 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Comprehensive Dataset and Automated Pipeline for Nailfold Capillary Analysis
Dec 10, 2023


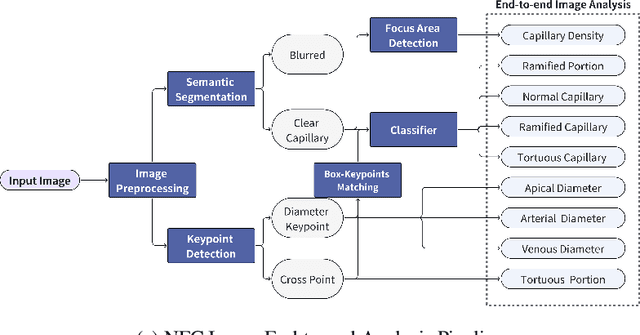
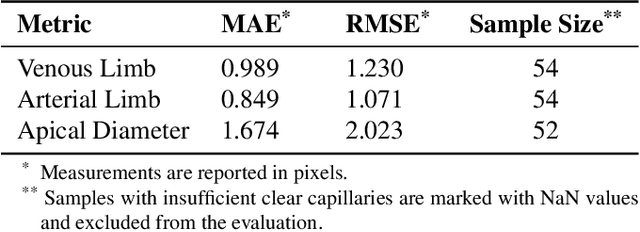
Nailfold capillaroscopy is a well-established method for assessing health conditions, but the untapped potential of automated medical image analysis using machine learning remains despite recent advancements. In this groundbreaking study, we present a pioneering effort in constructing a comprehensive dataset-321 images, 219 videos, 68 clinic reports, with expert annotations-that serves as a crucial resource for training deep-learning models. Leveraging this dataset, we propose an end-to-end nailfold capillary analysis pipeline capable of automatically detecting and measuring diverse morphological and dynamic features. Experimental results demonstrate sub-pixel measurement accuracy and 90% accuracy in predicting abnormality portions, highlighting its potential for advancing quantitative medical research and enabling pervasive computing in healthcare. We've shared our open-source codes and data (available at https://github.com/THU-CS-PI-LAB/ANFC-Automated-Nailfold-Capillary) to contribute to transformative progress in computational medical image analysis.
Perceptual impact of the loss function on deep-learning image coding performance
Nov 10, 2023Nowadays, deep-learning image coding solutions have shown similar or better compression efficiency than conventional solutions based on hand-crafted transforms and spatial prediction techniques. These deep-learning codecs require a large training set of images and a training methodology to obtain a suitable model (set of parameters) for efficient compression. The training is performed with an optimization algorithm which provides a way to minimize the loss function. Therefore, the loss function plays a key role in the overall performance and includes a differentiable quality metric that attempts to mimic human perception. The main objective of this paper is to study the perceptual impact of several image quality metrics that can be used in the loss function of the training process, through a crowdsourcing subjective image quality assessment study. From this study, it is possible to conclude that the choice of the quality metric is critical for the perceptual performance of the deep-learning codec and that can vary depending on the image content.
Sample-Efficient Learning to Solve a Real-World Labyrinth Game Using Data-Augmented Model-Based Reinforcement Learning
Dec 15, 2023Motivated by the challenge of achieving rapid learning in physical environments, this paper presents the development and training of a robotic system designed to navigate and solve a labyrinth game using model-based reinforcement learning techniques. The method involves extracting low-dimensional observations from camera images, along with a cropped and rectified image patch centered on the current position within the labyrinth, providing valuable information about the labyrinth layout. The learning of a control policy is performed purely on the physical system using model-based reinforcement learning, where the progress along the labyrinth's path serves as a reward signal. Additionally, we exploit the system's inherent symmetries to augment the training data. Consequently, our approach learns to successfully solve a popular real-world labyrinth game in record time, with only 5 hours of real-world training data.
Multimodal Machine Learning in Image-Based and Clinical Biomedicine: Survey and Prospects
Nov 20, 2023Machine learning (ML) applications in medical artificial intelligence (AI) systems have shifted from traditional and statistical methods to increasing application of deep learning models. This survey navigates the current landscape of multimodal ML, focusing on its profound impact on medical image analysis and clinical decision support systems. Emphasizing challenges and innovations in addressing multimodal representation, fusion, translation, alignment, and co-learning, the paper explores the transformative potential of multimodal models for clinical predictions. It also questions practical implementation of such models, bringing attention to the dynamics between decision support systems and healthcare providers. Despite advancements, challenges such as data biases and the scarcity of "big data" in many biomedical domains persist. We conclude with a discussion on effective innovation and collaborative efforts to further the miss
NoiseCLR: A Contrastive Learning Approach for Unsupervised Discovery of Interpretable Directions in Diffusion Models
Dec 08, 2023Generative models have been very popular in the recent years for their image generation capabilities. GAN-based models are highly regarded for their disentangled latent space, which is a key feature contributing to their success in controlled image editing. On the other hand, diffusion models have emerged as powerful tools for generating high-quality images. However, the latent space of diffusion models is not as thoroughly explored or understood. Existing methods that aim to explore the latent space of diffusion models usually relies on text prompts to pinpoint specific semantics. However, this approach may be restrictive in areas such as art, fashion, or specialized fields like medicine, where suitable text prompts might not be available or easy to conceive thus limiting the scope of existing work. In this paper, we propose an unsupervised method to discover latent semantics in text-to-image diffusion models without relying on text prompts. Our method takes a small set of unlabeled images from specific domains, such as faces or cats, and a pre-trained diffusion model, and discovers diverse semantics in unsupervised fashion using a contrastive learning objective. Moreover, the learned directions can be applied simultaneously, either within the same domain (such as various types of facial edits) or across different domains (such as applying cat and face edits within the same image) without interfering with each other. Our extensive experiments show that our method achieves highly disentangled edits, outperforming existing approaches in both diffusion-based and GAN-based latent space editing methods.
Stable Diffusion Exposed: Gender Bias from Prompt to Image
Dec 05, 2023Recent studies have highlighted biases in generative models, shedding light on their predisposition towards gender-based stereotypes and imbalances. This paper contributes to this growing body of research by introducing an evaluation protocol designed to automatically analyze the impact of gender indicators on Stable Diffusion images. Leveraging insights from prior work, we explore how gender indicators not only affect gender presentation but also the representation of objects and layouts within the generated images. Our findings include the existence of differences in the depiction of objects, such as instruments tailored for specific genders, and shifts in overall layouts. We also reveal that neutral prompts tend to produce images more aligned with masculine prompts than their feminine counterparts, providing valuable insights into the nuanced gender biases inherent in Stable Diffusion.
Satellite Captioning: Large Language Models to Augment Labeling
Dec 18, 2023With the growing capabilities of modern object detection networks and datasets to train them, it has gotten more straightforward and, importantly, less laborious to get up and running with a model that is quite adept at detecting any number of various objects. However, while image datasets for object detection have grown and continue to proliferate (the current most extensive public set, ImageNet, contains over 14m images with over 14m instances), the same cannot be said for textual caption datasets. While they have certainly been growing in recent years, caption datasets present a much more difficult challenge due to language differences, grammar, and the time it takes for humans to generate them. Current datasets have certainly provided many instances to work with, but it becomes problematic when a captioner may have a more limited vocabulary, one may not be adequately fluent in the language, or there are simple grammatical mistakes. These difficulties are increased when the images get more specific, such as remote sensing images. This paper aims to address this issue of potential information and communication shortcomings in caption datasets. To provide a more precise analysis, we specify our domain of images to be remote sensing images in the RSICD dataset and experiment with the captions provided here. Our findings indicate that ChatGPT grammar correction is a simple and effective way to increase the performance accuracy of caption models by making data captions more diverse and grammatically correct.
MedISure: Towards Assuring Machine Learning-based Medical Image Classifiers using Mixup Boundary Analysis
Nov 23, 2023Machine learning (ML) models are becoming integral in healthcare technologies, presenting a critical need for formal assurance to validate their safety, fairness, robustness, and trustworthiness. These models are inherently prone to errors, potentially posing serious risks to patient health and could even cause irreparable harm. Traditional software assurance techniques rely on fixed code and do not directly apply to ML models since these algorithms are adaptable and learn from curated datasets through a training process. However, adapting established principles, such as boundary testing using synthetic test data can effectively bridge this gap. To this end, we present a novel technique called Mix-Up Boundary Analysis (MUBA) that facilitates evaluating image classifiers in terms of prediction fairness. We evaluated MUBA for two important medical imaging tasks -- brain tumour classification and breast cancer classification -- and achieved promising results. This research aims to showcase the importance of adapting traditional assurance principles for assessing ML models to enhance the safety and reliability of healthcare technologies. To facilitate future research, we plan to publicly release our code for MUBA.
COVIDx CXR-4: An Expanded Multi-Institutional Open-Source Benchmark Dataset for Chest X-ray Image-Based Computer-Aided COVID-19 Diagnostics
Nov 29, 2023The global ramifications of the COVID-19 pandemic remain significant, exerting persistent pressure on nations even three years after its initial outbreak. Deep learning models have shown promise in improving COVID-19 diagnostics but require diverse and larger-scale datasets to improve performance. In this paper, we introduce COVIDx CXR-4, an expanded multi-institutional open-source benchmark dataset for chest X-ray image-based computer-aided COVID-19 diagnostics. COVIDx CXR-4 expands significantly on the previous COVIDx CXR-3 dataset by increasing the total patient cohort size by greater than 2.66 times, resulting in 84,818 images from 45,342 patients across multiple institutions. We provide extensive analysis on the diversity of the patient demographic, imaging metadata, and disease distributions to highlight potential dataset biases. To the best of the authors' knowledge, COVIDx CXR-4 is the largest and most diverse open-source COVID-19 CXR dataset and is made publicly available as part of an open initiative to advance research to aid clinicians against the COVID-19 disease.
Alpha-CLIP: A CLIP Model Focusing on Wherever You Want
Dec 06, 2023Contrastive Language-Image Pre-training (CLIP) plays an essential role in extracting valuable content information from images across diverse tasks. It aligns textual and visual modalities to comprehend the entire image, including all the details, even those irrelevant to specific tasks. However, for a finer understanding and controlled editing of images, it becomes crucial to focus on specific regions of interest, which can be indicated as points, masks, or boxes by humans or perception models. To fulfill the requirements, we introduce Alpha-CLIP, an enhanced version of CLIP with an auxiliary alpha channel to suggest attentive regions and fine-tuned with constructed millions of RGBA region-text pairs. Alpha-CLIP not only preserves the visual recognition ability of CLIP but also enables precise control over the emphasis of image contents. It demonstrates effectiveness in various tasks, including but not limited to open-world recognition, multimodal large language models, and conditional 2D / 3D generation. It has a strong potential to serve as a versatile tool for image-related tasks.