 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Robustness and Visual Explanation for Black Box Image, Video, and ECG Signal Classification with Reinforcement Learning
Mar 27, 2024
We present a generic Reinforcement Learning (RL) framework optimized for crafting adversarial attacks on different model types spanning from ECG signal analysis (1D), image classification (2D), and video classification (3D). The framework focuses on identifying sensitive regions and inducing misclassifications with minimal distortions and various distortion types. The novel RL method outperforms state-of-the-art methods for all three applications, proving its efficiency. Our RL approach produces superior localization masks, enhancing interpretability for image classification and ECG analysis models. For applications such as ECG analysis, our platform highlights critical ECG segments for clinicians while ensuring resilience against prevalent distortions. This comprehensive tool aims to bolster both resilience with adversarial training and transparency across varied applications and data types.
* AAAI Proceedings reference: https://ojs.aaai.org/index.php/AAAI/article/view/30579
Making Old Kurdish Publications Processable by Augmenting Available Optical Character Recognition Engines
Apr 09, 2024Kurdish libraries have many historical publications that were printed back in the early days when printing devices were brought to Kurdistan. Having a good Optical Character Recognition (OCR) to help process these publications and contribute to the Kurdish languages resources which is crucial as Kurdish is considered a low-resource language. Current OCR systems are unable to extract text from historical documents as they have many issues, including being damaged, very fragile, having many marks left on them, and often written in non-standard fonts and more. This is a massive obstacle in processing these documents as currently processing them requires manual typing which is very time-consuming. In this study, we adopt an open-source OCR framework by Google, Tesseract version 5.0, that has been used to extract text for various languages. Currently, there is no public dataset, and we developed our own by collecting historical documents from Zheen Center for Documentation and Research, which were printed before 1950 and resulted in a dataset of 1233 images of lines with transcription of each. Then we used the Arabic model as our base model and trained the model using the dataset. We used different methods to evaluate our model, Tesseracts built-in evaluator lstmeval indicated a Character Error Rate (CER) of 0.755%. Additionally, Ocreval demonstrated an average character accuracy of 84.02%. Finally, we developed a web application to provide an easy- to-use interface for end-users, allowing them to interact with the model by inputting an image of a page and extracting the text. Having an extensive dataset is crucial to develop OCR systems with reasonable accuracy, as currently, no public datasets are available for historical Kurdish documents; this posed a significant challenge in our work. Additionally, the unaligned spaces between characters and words proved another challenge with our work.
Depth Estimation fusing Image and Radar Measurements with Uncertain Directions
Mar 23, 2024This paper proposes a depth estimation method using radar-image fusion by addressing the uncertain vertical directions of sparse radar measurements. In prior radar-image fusion work, image features are merged with the uncertain sparse depths measured by radar through convolutional layers. This approach is disturbed by the features computed with the uncertain radar depths. Furthermore, since the features are computed with a fully convolutional network, the uncertainty of each depth corresponding to a pixel is spread out over its surrounding pixels. Our method avoids this problem by computing features only with an image and conditioning the features pixelwise with the radar depth. Furthermore, the set of possibly correct radar directions is identified with reliable LiDAR measurements, which are available only in the training stage. Our method improves training data by learning only these possibly correct radar directions, while the previous method trains raw radar measurements, including erroneous measurements. Experimental results demonstrate that our method can improve the quantitative and qualitative results compared with its base method using radar-image fusion.
Pseudo-MRI-Guided PET Image Reconstruction Method Based on a Diffusion Probabilistic Model
Mar 26, 2024Anatomically guided PET reconstruction using MRI information has been shown to have the potential to improve PET image quality. However, these improvements are limited to PET scans with paired MRI information. In this work we employed a diffusion probabilistic model (DPM) to infer T1-weighted-MRI (deep-MRI) images from FDG-PET brain images. We then use the DPM-generated T1w-MRI to guide the PET reconstruction. The model was trained with brain FDG scans, and tested in datasets containing multiple levels of counts. Deep-MRI images appeared somewhat degraded than the acquired MRI images. Regarding PET image quality, volume of interest analysis in different brain regions showed that both PET reconstructed images using the acquired and the deep-MRI images improved image quality compared to OSEM. Same conclusions were found analysing the decimated datasets. A subjective evaluation performed by two physicians confirmed that OSEM scored consistently worse than the MRI-guided PET images and no significant differences were observed between the MRI-guided PET images. This proof of concept shows that it is possible to infer DPM-based MRI imagery to guide the PET reconstruction, enabling the possibility of changing reconstruction parameters such as the strength of the prior on anatomically guided PET reconstruction in the absence of MRI.
GaSpCT: Gaussian Splatting for Novel CT Projection View Synthesis
Apr 04, 2024We present GaSpCT, a novel view synthesis and 3D scene representation method used to generate novel projection views for Computer Tomography (CT) scans. We adapt the Gaussian Splatting framework to enable novel view synthesis in CT based on limited sets of 2D image projections and without the need for Structure from Motion (SfM) methodologies. Therefore, we reduce the total scanning duration and the amount of radiation dose the patient receives during the scan. We adapted the loss function to our use-case by encouraging a stronger background and foreground distinction using two sparsity promoting regularizers: a beta loss and a total variation (TV) loss. Finally, we initialize the Gaussian locations across the 3D space using a uniform prior distribution of where the brain's positioning would be expected to be within the field of view. We evaluate the performance of our model using brain CT scans from the Parkinson's Progression Markers Initiative (PPMI) dataset and demonstrate that the rendered novel views closely match the original projection views of the simulated scan, and have better performance than other implicit 3D scene representations methodologies. Furthermore, we empirically observe reduced training time compared to neural network based image synthesis for sparse-view CT image reconstruction. Finally, the memory requirements of the Gaussian Splatting representations are reduced by 17% compared to the equivalent voxel grid image representations.
MIST: Mitigating Intersectional Bias with Disentangled Cross-Attention Editing in Text-to-Image Diffusion Models
Mar 28, 2024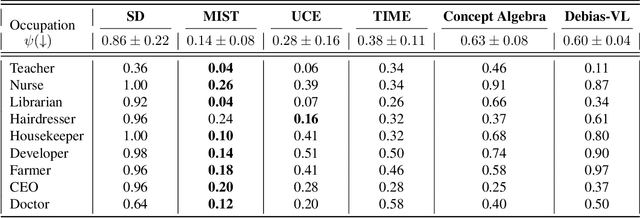
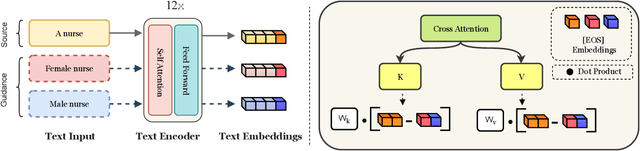
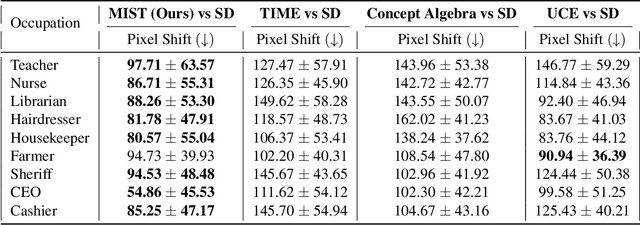

Diffusion-based text-to-image models have rapidly gained popularity for their ability to generate detailed and realistic images from textual descriptions. However, these models often reflect the biases present in their training data, especially impacting marginalized groups. While prior efforts to debias language models have focused on addressing specific biases, such as racial or gender biases, efforts to tackle intersectional bias have been limited. Intersectional bias refers to the unique form of bias experienced by individuals at the intersection of multiple social identities. Addressing intersectional bias is crucial because it amplifies the negative effects of discrimination based on race, gender, and other identities. In this paper, we introduce a method that addresses intersectional bias in diffusion-based text-to-image models by modifying cross-attention maps in a disentangled manner. Our approach utilizes a pre-trained Stable Diffusion model, eliminates the need for an additional set of reference images, and preserves the original quality for unaltered concepts. Comprehensive experiments demonstrate that our method surpasses existing approaches in mitigating both single and intersectional biases across various attributes. We make our source code and debiased models for various attributes available to encourage fairness in generative models and to support further research.
Unsupervised Intrinsic Image Decomposition with LiDAR Intensity Enhanced Training
Mar 21, 2024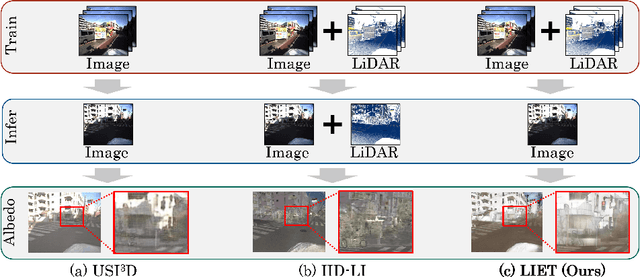
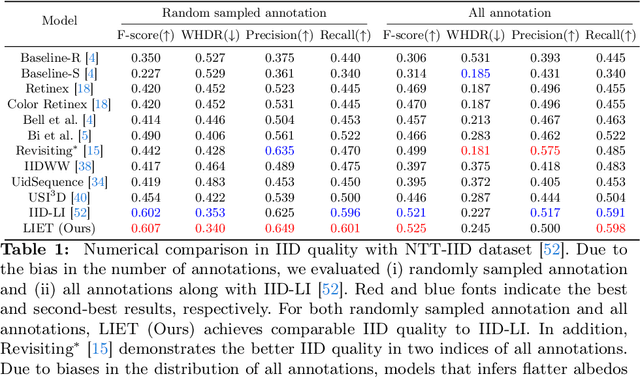


Unsupervised intrinsic image decomposition (IID) is the process of separating a natural image into albedo and shade without these ground truths. A recent model employing light detection and ranging (LiDAR) intensity demonstrated impressive performance, though the necessity of LiDAR intensity during inference restricts its practicality. Thus, IID models employing only a single image during inference while keeping as high IID quality as the one with an image plus LiDAR intensity are highly desired. To address this challenge, we propose a novel approach that utilizes only an image during inference while utilizing an image and LiDAR intensity during training. Specifically, we introduce a partially-shared model that accepts an image and LiDAR intensity individually using a different specific encoder but processes them together in specific components to learn shared representations. In addition, to enhance IID quality, we propose albedo-alignment loss and image-LiDAR conversion (ILC) paths. Albedo-alignment loss aligns the gray-scale albedo from an image to that inferred from LiDAR intensity, thereby reducing cast shadows in albedo from an image due to the absence of cast shadows in LiDAR intensity. Furthermore, to translate the input image into albedo and shade style while keeping the image contents, the input image is separated into style code and content code by encoders. The ILC path mutually translates the image and LiDAR intensity, which share content but differ in style, contributing to the distinct differentiation of style from content. Consequently, LIET achieves comparable IID quality to the existing model with LiDAR intensity, while utilizing only an image without LiDAR intensity during inference.
Study of the effect of Sharpness on Blind Video Quality Assessment
Apr 06, 2024Introduction: Video Quality Assessment (VQA) is one of the important areas of study in this modern era, where video is a crucial component of communication with applications in every field. Rapid technology developments in mobile technology enabled anyone to create videos resulting in a varied range of video quality scenarios. Objectives: Though VQA was present for some time with the classical metrices like SSIM and PSNR, the advent of machine learning has brought in new techniques of VQAs which are built upon Convolutional Neural Networks (CNNs) or Deep Neural Networks (DNNs). Methods: Over the past years various research studies such as the BVQA which performed video quality assessment of nature-based videos using DNNs exposed the powerful capabilities of machine learning algorithms. BVQA using DNNs explored human visual system effects such as content dependency and time-related factors normally known as temporal effects. Results: This study explores the sharpness effect on models like BVQA. Sharpness is the measure of the clarity and details of the video image. Sharpness typically involves analyzing the edges and contrast of the image to determine the overall level of detail and sharpness. Conclusion: This study uses the existing video quality databases such as CVD2014. A comparative study of the various machine learning parameters such as SRCC and PLCC during the training and testing are presented along with the conclusion.
Isolated Diffusion: Optimizing Multi-Concept Text-to-Image Generation Training-Freely with Isolated Diffusion Guidance
Mar 25, 2024Large-scale text-to-image diffusion models have achieved great success in synthesizing high-quality and diverse images given target text prompts. Despite the revolutionary image generation ability, current state-of-the-art models still struggle to deal with multi-concept generation accurately in many cases. This phenomenon is known as ``concept bleeding" and displays as the unexpected overlapping or merging of various concepts. This paper presents a general approach for text-to-image diffusion models to address the mutual interference between different subjects and their attachments in complex scenes, pursuing better text-image consistency. The core idea is to isolate the synthesizing processes of different concepts. We propose to bind each attachment to corresponding subjects separately with split text prompts. Besides, we introduce a revision method to fix the concept bleeding problem in multi-subject synthesis. We first depend on pre-trained object detection and segmentation models to obtain the layouts of subjects. Then we isolate and resynthesize each subject individually with corresponding text prompts to avoid mutual interference. Overall, we achieve a training-free strategy, named Isolated Diffusion, to optimize multi-concept text-to-image synthesis. It is compatible with the latest Stable Diffusion XL (SDXL) and prior Stable Diffusion (SD) models. We compare our approach with alternative methods using a variety of multi-concept text prompts and demonstrate its effectiveness with clear advantages in text-image consistency and user study.
Learning Topology Uniformed Face Mesh by Volume Rendering for Multi-view Reconstruction
Apr 08, 2024Face meshes in consistent topology serve as the foundation for many face-related applications, such as 3DMM constrained face reconstruction and expression retargeting. Traditional methods commonly acquire topology uniformed face meshes by two separate steps: multi-view stereo (MVS) to reconstruct shapes followed by non-rigid registration to align topology, but struggles with handling noise and non-lambertian surfaces. Recently neural volume rendering techniques have been rapidly evolved and shown great advantages in 3D reconstruction or novel view synthesis. Our goal is to leverage the superiority of neural volume rendering into multi-view reconstruction of face mesh with consistent topology. We propose a mesh volume rendering method that enables directly optimizing mesh geometry while preserving topology, and learning implicit features to model complex facial appearance from multi-view images. The key innovation lies in spreading sparse mesh features into the surrounding space to simulate radiance field required for volume rendering, which facilitates backpropagation of gradients from images to mesh geometry and implicit appearance features. Our proposed feature spreading module exhibits deformation invariance, enabling photorealistic rendering seamlessly after mesh editing. We conduct experiments on multi-view face image dataset to evaluate the reconstruction and implement an application for photorealistic rendering of animated face mesh.