 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Boosting3D: High-Fidelity Image-to-3D by Boosting 2D Diffusion Prior to 3D Prior with Progressive Learning
Nov 22, 2023
We present Boosting3D, a multi-stage single image-to-3D generation method that can robustly generate reasonable 3D objects in different data domains. The point of this work is to solve the view consistency problem in single image-guided 3D generation by modeling a reasonable geometric structure. For this purpose, we propose to utilize better 3D prior to training the NeRF. More specifically, we train an object-level LoRA for the target object using original image and the rendering output of NeRF. And then we train the LoRA and NeRF using a progressive training strategy. The LoRA and NeRF will boost each other while training. After the progressive training, the LoRA learns the 3D information of the generated object and eventually turns to an object-level 3D prior. In the final stage, we extract the mesh from the trained NeRF and use the trained LoRA to optimize the structure and appearance of the mesh. The experiments demonstrate the effectiveness of the proposed method. Boosting3D learns object-specific 3D prior which is beyond the ability of pre-trained diffusion priors and achieves state-of-the-art performance in the single image-to-3d generation task.
TULIP: Transformer for Upsampling of LiDAR Point Cloud
Dec 14, 2023LiDAR Upsampling is a challenging task for the perception systems of robots and autonomous vehicles, due to the sparse and irregular structure of large-scale scene contexts. Recent works propose to solve this problem by converting LiDAR data from 3D Euclidean space into an image super-resolution problem in 2D image space. Although their methods can generate high-resolution range images with fine-grained details, the resulting 3D point clouds often blur out details and predict invalid points. In this paper, we propose TULIP, a new method to reconstruct high-resolution LiDAR point clouds from low-resolution LiDAR input. We also follow a range image-based approach but specifically modify the patch and window geometries of a Swin-Transformer-based network to better fit the characteristics of range images. We conducted several experiments on three different public real-world and simulated datasets. TULIP outperforms state-of-the-art methods in all relevant metrics and generates robust and more realistic point clouds than prior works.
Check, Locate, Rectify: A Training-Free Layout Calibration System for Text-to-Image Generation
Nov 30, 2023Diffusion models have recently achieved remarkable progress in generating realistic images. However, challenges remain in accurately understanding and synthesizing the layout requirements in the textual prompts. To align the generated image with layout instructions, we present a training-free layout calibration system SimM that intervenes in the generative process on the fly during inference time. Specifically, following a "check-locate-rectify" pipeline, the system first analyses the prompt to generate the target layout and compares it with the intermediate outputs to automatically detect errors. Then, by moving the located activations and making intra- and inter-map adjustments, the rectification process can be performed with negligible computational overhead. To evaluate SimM over a range of layout requirements, we present a benchmark SimMBench that compensates for the lack of superlative spatial relations in existing datasets. And both quantitative and qualitative results demonstrate the effectiveness of the proposed SimM in calibrating the layout inconsistencies. Our project page is at https://simm-t2i.github.io/SimM.
Adversarial Item Promotion on Visually-Aware Recommender Systems by Guided Diffusion
Dec 25, 2023Visually-aware recommender systems have found widespread application in domains where visual elements significantly contribute to the inference of users' potential preferences. While the incorporation of visual information holds the promise of enhancing recommendation accuracy and alleviating the cold-start problem, it is essential to point out that the inclusion of item images may introduce substantial security challenges. Some existing works have shown that the item provider can manipulate item exposure rates to its advantage by constructing adversarial images. However, these works cannot reveal the real vulnerability of visually-aware recommender systems because (1) The generated adversarial images are markedly distorted, rendering them easily detectable by human observers; (2) The effectiveness of the attacks is inconsistent and even ineffective in some scenarios. To shed light on the real vulnerabilities of visually-aware recommender systems when confronted with adversarial images, this paper introduces a novel attack method, IPDGI (Item Promotion by Diffusion Generated Image). Specifically, IPDGI employs a guided diffusion model to generate adversarial samples designed to deceive visually-aware recommender systems. Taking advantage of accurately modeling benign images' distribution by diffusion models, the generated adversarial images have high fidelity with original images, ensuring the stealth of our IPDGI. To demonstrate the effectiveness of our proposed methods, we conduct extensive experiments on two commonly used e-commerce recommendation datasets (Amazon Beauty and Amazon Baby) with several typical visually-aware recommender systems. The experimental results show that our attack method has a significant improvement in both the performance of promoting the long-tailed (i.e., unpopular) items and the quality of generated adversarial images.
Segment Anything Model with Uncertainty Rectification for Auto-Prompting Medical Image Segmentation
Nov 17, 2023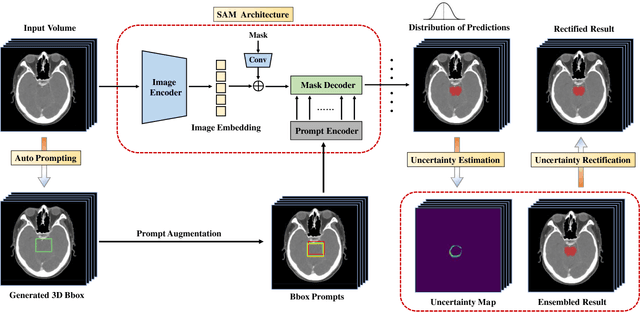
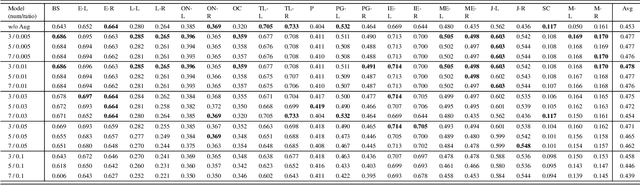
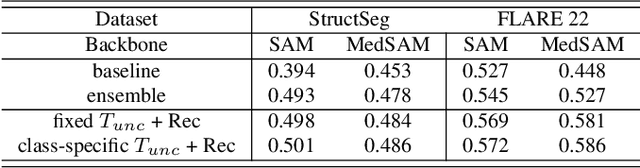
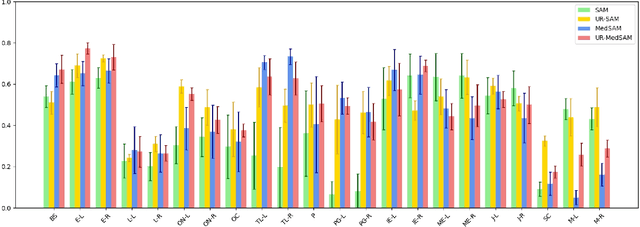
The introduction of the Segment Anything Model (SAM) has marked a significant advancement in prompt-driven image segmentation. However, SAM's application to medical image segmentation requires manual prompting of target structures to obtain acceptable performance, which is still labor-intensive. Despite attempts of auto-prompting to turn SAM into a fully automatic manner, it still exhibits subpar performance and lacks of reliability in the field of medical imaging. In this paper, we propose UR-SAM, an uncertainty rectified SAM framework to enhance the robustness and reliability for auto-prompting medical image segmentation. Our method incorporates a prompt augmentation module to estimate the distribution of predictions and generate uncertainty maps, and an uncertainty-based rectification module to further enhance the performance of SAM. Extensive experiments on two public 3D medical datasets covering the segmentation of 35 organs demonstrate that without supplementary training or fine-tuning, our method further improves the segmentation performance with up to 10.7 % and 13.8 % in dice similarity coefficient, demonstrating efficiency and broad capabilities for medical image segmentation without manual prompting.
Direct Exoplanet Detection Using Deep Convolutional Image Reconstruction (ConStruct): A New Algorithm for Post-Processing High-Contrast Images
Dec 06, 2023We present a novel machine-learning approach for detecting faint point sources in high-contrast adaptive optics imaging datasets. The most widely used algorithms for primary subtraction aim to decouple bright stellar speckle noise from planetary signatures by subtracting an approximation of the temporally evolving stellar noise from each frame in an imaging sequence. Our approach aims to improve the stellar noise approximation and increase the planet detection sensitivity by leveraging deep learning in a novel direct imaging post-processing algorithm. We show that a convolutional autoencoder neural network, trained on an extensive reference library of real imaging sequences, accurately reconstructs the stellar speckle noise at the location of a potential planet signal. This tool is used in a post-processing algorithm we call Direct Exoplanet Detection with Convolutional Image Reconstruction, or ConStruct. The reliability and sensitivity of ConStruct are assessed using real Keck/NIRC2 angular differential imaging datasets. Of the 30 unique point sources we examine, ConStruct yields a higher S/N than traditional PCA-based processing for 67$\%$ of the cases and improves the relative contrast by up to a factor of 2.6. This work demonstrates the value and potential of deep learning to take advantage of a diverse reference library of point spread function realizations to improve direct imaging post-processing. ConStruct and its future improvements may be particularly useful as tools for post-processing high-contrast images from the James Webb Space Telescope and extreme adaptive optics instruments, both for the current generation and those being designed for the upcoming 30 meter-class telescopes.
SinSR: Diffusion-Based Image Super-Resolution in a Single Step
Nov 23, 2023
While super-resolution (SR) methods based on diffusion models exhibit promising results, their practical application is hindered by the substantial number of required inference steps. Recent methods utilize degraded images in the initial state, thereby shortening the Markov chain. Nevertheless, these solutions either rely on a precise formulation of the degradation process or still necessitate a relatively lengthy generation path (e.g., 15 iterations). To enhance inference speed, we propose a simple yet effective method for achieving single-step SR generation, named SinSR. Specifically, we first derive a deterministic sampling process from the most recent state-of-the-art (SOTA) method for accelerating diffusion-based SR. This allows the mapping between the input random noise and the generated high-resolution image to be obtained in a reduced and acceptable number of inference steps during training. We show that this deterministic mapping can be distilled into a student model that performs SR within only one inference step. Additionally, we propose a novel consistency-preserving loss to simultaneously leverage the ground-truth image during the distillation process, ensuring that the performance of the student model is not solely bound by the feature manifold of the teacher model, resulting in further performance improvement. Extensive experiments conducted on synthetic and real-world datasets demonstrate that the proposed method can achieve comparable or even superior performance compared to both previous SOTA methods and the teacher model, in just one sampling step, resulting in a remarkable up to x10 speedup for inference. Our code will be released at https://github.com/wyf0912/SinSR
A self-attention-based differentially private tabular GAN with high data utility
Dec 20, 2023Generative Adversarial Networks (GANs) have become a ubiquitous technology for data generation, with their prowess in image generation being well-established. However, their application in generating tabular data has been less than ideal. Furthermore, attempting to incorporate differential privacy technology into these frameworks has often resulted in a degradation of data utility. To tackle these challenges, this paper introduces DP-SACTGAN, a novel Conditional Generative Adversarial Network (CGAN) framework for differentially private tabular data generation, aiming to surmount these obstacles. Experimental findings demonstrate that DP-SACTGAN not only accurately models the distribution of the original data but also effectively satisfies the requirements of differential privacy.
The Chosen One: Consistent Characters in Text-to-Image Diffusion Models
Nov 27, 2023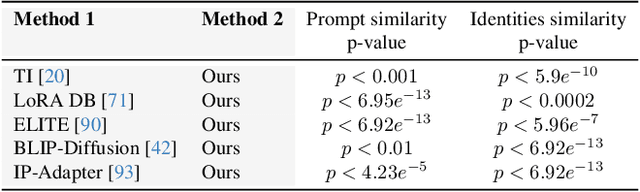


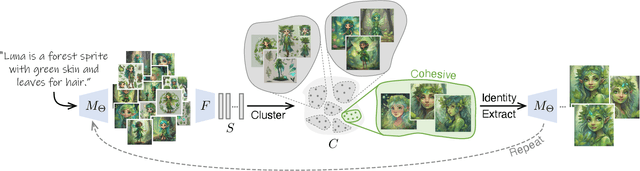
Recent advances in text-to-image generation models have unlocked vast potential for visual creativity. However, these models struggle with generation of consistent characters, a crucial aspect for numerous real-world applications such as story visualization, game development asset design, advertising, and more. Current methods typically rely on multiple pre-existing images of the target character or involve labor-intensive manual processes. In this work, we propose a fully automated solution for consistent character generation, with the sole input being a text prompt. We introduce an iterative procedure that, at each stage, identifies a coherent set of images sharing a similar identity and extracts a more consistent identity from this set. Our quantitative analysis demonstrates that our method strikes a better balance between prompt alignment and identity consistency compared to the baseline methods, and these findings are reinforced by a user study. To conclude, we showcase several practical applications of our approach. Project page is available at https://omriavrahami.com/the-chosen-one
Environment-Specific People
Dec 22, 2023Despite significant progress in generative image synthesis and full-body generation in particular, state-of-the-art methods are either context-independent, overly reliant to text prompts, or bound to the curated training datasets, such as fashion images with monotonous backgrounds. Here, our goal is to generate people in clothing that is semantically appropriate for a given scene. To this end, we present ESP, a novel method for context-aware full-body generation, that enables photo-realistic inpainting of people into existing "in-the-wild" photographs. ESP is conditioned on a 2D pose and contextual cues that are extracted from the environment photograph and integrated into the generation process. Our models are trained on a dataset containing a set of in-the-wild photographs of people covering a wide range of different environments. The method is analyzed quantitatively and qualitatively, and we show that ESP outperforms state-of-the-art on the task of contextual full-body generation.