 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Pseudo Label-Guided Data Fusion and Output Consistency for Semi-Supervised Medical Image Segmentation
Nov 17, 2023
Supervised learning algorithms based on Convolutional Neural Networks have become the benchmark for medical image segmentation tasks, but their effectiveness heavily relies on a large amount of labeled data. However, annotating medical image datasets is a laborious and time-consuming process. Inspired by semi-supervised algorithms that use both labeled and unlabeled data for training, we propose the PLGDF framework, which builds upon the mean teacher network for segmenting medical images with less annotation. We propose a novel pseudo-label utilization scheme, which combines labeled and unlabeled data to augment the dataset effectively. Additionally, we enforce the consistency between different scales in the decoder module of the segmentation network and propose a loss function suitable for evaluating the consistency. Moreover, we incorporate a sharpening operation on the predicted results, further enhancing the accuracy of the segmentation. Extensive experiments on three publicly available datasets demonstrate that the PLGDF framework can largely improve performance by incorporating the unlabeled data. Meanwhile, our framework yields superior performance compared to six state-of-the-art semi-supervised learning methods. The codes of this study are available at https://github.com/ortonwang/PLGDF.
Free3D: Consistent Novel View Synthesis without 3D Representation
Dec 07, 2023We introduce Free3D, a simple approach designed for open-set novel view synthesis (NVS) from a single image. Similar to Zero-1-to-3, we start from a pre-trained 2D image generator for generalization, and fine-tune it for NVS. Compared to recent and concurrent works, we obtain significant improvements without resorting to an explicit 3D representation, which is slow and memory-consuming or training an additional 3D network. We do so by encoding better the target camera pose via a new per-pixel ray conditioning normalization (RCN) layer. The latter injects pose information in the underlying 2D image generator by telling each pixel its specific viewing direction. We also improve multi-view consistency via a light-weight multi-view attention layer and multi-view noise sharing. We train Free3D on the Objaverse dataset and demonstrate excellent generalization to various new categories in several new datasets, including OminiObject3D and GSO. We hope our simple and effective approach will serve as a solid baseline and help future research in NVS with more accuracy pose. The project page is available at https://chuanxiaz.com/free3d/.
CAD: Photorealistic 3D Generation via Adversarial Distillation
Dec 11, 2023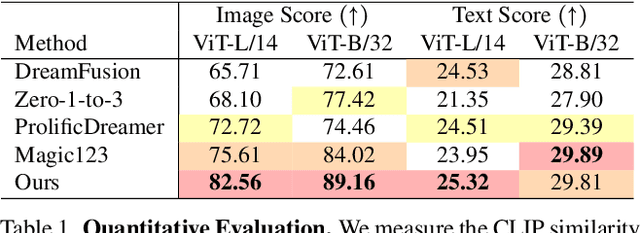
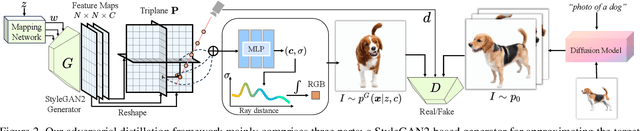
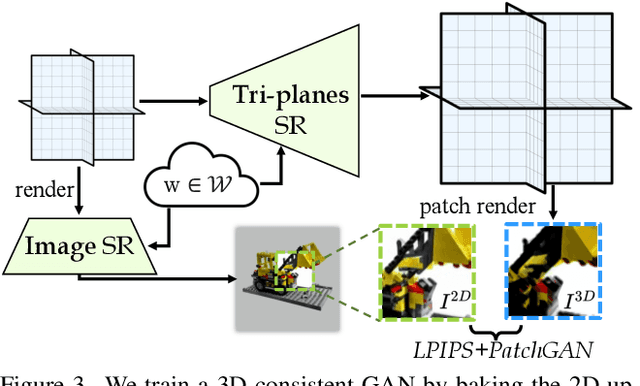

The increased demand for 3D data in AR/VR, robotics and gaming applications, gave rise to powerful generative pipelines capable of synthesizing high-quality 3D objects. Most of these models rely on the Score Distillation Sampling (SDS) algorithm to optimize a 3D representation such that the rendered image maintains a high likelihood as evaluated by a pre-trained diffusion model. However, finding a correct mode in the high-dimensional distribution produced by the diffusion model is challenging and often leads to issues such as over-saturation, over-smoothing, and Janus-like artifacts. In this paper, we propose a novel learning paradigm for 3D synthesis that utilizes pre-trained diffusion models. Instead of focusing on mode-seeking, our method directly models the distribution discrepancy between multi-view renderings and diffusion priors in an adversarial manner, which unlocks the generation of high-fidelity and photorealistic 3D content, conditioned on a single image and prompt. Moreover, by harnessing the latent space of GANs and expressive diffusion model priors, our method facilitates a wide variety of 3D applications including single-view reconstruction, high diversity generation and continuous 3D interpolation in the open domain. The experiments demonstrate the superiority of our pipeline compared to previous works in terms of generation quality and diversity.
Style Injection in Diffusion: A Training-free Approach for Adapting Large-scale Diffusion Models for Style Transfer
Dec 11, 2023Despite the impressive generative capabilities of diffusion models, existing diffusion model-based style transfer methods require inference-stage optimization (e.g. fine-tuning or textual inversion of style) which is time-consuming, or fails to leverage the generative ability of large-scale diffusion models. To address these issues, we introduce a novel artistic style transfer method based on a pre-trained large-scale diffusion model without any optimization. Specifically, we manipulate the features of self-attention layers as the way the cross-attention mechanism works; in the generation process, substituting the key and value of content with those of style image. This approach provides several desirable characteristics for style transfer including 1) preservation of content by transferring similar styles into similar image patches and 2) transfer of style based on similarity of local texture (e.g. edge) between content and style images. Furthermore, we introduce query preservation and attention temperature scaling to mitigate the issue of disruption of original content, and initial latent Adaptive Instance Normalization (AdaIN) to deal with the disharmonious color (failure to transfer the colors of style). Our experimental results demonstrate that our proposed method surpasses state-of-the-art methods in both conventional and diffusion-based style transfer baselines.
Visible to Thermal image Translation for improving visual task in low light conditions
Nov 09, 2023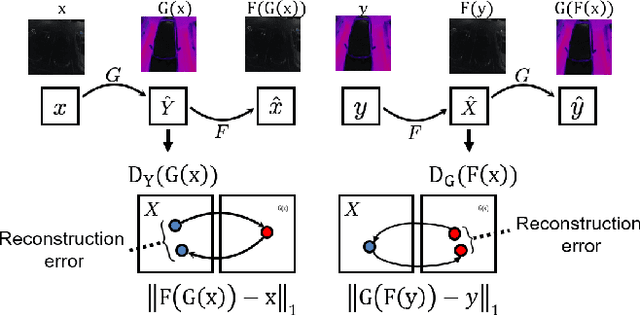
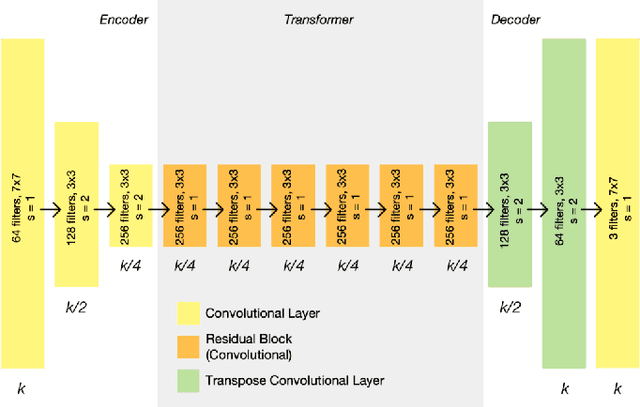
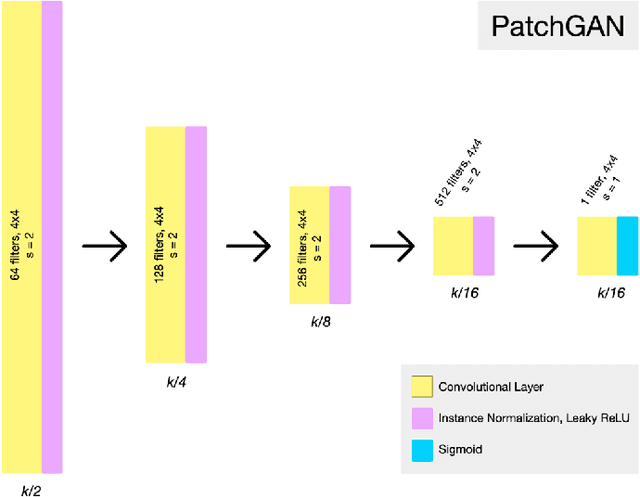
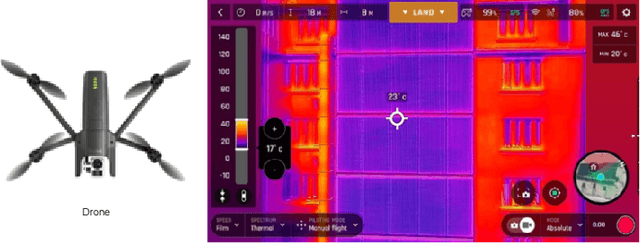
Several visual tasks, such as pedestrian detection and image-to-image translation, are challenging to accomplish in low light using RGB images. Heat variation of objects in thermal images can be used to overcome this. In this work, an end-to-end framework, which consists of a generative network and a detector network, is proposed to translate RGB image into Thermal ones and compare generated thermal images with real data. We have collected images from two different locations using the Parrot Anafi Thermal drone. After that, we created a two-stream network, preprocessed, augmented, the image data, and trained the generator and discriminator models from scratch. The findings demonstrate that it is feasible to translate RGB training data to thermal data using GAN. As a result, thermal data can now be produced more quickly and affordably, which is useful for security and surveillance applications.
p-Laplacian Adaptation for Generative Pre-trained Vision-Language Models
Dec 17, 2023Vision-Language models (VLMs) pre-trained on large corpora have demonstrated notable success across a range of downstream tasks. In light of the rapidly increasing size of pre-trained VLMs, parameter-efficient transfer learning (PETL) has garnered attention as a viable alternative to full fine-tuning. One such approach is the adapter, which introduces a few trainable parameters into the pre-trained models while preserving the original parameters during adaptation. In this paper, we present a novel modeling framework that recasts adapter tuning after attention as a graph message passing process on attention graphs, where the projected query and value features and attention matrix constitute the node features and the graph adjacency matrix, respectively. Within this framework, tuning adapters in VLMs necessitates handling heterophilic graphs, owing to the disparity between the projected query and value space. To address this challenge, we propose a new adapter architecture, $p$-adapter, which employs $p$-Laplacian message passing in Graph Neural Networks (GNNs). Specifically, the attention weights are re-normalized based on the features, and the features are then aggregated using the calibrated attention matrix, enabling the dynamic exploitation of information with varying frequencies in the heterophilic attention graphs. We conduct extensive experiments on different pre-trained VLMs and multi-modal tasks, including visual question answering, visual entailment, and image captioning. The experimental results validate our method's significant superiority over other PETL methods.
Classification for everyone : Building geography agnostic models for fairer recognition
Dec 11, 2023In this paper, we analyze different methods to mitigate inherent geographical biases present in state of the art image classification models. We first quantitatively present this bias in two datasets - The Dollar Street Dataset and ImageNet, using images with location information. We then present different methods which can be employed to reduce this bias. Finally, we analyze the effectiveness of the different techniques on making these models more robust to geographical locations of the images.
Rethinking Robustness of Model Attributions
Dec 16, 2023For machine learning models to be reliable and trustworthy, their decisions must be interpretable. As these models find increasing use in safety-critical applications, it is important that not just the model predictions but also their explanations (as feature attributions) be robust to small human-imperceptible input perturbations. Recent works have shown that many attribution methods are fragile and have proposed improvements in either these methods or the model training. We observe two main causes for fragile attributions: first, the existing metrics of robustness (e.g., top-k intersection) over-penalize even reasonable local shifts in attribution, thereby making random perturbations to appear as a strong attack, and second, the attribution can be concentrated in a small region even when there are multiple important parts in an image. To rectify this, we propose simple ways to strengthen existing metrics and attribution methods that incorporate locality of pixels in robustness metrics and diversity of pixel locations in attributions. Towards the role of model training in attributional robustness, we empirically observe that adversarially trained models have more robust attributions on smaller datasets, however, this advantage disappears in larger datasets. Code is available at https://github.com/ksandeshk/LENS.
Robustness of Deep Learning for Accelerated MRI: Benefits of Diverse Training Data
Dec 16, 2023Deep learning based methods for image reconstruction are state-of-the-art for a variety of imaging tasks. However, neural networks often perform worse if the training data differs significantly from the data they are applied to. For example, a network trained for accelerated magnetic resonance imaging (MRI) on one scanner performs worse on another scanner. In this work, we investigate the impact of the training data on the model's performance and robustness for accelerated MRI. We find that models trained on the combination of various data distributions, such as those obtained from different MRI scanners and anatomies, exhibit robustness equal or superior to models trained on the best single distribution for a specific target distribution. Thus training on diverse data tends to improve robustness. Furthermore, training on diverse data does not compromise in-distribution performance, i.e., a model trained on diverse data yields in-distribution performance at least as good as models trained on the more narrow individual distributions. Our results suggest that training a model for imaging on a variety of distributions tends to yield a more effective and robust model than maintaining separate models for individual distributions.
Medical Image Segmentation with Domain Adaptation: A Survey
Nov 03, 2023Deep learning (DL) has shown remarkable success in various medical imaging data analysis applications. However, it remains challenging for DL models to achieve good generalization, especially when the training and testing datasets are collected at sites with different scanners, due to domain shift caused by differences in data distributions. Domain adaptation has emerged as an effective means to address this challenge by mitigating domain gaps in medical imaging applications. In this review, we specifically focus on domain adaptation approaches for DL-based medical image segmentation. We first present the motivation and background knowledge underlying domain adaptations, then provide a comprehensive review of domain adaptation applications in medical image segmentations, and finally discuss the challenges, limitations, and future research trends in the field to promote the methodology development of domain adaptation in the context of medical image segmentation. Our goal was to provide researchers with up-to-date references on the applications of domain adaptation in medical image segmentation studies.