 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Diagonal Hierarchical Consistency Learning for Semi-supervised Medical Image Segmentation
Nov 10, 2023
Medical image segmentation, which is essential for many clinical applications, has achieved almost human-level performance via data-driven deep learning techniques. Nevertheless, its performance is predicated on the costly process of manually annotating a large amount of medical images. To this end, we propose a novel framework for robust semi-supervised medical image segmentation using diagonal hierarchical consistency (DiHC-Net). First, it is composed of multiple sub-models with identical multi-scale architecture but with distinct sub-layers, such as up-sampling and normalisation layers. Second, a novel diagonal hierarchical consistency is enforced between one model's intermediate and final prediction and other models' soft pseudo labels in a diagonal hierarchical fashion. Experimental results verify the efficacy of our simple framework, outperforming all previous approaches on public Left Atrium (LA) dataset.
OneLLM: One Framework to Align All Modalities with Language
Dec 06, 2023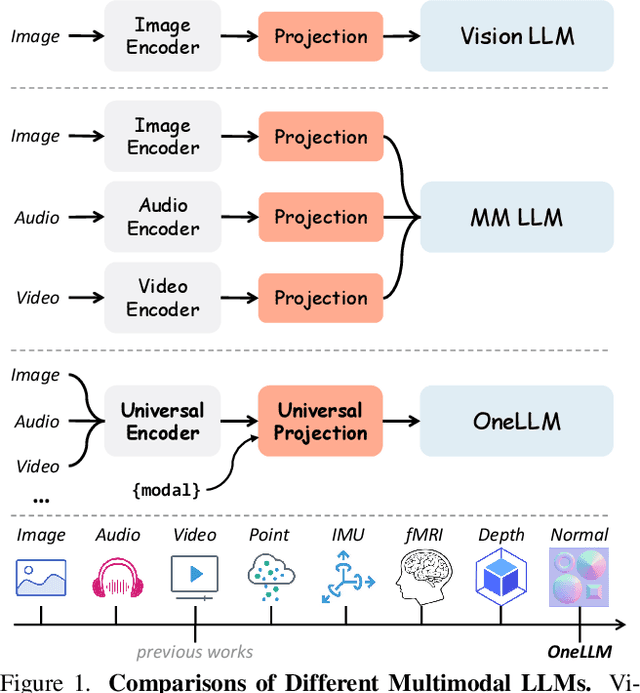
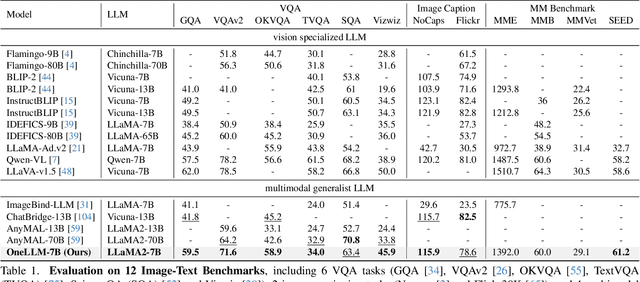
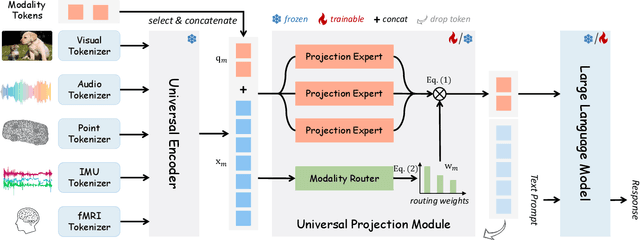
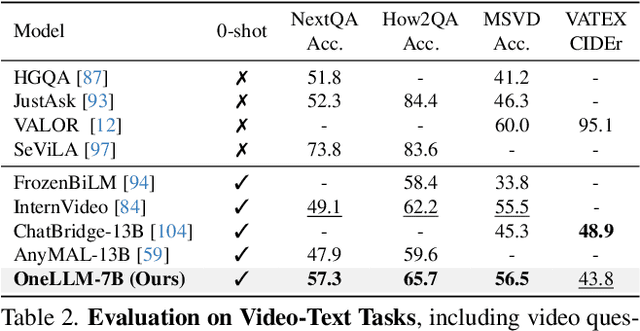
Multimodal large language models (MLLMs) have gained significant attention due to their strong multimodal understanding capability. However, existing works rely heavily on modality-specific encoders, which usually differ in architecture and are limited to common modalities. In this paper, we present OneLLM, an MLLM that aligns eight modalities to language using a unified framework. We achieve this through a unified multimodal encoder and a progressive multimodal alignment pipeline. In detail, we first train an image projection module to connect a vision encoder with LLM. Then, we build a universal projection module (UPM) by mixing multiple image projection modules and dynamic routing. Finally, we progressively align more modalities to LLM with the UPM. To fully leverage the potential of OneLLM in following instructions, we also curated a comprehensive multimodal instruction dataset, including 2M items from image, audio, video, point cloud, depth/normal map, IMU and fMRI brain activity. OneLLM is evaluated on 25 diverse benchmarks, encompassing tasks such as multimodal captioning, question answering and reasoning, where it delivers excellent performance. Code, data, model and online demo are available at https://github.com/csuhan/OneLLM
Unified learning-based lossy and lossless JPEG recompression
Dec 05, 2023JPEG is still the most widely used image compression algorithm. Most image compression algorithms only consider uncompressed original image, while ignoring a large number of already existing JPEG images. Recently, JPEG recompression approaches have been proposed to further reduce the size of JPEG files. However, those methods only consider JPEG lossless recompression, which is just a special case of the rate-distortion theorem. In this paper, we propose a unified lossly and lossless JPEG recompression framework, which consists of learned quantization table and Markovian hierarchical variational autoencoders. Experiments show that our method can achieve arbitrarily low distortion when the bitrate is close to the upper bound, namely the bitrate of the lossless compression model. To the best of our knowledge, this is the first learned method that bridges the gap between lossy and lossless recompression of JPEG images.
A Parameterized Generative Adversarial Network Using Cyclic Projection for Explainable Medical Image Classification
Dec 07, 2023Although current data augmentation methods are successful to alleviate the data insufficiency, conventional augmentation are primarily intra-domain while advanced generative adversarial networks (GANs) generate images remaining uncertain, particularly in small-scale datasets. In this paper, we propose a parameterized GAN (ParaGAN) that effectively controls the changes of synthetic samples among domains and highlights the attention regions for downstream classification. Specifically, ParaGAN incorporates projection distance parameters in cyclic projection and projects the source images to the decision boundary to obtain the class-difference maps. Our experiments show that ParaGAN can consistently outperform the existing augmentation methods with explainable classification on two small-scale medical datasets.
A Survey of AI Text-to-Image and AI Text-to-Video Generators
Nov 10, 2023Text-to-Image and Text-to-Video AI generation models are revolutionary technologies that use deep learning and natural language processing (NLP) techniques to create images and videos from textual descriptions. This paper investigates cutting-edge approaches in the discipline of Text-to-Image and Text-to-Video AI generations. The survey provides an overview of the existing literature as well as an analysis of the approaches used in various studies. It covers data preprocessing techniques, neural network types, and evaluation metrics used in the field. In addition, the paper discusses the challenges and limitations of Text-to-Image and Text-to-Video AI generations, as well as future research directions. Overall, these models have promising potential for a wide range of applications such as video production, content creation, and digital marketing.
Video-Based Rendering Techniques: A Survey
Dec 08, 2023Three-dimensional reconstruction of events recorded on images has been a common challenge between computer vision and computer graphics for a long time. Estimating the real position of objects and surfaces using vision as an input is no trivial task and has been approached in several different ways. Although huge progress has been made so far, there are several open issues to which an answer is needed. The use of videos as an input for a rendering process (video-based rendering, VBR) is something that recently has been started to be looked upon and has added many other challenges and also solutions to the classical image-based rendering issue (IBR). This article presents the state of art on video-based rendering and image-based techniques that can be applied on this scenario, evaluating the open issues yet to be solved, indicating where future work should be focused.
The Perception-Robustness Tradeoff in Deterministic Image Restoration
Nov 14, 2023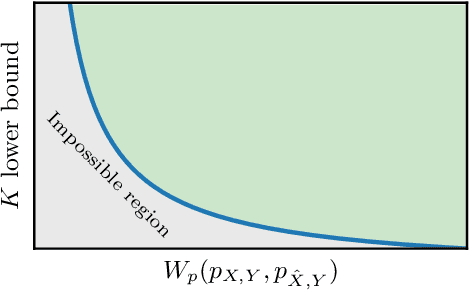

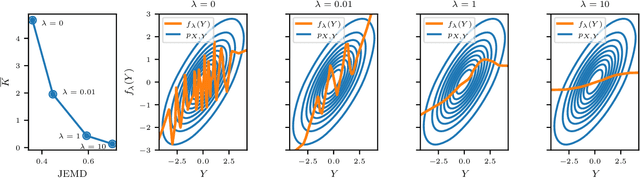

We study the behavior of deterministic methods for solving inverse problems in imaging. These methods are commonly designed to achieve two goals: (1) attaining high perceptual quality, and (2) generating reconstructions that are consistent with the measurements. We provide a rigorous proof that the better a predictor satisfies these two requirements, the larger its Lipschitz constant must be, regardless of the nature of the degradation involved. In particular, to approach perfect perceptual quality and perfect consistency, the Lipschitz constant of the model must grow to infinity. This implies that such methods are necessarily more susceptible to adversarial attacks. We demonstrate our theory on single image super-resolution algorithms, addressing both noisy and noiseless settings. We also show how this undesired behavior can be leveraged to explore the posterior distribution, thereby allowing the deterministic model to imitate stochastic methods.
BIRB: A Generalization Benchmark for Information Retrieval in Bioacoustics
Dec 13, 2023The ability for a machine learning model to cope with differences in training and deployment conditions--e.g. in the presence of distribution shift or the generalization to new classes altogether--is crucial for real-world use cases. However, most empirical work in this area has focused on the image domain with artificial benchmarks constructed to measure individual aspects of generalization. We present BIRB, a complex benchmark centered on the retrieval of bird vocalizations from passively-recorded datasets given focal recordings from a large citizen science corpus available for training. We propose a baseline system for this collection of tasks using representation learning and a nearest-centroid search. Our thorough empirical evaluation and analysis surfaces open research directions, suggesting that BIRB fills the need for a more realistic and complex benchmark to drive progress on robustness to distribution shifts and generalization of ML models.
PuzzleTuning: Explicitly Bridge Pathological and Natural Image with Puzzles
Nov 12, 2023Pathological image analysis is a crucial field in computer vision. Due to the annotation scarcity in the pathological field, recently, most of the works leverage self-supervised learning (SSL) trained on unlabeled pathological images, hoping to mine the main representation automatically. However, there are two core defects in SSL-based pathological pre-training: (1) they do not explicitly explore the essential focuses of the pathological field, and (2) they do not effectively bridge with and thus take advantage of the large natural image domain. To explicitly address them, we propose our large-scale PuzzleTuning framework, containing the following innovations. Firstly, we identify three task focuses that can effectively bridge pathological and natural domains: appearance consistency, spatial consistency, and misalignment understanding. Secondly, we devise a multiple puzzle restoring task to explicitly pre-train the model with these focuses. Thirdly, for the existing large domain gap between natural and pathological fields, we introduce an explicit prompt-tuning process to incrementally integrate the domain-specific knowledge with the natural knowledge. Additionally, we design a curriculum-learning training strategy that regulates the task difficulty, making the model fit the complex multiple puzzle restoring task adaptively. Experimental results show that our PuzzleTuning framework outperforms the previous SOTA methods in various downstream tasks on multiple datasets. The code, demo, and pre-trained weights are available at https://github.com/sagizty/PuzzleTuning.
Detecting and Restoring Non-Standard Hands in Stable Diffusion Generated Images
Dec 07, 2023We introduce a pipeline to address anatomical inaccuracies in Stable Diffusion generated hand images. The initial step involves constructing a specialized dataset, focusing on hand anomalies, to train our models effectively. A finetuned detection model is pivotal for precise identification of these anomalies, ensuring targeted correction. Body pose estimation aids in understanding hand orientation and positioning, crucial for accurate anomaly correction. The integration of ControlNet and InstructPix2Pix facilitates sophisticated inpainting and pixel-level transformation, respectively. This dual approach allows for high-fidelity image adjustments. This comprehensive approach ensures the generation of images with anatomically accurate hands, closely resembling real-world appearances. Our experimental results demonstrate the pipeline's efficacy in enhancing hand image realism in Stable Diffusion outputs. We provide an online demo at https://fixhand.yiqun.io