 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Cyclical Route Linking Fundamental Mechanism and AI Algorithm: An Example from Poisson's Ratio in Amorphous Networks
Dec 14, 2023
"AI for science" is widely recognized as a future trend in the development of scientific research. Currently, although machine learning algorithms have played a crucial role in scientific research with numerous successful cases, relatively few instances exist where AI assists researchers in uncovering the underlying physical mechanisms behind a certain phenomenon and subsequently using that mechanism to improve machine learning algorithms' efficiency. This article uses the investigation into the relationship between extreme Poisson's ratio values and the structure of amorphous networks as a case study to illustrate how machine learning methods can assist in revealing underlying physical mechanisms. Upon recognizing that the Poisson's ratio relies on the low-frequency vibrational modes of dynamical matrix, we can then employ a convolutional neural network, trained on the dynamical matrix instead of traditional image recognition, to predict the Poisson's ratio of amorphous networks with a much higher efficiency. Through this example, we aim to showcase the role that artificial intelligence can play in revealing fundamental physical mechanisms, which subsequently improves the machine learning algorithms significantly.
Color Agnostic Cross-Spectral Disparity Estimation
Dec 14, 2023Since camera modules become more and more affordable, multispectral camera arrays have found their way from special applications to the mass market, e.g., in automotive systems, smartphones, or drones. Due to multiple modalities, the registration of different viewpoints and the required cross-spectral disparity estimation is up to the present extremely challenging. To overcome this problem, we introduce a novel spectral image synthesis in combination with a color agnostic transform. Thus, any recently published stereo matching network can be turned to a cross-spectral disparity estimator. Our novel algorithm requires only RGB stereo data to train a cross-spectral disparity estimator and a generalization from artificial training data to camera-captured images is obtained. The theoretical examination of the novel color agnostic method is completed by an extensive evaluation compared to state of the art including self-recorded multispectral data and a reference implementation. The novel color agnostic disparity estimation improves cross-spectral as well as conventional color stereo matching by reducing the average end-point error by 41% for cross-spectral and by 22% for mono-modal content, respectively.
Class-Wise Buffer Management for Incremental Object Detection: An Effective Buffer Training Strategy
Dec 14, 2023Class incremental learning aims to solve a problem that arises when continuously adding unseen class instances to an existing model This approach has been extensively studied in the context of image classification; however its applicability to object detection is not well established yet. Existing frameworks using replay methods mainly collect replay data without considering the model being trained and tend to rely on randomness or the number of labels of each sample. Also, despite the effectiveness of the replay, it was not yet optimized for the object detection task. In this paper, we introduce an effective buffer training strategy (eBTS) that creates the optimized replay buffer on object detection. Our approach incorporates guarantee minimum and hierarchical sampling to establish the buffer customized to the trained model. %These methods can facilitate effective retrieval of prior knowledge. Furthermore, we use the circular experience replay training to optimally utilize the accumulated buffer data. Experiments on the MS COCO dataset demonstrate that our eBTS achieves state-of-the-art performance compared to the existing replay schemes.
LRM: Large Reconstruction Model for Single Image to 3D
Nov 08, 2023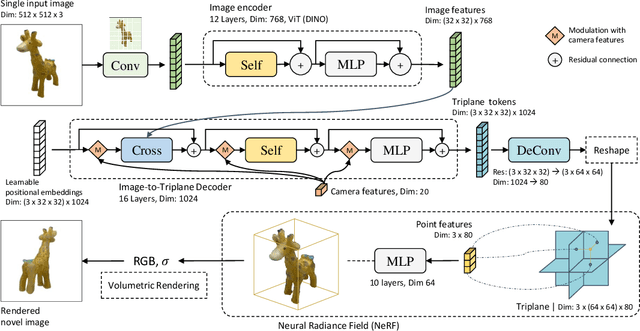
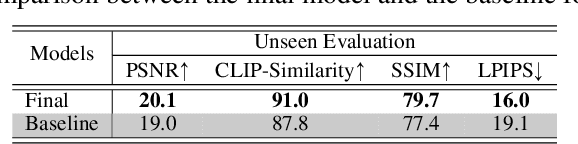

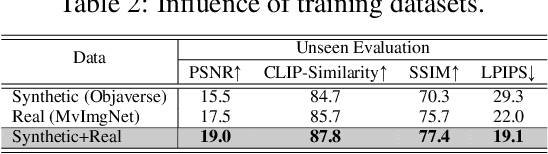
We propose the first Large Reconstruction Model (LRM) that predicts the 3D model of an object from a single input image within just 5 seconds. In contrast to many previous methods that are trained on small-scale datasets such as ShapeNet in a category-specific fashion, LRM adopts a highly scalable transformer-based architecture with 500 million learnable parameters to directly predict a neural radiance field (NeRF) from the input image. We train our model in an end-to-end manner on massive multi-view data containing around 1 million objects, including both synthetic renderings from Objaverse and real captures from MVImgNet. This combination of a high-capacity model and large-scale training data empowers our model to be highly generalizable and produce high-quality 3D reconstructions from various testing inputs including real-world in-the-wild captures and images from generative models. Video demos and interactable 3D meshes can be found on this website: https://yiconghong.me/LRM/.
Partition-based K-space Synthesis for Multi-contrast Parallel Imaging
Dec 01, 2023Multi-contrast magnetic resonance imaging is a significant and essential medical imaging technique.However, multi-contrast imaging has longer acquisition time and is easy to cause motion artifacts. In particular, the acquisition time for a T2-weighted image is prolonged due to its longer repetition time (TR). On the contrary, T1-weighted image has a shorter TR. Therefore,utilizing complementary information across T1 and T2-weighted image is a way to decrease the overall imaging time. Previous T1-assisted T2 reconstruction methods have mostly focused on image domain using whole-based image fusion approaches. The image domain reconstruction method has the defects of high computational complexity and limited flexibility. To address this issue, we propose a novel multi-contrast imaging method called partition-based k-space synthesis (PKS) which can achieve super reconstruction quality of T2-weighted image by feature fusion. Concretely, we first decompose fully-sampled T1 k-space data and under-sampled T2 k-space data into two sub-data, separately. Then two new objects are constructed by combining the two sub-T1/T2 data. After that, the two new objects as the whole data to realize the reconstruction of T2-weighted image. Finally, the objective T2 is synthesized by extracting the sub-T2 data of each part. Experimental results showed that our combined technique can achieve comparable or better results than using traditional k-space parallel imaging(SAKE) that processes each contrast independently.
Zero-Shot Enhancement of Low-Light Image Based on Retinex Decomposition
Nov 06, 2023Two difficulties here make low-light image enhancement a challenging task; firstly, it needs to consider not only luminance restoration but also image contrast, image denoising and color distortion issues simultaneously. Second, the effectiveness of existing low-light enhancement methods depends on paired or unpaired training data with poor generalization performance. To solve these difficult problems, we propose in this paper a new learning-based Retinex decomposition of zero-shot low-light enhancement method, called ZERRINNet. To this end, we first designed the N-Net network, together with the noise loss term, to be used for denoising the original low-light image by estimating the noise of the low-light image. Moreover, RI-Net is used to estimate the reflection component and illumination component, and in order to solve the color distortion and contrast, we use the texture loss term and segmented smoothing loss to constrain the reflection component and illumination component. Finally, our method is a zero-reference enhancement method that is not affected by the training data of paired and unpaired datasets, so our generalization performance is greatly improved, and in the paper, we have effectively validated it with a homemade real-life low-light dataset and additionally with advanced vision tasks, such as face detection, target recognition, and instance segmentation. We conducted comparative experiments on a large number of public datasets and the results show that the performance of our method is competitive compared to the current state-of-the-art methods. The code is available at:https://github.com/liwenchao0615/ZERRINNet
PathoDuet: Foundation Models for Pathological Slide Analysis of H&E and IHC Stains
Dec 15, 2023Large amounts of digitized histopathological data display a promising future for developing pathological foundation models via self-supervised learning methods. Foundation models pretrained with these methods serve as a good basis for downstream tasks. However, the gap between natural and histopathological images hinders the direct application of existing methods. In this work, we present PathoDuet, a series of pretrained models on histopathological images, and a new self-supervised learning framework in histopathology. The framework is featured by a newly-introduced pretext token and later task raisers to explicitly utilize certain relations between images, like multiple magnifications and multiple stains. Based on this, two pretext tasks, cross-scale positioning and cross-stain transferring, are designed to pretrain the model on Hematoxylin and Eosin (H\&E) images and transfer the model to immunohistochemistry (IHC) images, respectively. To validate the efficacy of our models, we evaluate the performance over a wide variety of downstream tasks, including patch-level colorectal cancer subtyping and whole slide image (WSI)-level classification in H\&E field, together with expression level prediction of IHC marker and tumor identification in IHC field. The experimental results show the superiority of our models over most tasks and the efficacy of proposed pretext tasks. The codes and models are available at https://github.com/openmedlab/PathoDuet.
Style Generation in Robot Calligraphy with Deep Generative Adversarial Networks
Dec 15, 2023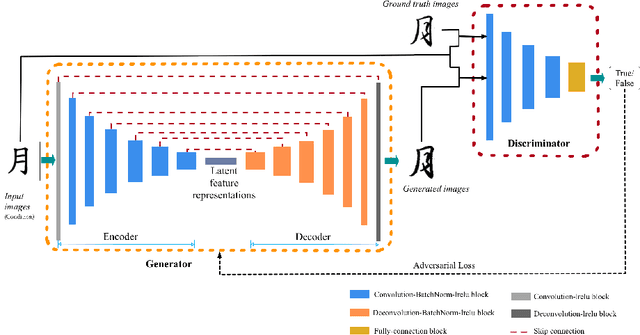



Robot calligraphy is an emerging exploration of artificial intelligence in the fields of art and education. Traditional calligraphy generation researches mainly focus on methods such as tool-based image processing, generative models, and style transfer. Unlike the English alphabet, the number of Chinese characters is tens of thousands, which leads to difficulties in the generation of a style consistent Chinese calligraphic font with over 6000 characters. Due to the lack of high-quality data sets, formal definitions of calligraphy knowledge, and scientific art evaluation methods, The results generated are frequently of low quality and falls short of professional-level requirements. To address the above problem, this paper proposes an automatic calligraphy generation model based on deep generative adversarial networks (deepGAN) that can generate style calligraphy fonts with professional standards. The key highlights of the proposed method include: (1) The datasets use a high-precision calligraphy synthesis method to ensure its high quality and sufficient quantity; (2) Professional calligraphers are invited to conduct a series of Turing tests to evaluate the gap between model generation results and human artistic level; (3) Experimental results indicate that the proposed model is the state-of-the-art among current calligraphy generation methods. The Turing tests and similarity evaluations validate the effectiveness of the proposed method.
Privacy-Aware Document Visual Question Answering
Dec 15, 2023Document Visual Question Answering (DocVQA) is a fast growing branch of document understanding. Despite the fact that documents contain sensitive or copyrighted information, none of the current DocVQA methods offers strong privacy guarantees. In this work, we explore privacy in the domain of DocVQA for the first time. We highlight privacy issues in state of the art multi-modal LLM models used for DocVQA, and explore possible solutions. Specifically, we focus on the invoice processing use case as a realistic, widely used scenario for document understanding, and propose a large scale DocVQA dataset comprising invoice documents and associated questions and answers. We employ a federated learning scheme, that reflects the real-life distribution of documents in different businesses, and we explore the use case where the ID of the invoice issuer is the sensitive information to be protected. We demonstrate that non-private models tend to memorise, behaviour that can lead to exposing private information. We then evaluate baseline training schemes employing federated learning and differential privacy in this multi-modal scenario, where the sensitive information might be exposed through any of the two input modalities: vision (document image) or language (OCR tokens). Finally, we design an attack exploiting the memorisation effect of the model, and demonstrate its effectiveness in probing different DocVQA models.
Structural Information Guided Multimodal Pre-training for Vehicle-centric Perception
Dec 15, 2023Understanding vehicles in images is important for various applications such as intelligent transportation and self-driving system. Existing vehicle-centric works typically pre-train models on large-scale classification datasets and then fine-tune them for specific downstream tasks. However, they neglect the specific characteristics of vehicle perception in different tasks and might thus lead to sub-optimal performance. To address this issue, we propose a novel vehicle-centric pre-training framework called VehicleMAE, which incorporates the structural information including the spatial structure from vehicle profile information and the semantic structure from informative high-level natural language descriptions for effective masked vehicle appearance reconstruction. To be specific, we explicitly extract the sketch lines of vehicles as a form of the spatial structure to guide vehicle reconstruction. The more comprehensive knowledge distilled from the CLIP big model based on the similarity between the paired/unpaired vehicle image-text sample is further taken into consideration to help achieve a better understanding of vehicles. A large-scale dataset is built to pre-train our model, termed Autobot1M, which contains about 1M vehicle images and 12693 text information. Extensive experiments on four vehicle-based downstream tasks fully validated the effectiveness of our VehicleMAE. The source code and pre-trained models will be released at https://github.com/Event-AHU/VehicleMAE.