 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Research on Multilingual Natural Scene Text Detection Algorithm
Dec 18, 2023
Natural scene text detection is a significant challenge in computer vision, with tremendous potential applications in multilingual, diverse, and complex text scenarios. We propose a multilingual text detection model to address the issues of low accuracy and high difficulty in detecting multilingual text in natural scenes. In response to the challenges posed by multilingual text images with multiple character sets and various font styles, we introduce the SFM Swin Transformer feature extraction network to enhance the model's robustness in detecting characters and fonts across different languages. Dealing with the considerable variation in text scales and complex arrangements in natural scene text images, we present the AS-HRFPN feature fusion network by incorporating an Adaptive Spatial Feature Fusion module and a Spatial Pyramid Pooling module. The feature fusion network improvements enhance the model's ability to detect text sizes and orientations. Addressing diverse backgrounds and font variations in multilingual scene text images is a challenge for existing methods. Limited local receptive fields hinder detection performance. To overcome this, we propose a Global Semantic Segmentation Branch, extracting and preserving global features for more effective text detection, aligning with the need for comprehensive information. In this study, we collected and built a real-world multilingual natural scene text image dataset and conducted comprehensive experiments and analyses. The experimental results demonstrate that the proposed algorithm achieves an F-measure of 85.02\%, which is 4.71\% higher than the baseline model. We also conducted extensive cross-dataset validation on MSRA-TD500, ICDAR2017MLT, and ICDAR2015 datasets to verify the generality of our approach. The code and dataset can be found at https://github.com/wangmelon/CEMLT.
Layerwise complexity-matched learning yields an improved model of cortical area V2
Dec 18, 2023Human ability to recognize complex visual patterns arises through transformations performed by successive areas in the ventral visual cortex. Deep neural networks trained end-to-end for object recognition approach human capabilities, and offer the best descriptions to date of neural responses in the late stages of the hierarchy. But these networks provide a poor account of the early stages, compared to traditional hand-engineered models, or models optimized for coding efficiency or prediction. Moreover, the gradient backpropagation used in end-to-end learning is generally considered to be biologically implausible. Here, we overcome both of these limitations by developing a bottom-up self-supervised training methodology that operates independently on successive layers. Specifically, we maximize feature similarity between pairs of locally-deformed natural image patches, while decorrelating features across patches sampled from other images. Crucially, the deformation amplitudes are adjusted proportionally to receptive field sizes in each layer, thus matching the task complexity to the capacity at each stage of processing. In comparison with architecture-matched versions of previous models, we demonstrate that our layerwise complexity-matched learning (LCL) formulation produces a two-stage model (LCL-V2) that is better aligned with selectivity properties and neural activity in primate area V2. We demonstrate that the complexity-matched learning paradigm is critical for the emergence of the improved biological alignment. Finally, when the two-stage model is used as a fixed front-end for a deep network trained to perform object recognition, the resultant model (LCL-V2Net) is significantly better than standard end-to-end self-supervised, supervised, and adversarially-trained models in terms of generalization to out-of-distribution tasks and alignment with human behavior.
Classification for everyone : Building geography agnostic models for fairer recognition
Dec 11, 2023In this paper, we analyze different methods to mitigate inherent geographical biases present in state of the art image classification models. We first quantitatively present this bias in two datasets - The Dollar Street Dataset and ImageNet, using images with location information. We then present different methods which can be employed to reduce this bias. Finally, we analyze the effectiveness of the different techniques on making these models more robust to geographical locations of the images.
Thermal Face Image Classification using Deep Learning Techniques
Nov 04, 2023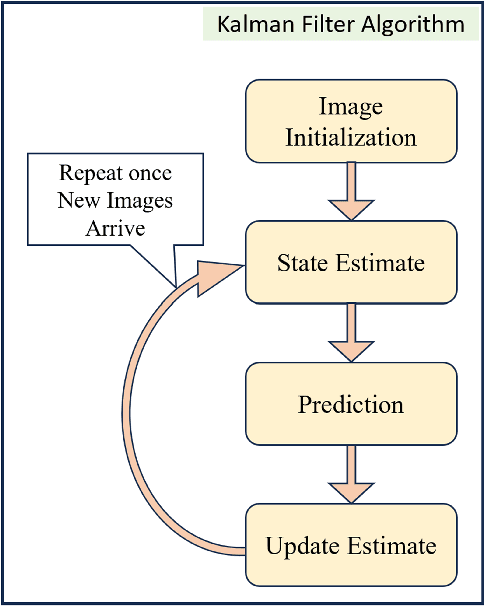
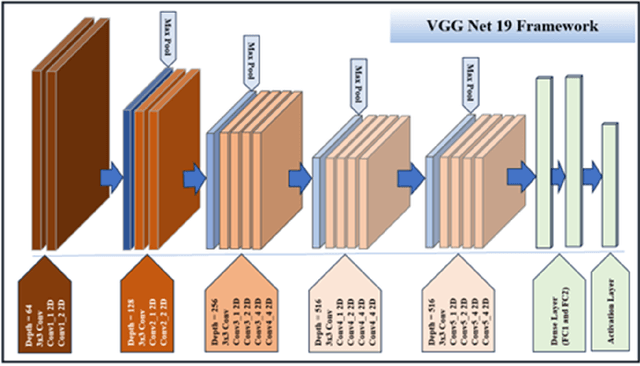
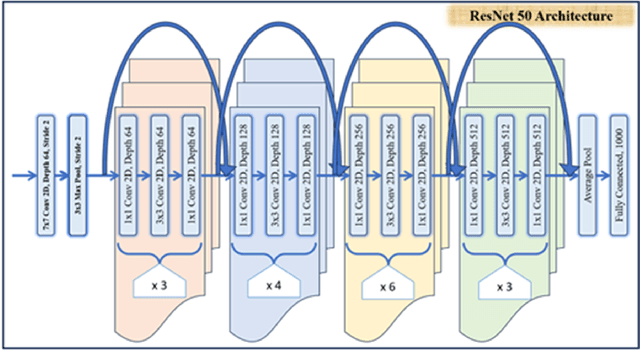
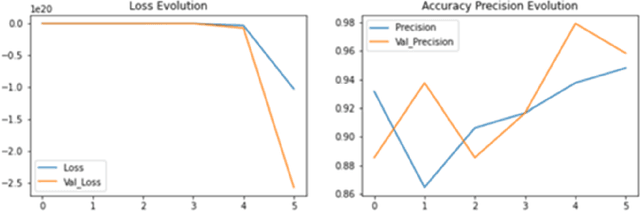
Thermal images have various applications in security, medical and industrial domains. This paper proposes a practical deep-learning approach for thermal image classification. Accurate and efficient classification of thermal images poses a significant challenge across various fields due to the complex image content and the scarcity of annotated datasets. This work uses a convolutional neural network (CNN) architecture, specifically ResNet-50 and VGGNet-19, to extract features from thermal images. This work also applied Kalman filter on thermal input images for image denoising. The experimental results demonstrate the effectiveness of the proposed approach in terms of accuracy and efficiency.
CLAMP: Contrastive LAnguage Model Prompt-tuning
Dec 04, 2023Large language models (LLMs) have emerged as powerful general-purpose interfaces for many machine learning problems. Recent work has adapted LLMs to generative visual tasks like image captioning, visual question answering, and visual chat, using a relatively small amount of instruction-tuning data. In this paper, we explore whether modern LLMs can also be adapted to classifying an image into a set of categories. First, we evaluate multimodal LLMs that are tuned for generative tasks on zero-shot image classification and find that their performance is far below that of specialized models like CLIP. We then propose an approach for light fine-tuning of LLMs using the same contrastive image-caption matching objective as CLIP. Our results show that LLMs can, indeed, achieve good image classification performance when adapted this way. Our approach beats state-of-the-art mLLMs by 13% and slightly outperforms contrastive learning with a custom text model, while also retaining the LLM's generative abilities. LLM initialization appears to particularly help classification in domains under-represented in the visual pre-training data.
Free3D: Consistent Novel View Synthesis without 3D Representation
Dec 07, 2023We introduce Free3D, a simple approach designed for open-set novel view synthesis (NVS) from a single image. Similar to Zero-1-to-3, we start from a pre-trained 2D image generator for generalization, and fine-tune it for NVS. Compared to recent and concurrent works, we obtain significant improvements without resorting to an explicit 3D representation, which is slow and memory-consuming or training an additional 3D network. We do so by encoding better the target camera pose via a new per-pixel ray conditioning normalization (RCN) layer. The latter injects pose information in the underlying 2D image generator by telling each pixel its specific viewing direction. We also improve multi-view consistency via a light-weight multi-view attention layer and multi-view noise sharing. We train Free3D on the Objaverse dataset and demonstrate excellent generalization to various new categories in several new datasets, including OminiObject3D and GSO. We hope our simple and effective approach will serve as a solid baseline and help future research in NVS with more accuracy pose. The project page is available at https://chuanxiaz.com/free3d/.
Learning Physics-Inspired Regularization for Medical Image Registration with Hypernetworks
Nov 14, 2023Medical image registration aims at identifying the spatial deformation between images of the same anatomical region and is fundamental to image-based diagnostics and therapy. To date, the majority of the deep learning-based registration methods employ regularizers that enforce global spatial smoothness, e.g., the diffusion regularizer. However, such regularizers are not tailored to the data and might not be capable of reflecting the complex underlying deformation. In contrast, physics-inspired regularizers promote physically plausible deformations. One such regularizer is the linear elastic regularizer which models the deformation of elastic material. These regularizers are driven by parameters that define the material's physical properties. For biological tissue, a wide range of estimations of such parameters can be found in the literature and it remains an open challenge to identify suitable parameter values for successful registration. To overcome this problem and to incorporate physical properties into learning-based registration, we propose to use a hypernetwork that learns the effect of the physical parameters of a physics-inspired regularizer on the resulting spatial deformation field. In particular, we adapt the HyperMorph framework to learn the effect of the two elasticity parameters of the linear elastic regularizer. Our approach enables the efficient discovery of suitable, data-specific physical parameters at test time.
Frequency Domain Decomposition Translation for Enhanced Medical Image Translation Using GANs
Nov 06, 2023Medical Image-to-image translation is a key task in computer vision and generative artificial intelligence, and it is highly applicable to medical image analysis. GAN-based methods are the mainstream image translation methods, but they often ignore the variation and distribution of images in the frequency domain, or only take simple measures to align high-frequency information, which can lead to distortion and low quality of the generated images. To solve these problems, we propose a novel method called frequency domain decomposition translation (FDDT). This method decomposes the original image into a high-frequency component and a low-frequency component, with the high-frequency component containing the details and identity information, and the low-frequency component containing the style information. Next, the high-frequency and low-frequency components of the transformed image are aligned with the transformed results of the high-frequency and low-frequency components of the original image in the same frequency band in the spatial domain, thus preserving the identity information of the image while destroying as little stylistic information of the image as possible. We conduct extensive experiments on MRI images and natural images with FDDT and several mainstream baseline models, and we use four evaluation metrics to assess the quality of the generated images. Compared with the baseline models, optimally, FDDT can reduce Fr\'echet inception distance by up to 24.4%, structural similarity by up to 4.4%, peak signal-to-noise ratio by up to 5.8%, and mean squared error by up to 31%. Compared with the previous method, optimally, FDDT can reduce Fr\'echet inception distance by up to 23.7%, structural similarity by up to 1.8%, peak signal-to-noise ratio by up to 6.8%, and mean squared error by up to 31.6%.
An Incremental Unified Framework for Small Defect Inspection
Dec 14, 2023Artificial Intelligence (AI)-driven defect inspection is pivotal in industrial manufacturing. Yet, many methods, tailored to specific pipelines, grapple with diverse product portfolios and evolving processes. Addressing this, we present the Incremental Unified Framework (IUF) that can reduce the feature conflict problem when continuously integrating new objects in the pipeline, making it advantageous in object-incremental learning scenarios. Employing a state-of-the-art transformer, we introduce Object-Aware Self-Attention (OASA) to delineate distinct semantic boundaries. Semantic Compression Loss (SCL) is integrated to optimize non-primary semantic space, enhancing network adaptability for novel objects. Additionally, we prioritize retaining the features of established objects during weight updates. Demonstrating prowess in both image and pixel-level defect inspection, our approach achieves state-of-the-art performance, proving indispensable for dynamic and scalable industrial inspections. Our code will be released at https://github.com/jqtangust/IUF.
One-2-3-45++: Fast Single Image to 3D Objects with Consistent Multi-View Generation and 3D Diffusion
Nov 14, 2023Recent advancements in open-world 3D object generation have been remarkable, with image-to-3D methods offering superior fine-grained control over their text-to-3D counterparts. However, most existing models fall short in simultaneously providing rapid generation speeds and high fidelity to input images - two features essential for practical applications. In this paper, we present One-2-3-45++, an innovative method that transforms a single image into a detailed 3D textured mesh in approximately one minute. Our approach aims to fully harness the extensive knowledge embedded in 2D diffusion models and priors from valuable yet limited 3D data. This is achieved by initially finetuning a 2D diffusion model for consistent multi-view image generation, followed by elevating these images to 3D with the aid of multi-view conditioned 3D native diffusion models. Extensive experimental evaluations demonstrate that our method can produce high-quality, diverse 3D assets that closely mirror the original input image. Our project webpage: https://sudo-ai-3d.github.io/One2345plus_page.