 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
SinSR: Diffusion-Based Image Super-Resolution in a Single Step
Nov 23, 2023

While super-resolution (SR) methods based on diffusion models exhibit promising results, their practical application is hindered by the substantial number of required inference steps. Recent methods utilize degraded images in the initial state, thereby shortening the Markov chain. Nevertheless, these solutions either rely on a precise formulation of the degradation process or still necessitate a relatively lengthy generation path (e.g., 15 iterations). To enhance inference speed, we propose a simple yet effective method for achieving single-step SR generation, named SinSR. Specifically, we first derive a deterministic sampling process from the most recent state-of-the-art (SOTA) method for accelerating diffusion-based SR. This allows the mapping between the input random noise and the generated high-resolution image to be obtained in a reduced and acceptable number of inference steps during training. We show that this deterministic mapping can be distilled into a student model that performs SR within only one inference step. Additionally, we propose a novel consistency-preserving loss to simultaneously leverage the ground-truth image during the distillation process, ensuring that the performance of the student model is not solely bound by the feature manifold of the teacher model, resulting in further performance improvement. Extensive experiments conducted on synthetic and real-world datasets demonstrate that the proposed method can achieve comparable or even superior performance compared to both previous SOTA methods and the teacher model, in just one sampling step, resulting in a remarkable up to x10 speedup for inference. Our code will be released at https://github.com/wyf0912/SinSR
Segment Anything Model with Uncertainty Rectification for Auto-Prompting Medical Image Segmentation
Nov 17, 2023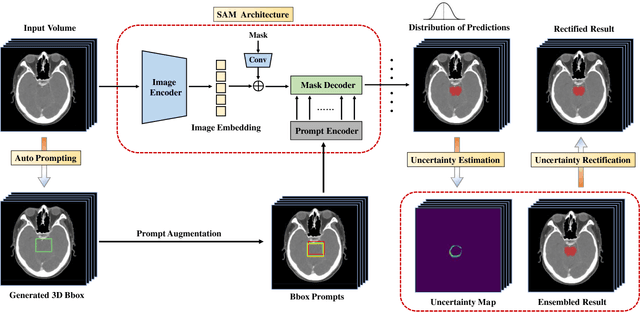
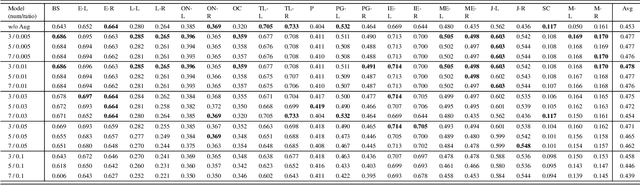
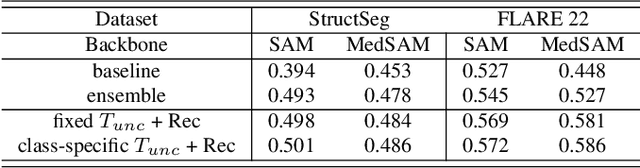
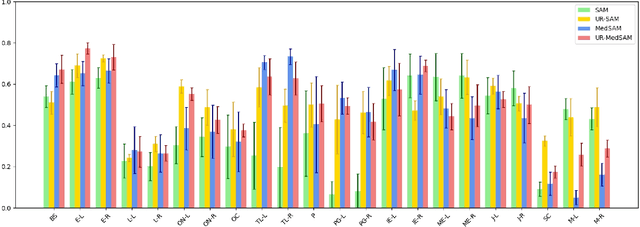
The introduction of the Segment Anything Model (SAM) has marked a significant advancement in prompt-driven image segmentation. However, SAM's application to medical image segmentation requires manual prompting of target structures to obtain acceptable performance, which is still labor-intensive. Despite attempts of auto-prompting to turn SAM into a fully automatic manner, it still exhibits subpar performance and lacks of reliability in the field of medical imaging. In this paper, we propose UR-SAM, an uncertainty rectified SAM framework to enhance the robustness and reliability for auto-prompting medical image segmentation. Our method incorporates a prompt augmentation module to estimate the distribution of predictions and generate uncertainty maps, and an uncertainty-based rectification module to further enhance the performance of SAM. Extensive experiments on two public 3D medical datasets covering the segmentation of 35 organs demonstrate that without supplementary training or fine-tuning, our method further improves the segmentation performance with up to 10.7 % and 13.8 % in dice similarity coefficient, demonstrating efficiency and broad capabilities for medical image segmentation without manual prompting.
CaLDiff: Camera Localization in NeRF via Pose Diffusion
Dec 23, 2023With the widespread use of NeRF-based implicit 3D representation, the need for camera localization in the same representation becomes manifestly apparent. Doing so not only simplifies the localization process -- by avoiding an outside-the-NeRF-based localization -- but also has the potential to offer the benefit of enhanced localization. This paper studies the problem of localizing cameras in NeRF using a diffusion model for camera pose adjustment. More specifically, given a pre-trained NeRF model, we train a diffusion model that iteratively updates randomly initialized camera poses, conditioned upon the image to be localized. At test time, a new camera is localized in two steps: first, coarse localization using the proposed pose diffusion process, followed by local refinement steps of a pose inversion process in NeRF. In fact, the proposed camera localization by pose diffusion (CaLDiff) method also integrates the pose inversion steps within the diffusion process. Such integration offers significantly better localization, thanks to our downstream refinement-aware diffusion process. Our exhaustive experiments on challenging real-world data validate our method by providing significantly better results than the compared methods and the established baselines. Our source code will be made publicly available.
The Chosen One: Consistent Characters in Text-to-Image Diffusion Models
Nov 27, 2023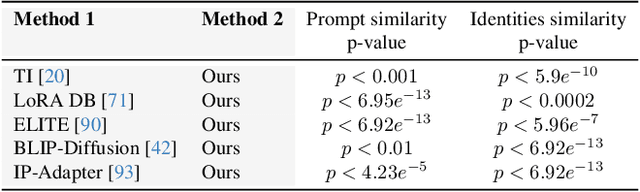


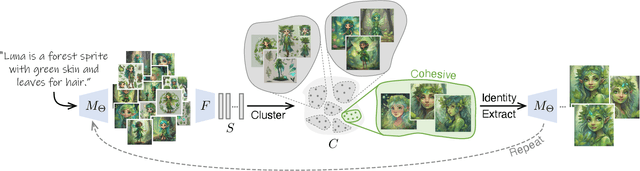
Recent advances in text-to-image generation models have unlocked vast potential for visual creativity. However, these models struggle with generation of consistent characters, a crucial aspect for numerous real-world applications such as story visualization, game development asset design, advertising, and more. Current methods typically rely on multiple pre-existing images of the target character or involve labor-intensive manual processes. In this work, we propose a fully automated solution for consistent character generation, with the sole input being a text prompt. We introduce an iterative procedure that, at each stage, identifies a coherent set of images sharing a similar identity and extracts a more consistent identity from this set. Our quantitative analysis demonstrates that our method strikes a better balance between prompt alignment and identity consistency compared to the baseline methods, and these findings are reinforced by a user study. To conclude, we showcase several practical applications of our approach. Project page is available at https://omriavrahami.com/the-chosen-one
Disentangling the Effects of Data Augmentation and Format Transform in Self-Supervised Learning of Image Representations
Dec 02, 2023Self-Supervised Learning (SSL) enables training performant models using limited labeled data. One of the pillars underlying vision SSL is the use of data augmentations/perturbations of the input which do not significantly alter its semantic content. For audio and other temporal signals, augmentations are commonly used alongside format transforms such as Fourier transforms or wavelet transforms. Unlike augmentations, format transforms do not change the information contained in the data; rather, they express the same information in different coordinates. In this paper, we study the effects of format transforms and augmentations both separately and together on vision SSL. We define augmentations in frequency space called Fourier Domain Augmentations (FDA) and show that training SSL models on a combination of these and image augmentations can improve the downstream classification accuracy by up to 1.3% on ImageNet-1K. We also show improvements against SSL baselines in few-shot and transfer learning setups using FDA. Surprisingly, we also observe that format transforms can improve the quality of learned representations even without augmentations; however, the combination of the two techniques yields better quality.
Keep the Faith: Faithful Explanations in Convolutional Neural Networks for Case-Based Reasoning
Dec 19, 2023Explaining predictions of black-box neural networks is crucial when applied to decision-critical tasks. Thus, attribution maps are commonly used to identify important image regions, despite prior work showing that humans prefer explanations based on similar examples. To this end, ProtoPNet learns a set of class-representative feature vectors (prototypes) for case-based reasoning. During inference, similarities of latent features to prototypes are linearly classified to form predictions and attribution maps are provided to explain the similarity. In this work, we evaluate whether architectures for case-based reasoning fulfill established axioms required for faithful explanations using the example of ProtoPNet. We show that such architectures allow the extraction of faithful explanations. However, we prove that the attribution maps used to explain the similarities violate the axioms. We propose a new procedure to extract explanations for trained ProtoPNets, named ProtoPFaith. Conceptually, these explanations are Shapley values, calculated on the similarity scores of each prototype. They allow to faithfully answer which prototypes are present in an unseen image and quantify each pixel's contribution to that presence, thereby complying with all axioms. The theoretical violations of ProtoPNet manifest in our experiments on three datasets (CUB-200-2011, Stanford Dogs, RSNA) and five architectures (ConvNet, ResNet, ResNet50, WideResNet50, ResNeXt50). Our experiments show a qualitative difference between the explanations given by ProtoPNet and ProtoPFaith. Additionally, we quantify the explanations with the Area Over the Perturbation Curve, on which ProtoPFaith outperforms ProtoPNet on all experiments by a factor $>10^3$.
Weakly Supervised Open-Vocabulary Object Detection
Dec 19, 2023Despite weakly supervised object detection (WSOD) being a promising step toward evading strong instance-level annotations, its capability is confined to closed-set categories within a single training dataset. In this paper, we propose a novel weakly supervised open-vocabulary object detection framework, namely WSOVOD, to extend traditional WSOD to detect novel concepts and utilize diverse datasets with only image-level annotations. To achieve this, we explore three vital strategies, including dataset-level feature adaptation, image-level salient object localization, and region-level vision-language alignment. First, we perform data-aware feature extraction to produce an input-conditional coefficient, which is leveraged into dataset attribute prototypes to identify dataset bias and help achieve cross-dataset generalization. Second, a customized location-oriented weakly supervised region proposal network is proposed to utilize high-level semantic layouts from the category-agnostic segment anything model to distinguish object boundaries. Lastly, we introduce a proposal-concept synchronized multiple-instance network, i.e., object mining and refinement with visual-semantic alignment, to discover objects matched to the text embeddings of concepts. Extensive experiments on Pascal VOC and MS COCO demonstrate that the proposed WSOVOD achieves new state-of-the-art compared with previous WSOD methods in both close-set object localization and detection tasks. Meanwhile, WSOVOD enables cross-dataset and open-vocabulary learning to achieve on-par or even better performance than well-established fully-supervised open-vocabulary object detection (FSOVOD).
Rotation-Agnostic Image Representation Learning for Digital Pathology
Nov 14, 2023This paper addresses complex challenges in histopathological image analysis through three key contributions. Firstly, it introduces a fast patch selection method, FPS, for whole-slide image (WSI) analysis, significantly reducing computational cost while maintaining accuracy. Secondly, it presents PathDino, a lightweight histopathology feature extractor with a minimal configuration of five Transformer blocks and only 9 million parameters, markedly fewer than alternatives. Thirdly, it introduces a rotation-agnostic representation learning paradigm using self-supervised learning, effectively mitigating overfitting. We also show that our compact model outperforms existing state-of-the-art histopathology-specific vision transformers on 12 diverse datasets, including both internal datasets spanning four sites (breast, liver, skin, and colorectal) and seven public datasets (PANDA, CAMELYON16, BRACS, DigestPath, Kather, PanNuke, and WSSS4LUAD). Notably, even with a training dataset of 6 million histopathology patches from The Cancer Genome Atlas (TCGA), our approach demonstrates an average 8.5% improvement in patch-level majority vote performance. These contributions provide a robust framework for enhancing image analysis in digital pathology, rigorously validated through extensive evaluation. Project Page: https://rhazeslab.github.io/PathDino-Page/
UFOGen: You Forward Once Large Scale Text-to-Image Generation via Diffusion GANs
Nov 17, 2023
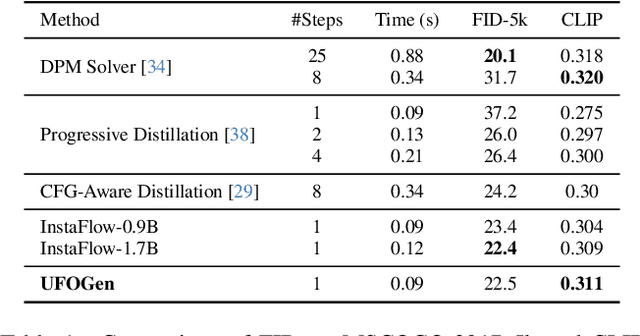
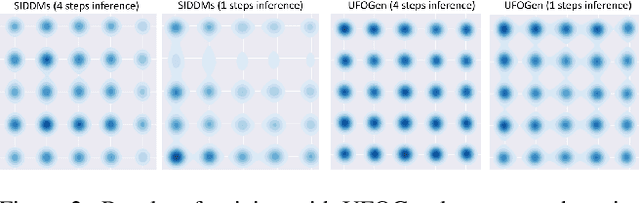
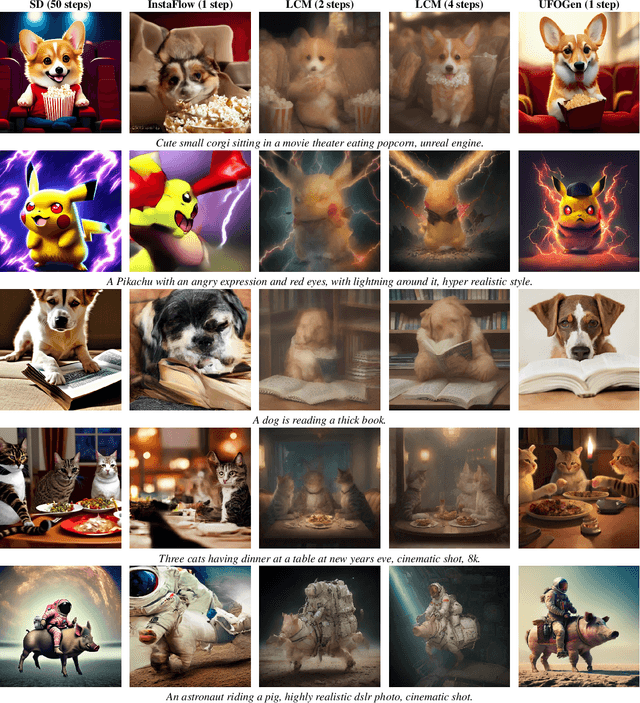
Text-to-image diffusion models have demonstrated remarkable capabilities in transforming textual prompts into coherent images, yet the computational cost of their inference remains a persistent challenge. To address this issue, we present UFOGen, a novel generative model designed for ultra-fast, one-step text-to-image synthesis. In contrast to conventional approaches that focus on improving samplers or employing distillation techniques for diffusion models, UFOGen adopts a hybrid methodology, integrating diffusion models with a GAN objective. Leveraging a newly introduced diffusion-GAN objective and initialization with pre-trained diffusion models, UFOGen excels in efficiently generating high-quality images conditioned on textual descriptions in a single step. Beyond traditional text-to-image generation, UFOGen showcases versatility in applications. Notably, UFOGen stands among the pioneering models enabling one-step text-to-image generation and diverse downstream tasks, presenting a significant advancement in the landscape of efficient generative models.
ProtoArgNet: Interpretable Image Classification with Super-Prototypes and Argumentation [Technical Report]
Nov 26, 2023We propose ProtoArgNet, a novel interpretable deep neural architecture for image classification in the spirit of prototypical-part-learning as found, e.g. in ProtoPNet. While earlier approaches associate every class with multiple prototypical-parts, ProtoArgNet uses super-prototypes that combine prototypical-parts into single prototypical class representations. Furthermore, while earlier approaches use interpretable classification layers, e.g. logistic regression in ProtoPNet, ProtoArgNet improves accuracy with multi-layer perceptrons while relying upon an interpretable reading thereof based on a form of argumentation. ProtoArgNet is customisable to user cognitive requirements by a process of sparsification of the multi-layer perceptron/argumentation component. Also, as opposed to other prototypical-part-learning approaches, ProtoArgNet can recognise spatial relations between different prototypical-parts that are from different regions in images, similar to how CNNs capture relations between patterns recognized in earlier layers.