework for multi-label classification. Since partial label correlation may be observed by local clients during training, direct aggregation of locally updated models would not produce satisfactory performances. Thus, we propose a novel FL framework of Language-Guided Transformer (FedLGT) to tackle this challenging task, which aims to exploit and transfer knowledge across different clients for learning a robust global model. Through extensive experiments on various multi-label datasets (e.g., FLAIR, MS-COCO, etc.), we show that our FedLGT is able to achieve satisfactory performance and outperforms standard FL techniques under multi-label FL scenarios. Code is available at https://github.com/Jack24658735/FedLGT.
SimAC: A Simple Anti-Customization Method against Text-to-Image Synthesis of Diffusion Models
Dec 13, 2023Despite the success of diffusion-based customization methods on visual content creation, increasing concerns have been raised about such techniques from both privacy and political perspectives. To tackle this issue, several anti-customization methods have been proposed in very recent months, predominantly grounded in adversarial attacks. Unfortunately, most of these methods adopt straightforward designs, such as end-to-end optimization with a focus on adversarially maximizing the original training loss, thereby neglecting nuanced internal properties intrinsic to the diffusion model, and even leading to ineffective optimization in some diffusion time steps. In this paper, we strive to bridge this gap by undertaking a comprehensive exploration of these inherent properties, to boost the performance of current anti-customization approaches. Two aspects of properties are investigated: 1) We examine the relationship between time step selection and the model's perception in the frequency domain of images and find that lower time steps can give much more contributions to adversarial noises. This inspires us to propose an adaptive greedy search for optimal time steps that seamlessly integrates with existing anti-customization methods. 2) We scrutinize the roles of features at different layers during denoising and devise a sophisticated feature-based optimization framework for anti-customization. Experiments on facial benchmarks demonstrate that our approach significantly increases identity disruption, thereby enhancing user privacy and security.