 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
HSViT: Horizontally Scalable Vision Transformer
Apr 08, 2024
While the Vision Transformer (ViT) architecture gains prominence in computer vision and attracts significant attention from multimedia communities, its deficiency in prior knowledge (inductive bias) regarding shift, scale, and rotational invariance necessitates pre-training on large-scale datasets. Furthermore, the growing layers and parameters in both ViT and convolutional neural networks (CNNs) impede their applicability to mobile multimedia services, primarily owing to the constrained computational resources on edge devices. To mitigate the aforementioned challenges, this paper introduces a novel horizontally scalable vision transformer (HSViT). Specifically, a novel image-level feature embedding allows ViT to better leverage the inductive bias inherent in the convolutional layers. Based on this, an innovative horizontally scalable architecture is designed, which reduces the number of layers and parameters of the models while facilitating collaborative training and inference of ViT models across multiple nodes. The experimental results depict that, without pre-training on large-scale datasets, HSViT achieves up to 10% higher top-1 accuracy than state-of-the-art schemes, ascertaining its superior preservation of inductive bias. The code is available at https://github.com/xuchenhao001/HSViT.
Pixel-wise RL on Diffusion Models: Reinforcement Learning from Rich Feedback
Apr 05, 2024Latent diffusion models are the state-of-the-art for synthetic image generation. To align these models with human preferences, training the models using reinforcement learning on human feedback is crucial. Black et. al 2024 introduced denoising diffusion policy optimisation (DDPO), which accounts for the iterative denoising nature of the generation by modelling it as a Markov chain with a final reward. As the reward is a single value that determines the model's performance on the entire image, the model has to navigate a very sparse reward landscape and so requires a large sample count. In this work, we extend the DDPO by presenting the Pixel-wise Policy Optimisation (PXPO) algorithm, which can take feedback for each pixel, providing a more nuanced reward to the model.
Distilling Semantic Priors from SAM to Efficient Image Restoration Models
Mar 25, 2024In image restoration (IR), leveraging semantic priors from segmentation models has been a common approach to improve performance. The recent segment anything model (SAM) has emerged as a powerful tool for extracting advanced semantic priors to enhance IR tasks. However, the computational cost of SAM is prohibitive for IR, compared to existing smaller IR models. The incorporation of SAM for extracting semantic priors considerably hampers the model inference efficiency. To address this issue, we propose a general framework to distill SAM's semantic knowledge to boost exiting IR models without interfering with their inference process. Specifically, our proposed framework consists of the semantic priors fusion (SPF) scheme and the semantic priors distillation (SPD) scheme. SPF fuses two kinds of information between the restored image predicted by the original IR model and the semantic mask predicted by SAM for the refined restored image. SPD leverages a self-distillation manner to distill the fused semantic priors to boost the performance of original IR models. Additionally, we design a semantic-guided relation (SGR) module for SPD, which ensures semantic feature representation space consistency to fully distill the priors. We demonstrate the effectiveness of our framework across multiple IR models and tasks, including deraining, deblurring, and denoising.
Prior Frequency Guided Diffusion Model for Limited Angle (LA)-CBCT Reconstruction
Apr 09, 2024Cone-beam computed tomography (CBCT) is widely used in image-guided radiotherapy. Reconstructing CBCTs from limited-angle acquisitions (LA-CBCT) is highly desired for improved imaging efficiency, dose reduction, and better mechanical clearance. LA-CBCT reconstruction, however, suffers from severe under-sampling artifacts, making it a highly ill-posed inverse problem. Diffusion models can generate data/images by reversing a data-noising process through learned data distributions; and can be incorporated as a denoiser/regularizer in LA-CBCT reconstruction. In this study, we developed a diffusion model-based framework, prior frequency-guided diffusion model (PFGDM), for robust and structure-preserving LA-CBCT reconstruction. PFGDM uses a conditioned diffusion model as a regularizer for LA-CBCT reconstruction, and the condition is based on high-frequency information extracted from patient-specific prior CT scans which provides a strong anatomical prior for LA-CBCT reconstruction. Specifically, we developed two variants of PFGDM (PFGDM-A and PFGDM-B) with different conditioning schemes. PFGDM-A applies the high-frequency CT information condition until a pre-optimized iteration step, and drops it afterwards to enable both similar and differing CT/CBCT anatomies to be reconstructed. PFGDM-B, on the other hand, continuously applies the prior CT information condition in every reconstruction step, while with a decaying mechanism, to gradually phase out the reconstruction guidance from the prior CT scans. The two variants of PFGDM were tested and compared with current available LA-CBCT reconstruction solutions, via metrics including PSNR and SSIM. PFGDM outperformed all traditional and diffusion model-based methods. PFGDM reconstructs high-quality LA-CBCTs under very-limited gantry angles, allowing faster and more flexible CBCT scans with dose reductions.
Theoretical Bound-Guided Hierarchical VAE for Neural Image Codecs
Mar 27, 2024Recent studies reveal a significant theoretical link between variational autoencoders (VAEs) and rate-distortion theory, notably in utilizing VAEs to estimate the theoretical upper bound of the information rate-distortion function of images. Such estimated theoretical bounds substantially exceed the performance of existing neural image codecs (NICs). To narrow this gap, we propose a theoretical bound-guided hierarchical VAE (BG-VAE) for NIC. The proposed BG-VAE leverages the theoretical bound to guide the NIC model towards enhanced performance. We implement the BG-VAE using Hierarchical VAEs and demonstrate its effectiveness through extensive experiments. Along with advanced neural network blocks, we provide a versatile, variable-rate NIC that outperforms existing methods when considering both rate-distortion performance and computational complexity. The code is available at BG-VAE.
D$^3$: Scaling Up Deepfake Detection by Learning from Discrepancy
Apr 06, 2024The boom of Generative AI brings opportunities entangled with risks and concerns. In this work, we seek a step toward a universal deepfake detection system with better generalization and robustness, to accommodate the responsible deployment of diverse image generative models. We do so by first scaling up the existing detection task setup from the one-generator to multiple-generators in training, during which we disclose two challenges presented in prior methodological designs. Specifically, we reveal that the current methods tailored for training on one specific generator either struggle to learn comprehensive artifacts from multiple generators or tend to sacrifice their ability to identify fake images from seen generators (i.e., In-Domain performance) to exchange the generalization for unseen generators (i.e., Out-Of-Domain performance). To tackle the above challenges, we propose our Discrepancy Deepfake Detector (D$^3$) framework, whose core idea is to learn the universal artifacts from multiple generators by introducing a parallel network branch that takes a distorted image as extra discrepancy signal to supplement its original counterpart. Extensive scaled-up experiments on the merged UFD and GenImage datasets with six detection models demonstrate the effectiveness of our framework, achieving a 5.3% accuracy improvement in the OOD testing compared to the current SOTA methods while maintaining the ID performance.
CLIPping the Limits: Finding the Sweet Spot for Relevant Images in Automated Driving Systems Perception Testing
Apr 08, 2024Perception systems, especially cameras, are the eyes of automated driving systems. Ensuring that they function reliably and robustly is therefore an important building block in the automation of vehicles. There are various approaches to test the perception of automated driving systems. Ultimately, however, it always comes down to the investigation of the behavior of perception systems under specific input data. Camera images are a crucial part of the input data. Image data sets are therefore collected for the testing of automated driving systems, but it is non-trivial to find specific images in these data sets. Thanks to recent developments in neural networks, there are now methods for sorting the images in a data set according to their similarity to a prompt in natural language. In order to further automate the provision of search results, we make a contribution by automating the threshold definition in these sorted results and returning only the images relevant to the prompt as a result. Our focus is on preventing false positives and false negatives equally. It is also important that our method is robust and in the case that our assumptions are not fulfilled, we provide a fallback solution.
UniFL: Improve Stable Diffusion via Unified Feedback Learning
Apr 08, 2024Diffusion models have revolutionized the field of image generation, leading to the proliferation of high-quality models and diverse downstream applications. However, despite these significant advancements, the current competitive solutions still suffer from several limitations, including inferior visual quality, a lack of aesthetic appeal, and inefficient inference, without a comprehensive solution in sight. To address these challenges, we present UniFL, a unified framework that leverages feedback learning to enhance diffusion models comprehensively. UniFL stands out as a universal, effective, and generalizable solution applicable to various diffusion models, such as SD1.5 and SDXL. Notably, UniFL incorporates three key components: perceptual feedback learning, which enhances visual quality; decoupled feedback learning, which improves aesthetic appeal; and adversarial feedback learning, which optimizes inference speed. In-depth experiments and extensive user studies validate the superior performance of our proposed method in enhancing both the quality of generated models and their acceleration. For instance, UniFL surpasses ImageReward by 17% user preference in terms of generation quality and outperforms LCM and SDXL Turbo by 57% and 20% in 4-step inference. Moreover, we have verified the efficacy of our approach in downstream tasks, including Lora, ControlNet, and AnimateDiff.
Enhancing Historical Image Retrieval with Compositional Cues
Mar 21, 2024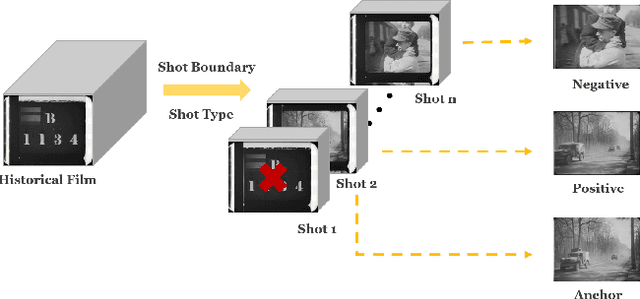

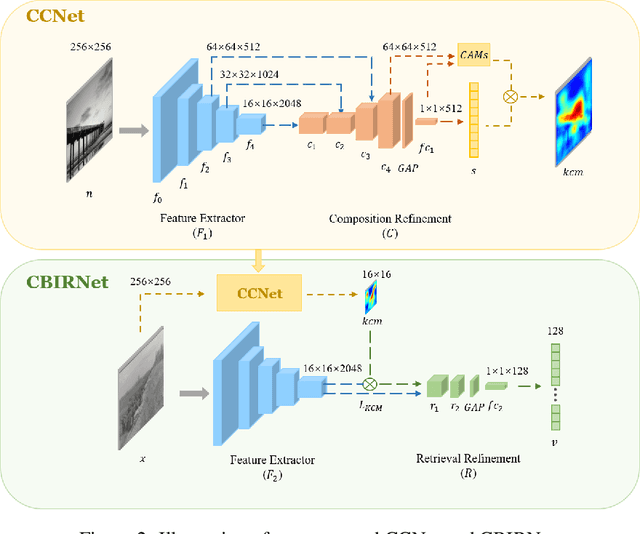
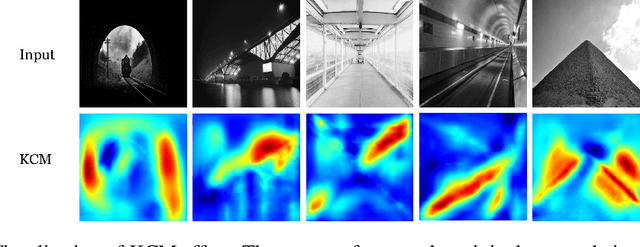
In analyzing vast amounts of digitally stored historical image data, existing content-based retrieval methods often overlook significant non-semantic information, limiting their effectiveness for flexible exploration across varied themes. To broaden the applicability of image retrieval methods for diverse purposes and uncover more general patterns, we innovatively introduce a crucial factor from computational aesthetics, namely image composition, into this topic. By explicitly integrating composition-related information extracted by CNN into the designed retrieval model, our method considers both the image's composition rules and semantic information. Qualitative and quantitative experiments demonstrate that the image retrieval network guided by composition information outperforms those relying solely on content information, facilitating the identification of images in databases closer to the target image in human perception. Please visit https://github.com/linty5/CCBIR to try our codes.
CasSR: Activating Image Power for Real-World Image Super-Resolution
Mar 18, 2024
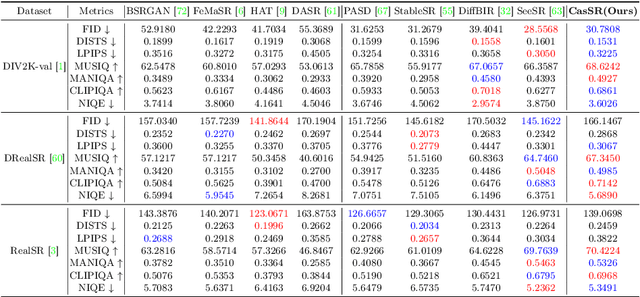


The objective of image super-resolution is to generate clean and high-resolution images from degraded versions. Recent advancements in diffusion modeling have led to the emergence of various image super-resolution techniques that leverage pretrained text-to-image (T2I) models. Nevertheless, due to the prevalent severe degradation in low-resolution images and the inherent characteristics of diffusion models, achieving high-fidelity image restoration remains challenging. Existing methods often exhibit issues including semantic loss, artifacts, and the introduction of spurious content not present in the original image. To tackle this challenge, we propose Cascaded diffusion for Super-Resolution, CasSR , a novel method designed to produce highly detailed and realistic images. In particular, we develop a cascaded controllable diffusion model that aims to optimize the extraction of information from low-resolution images. This model generates a preliminary reference image to facilitate initial information extraction and degradation mitigation. Furthermore, we propose a multi-attention mechanism to enhance the T2I model's capability in maximizing the restoration of the original image content. Through a comprehensive blend of qualitative and quantitative analyses, we substantiate the efficacy and superiority of our approach.