 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
NutritionVerse-Synth: An Open Access Synthetically Generated 2D Food Scene Dataset for Dietary Intake Estimation
Dec 11, 2023
Manually tracking nutritional intake via food diaries is error-prone and burdensome. Automated computer vision techniques show promise for dietary monitoring but require large and diverse food image datasets. To address this need, we introduce NutritionVerse-Synth (NV-Synth), a large-scale synthetic food image dataset. NV-Synth contains 84,984 photorealistic meal images rendered from 7,082 dynamically plated 3D scenes. Each scene is captured from 12 viewpoints and includes perfect ground truth annotations such as RGB, depth, semantic, instance, and amodal segmentation masks, bounding boxes, and detailed nutritional information per food item. We demonstrate the diversity of NV-Synth across foods, compositions, viewpoints, and lighting. As the largest open-source synthetic food dataset, NV-Synth highlights the value of physics-based simulations for enabling scalable and controllable generation of diverse photorealistic meal images to overcome data limitations and drive advancements in automated dietary assessment using computer vision. In addition to the dataset, the source code for our data generation framework is also made publicly available at https://saeejithnair.github.io/nvsynth.
QuickQuakeBuildings: Post-earthquake SAR-Optical Dataset for Quick Damaged-building Detection
Dec 11, 2023

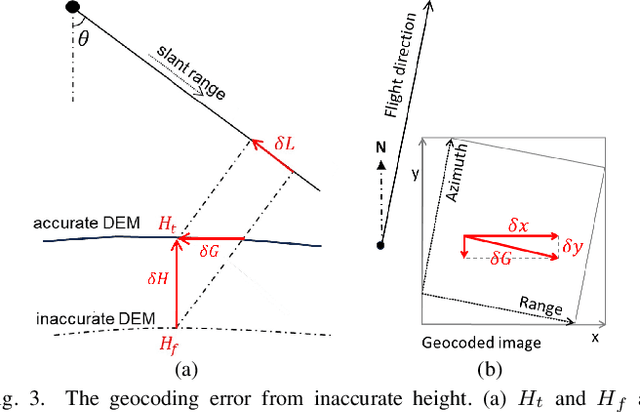
Quick and automated earthquake-damaged building detection from post-event satellite imagery is crucial, yet it is challenging due to the scarcity of training data required to develop robust algorithms. This letter presents the first dataset dedicated to detecting earthquake-damaged buildings from post-event very high resolution (VHR) Synthetic Aperture Radar (SAR) and optical imagery. Utilizing open satellite imagery and annotations acquired after the 2023 Turkey-Syria earthquakes, we deliver a dataset of coregistered building footprints and satellite image patches of both SAR and optical data, encompassing more than four thousand buildings. The task of damaged building detection is formulated as a binary image classification problem, that can also be treated as an anomaly detection problem due to extreme class imbalance. We provide baseline methods and results to serve as references for comparison. Researchers can utilize this dataset to expedite algorithm development, facilitating the rapid detection of damaged buildings in response to future events. The dataset and codes together with detailed explanations are made publicly available at \url{https://github.com/ya0-sun/PostEQ-SARopt-BuildingDamage}.
XC-NAS: A New Cellular Encoding Approach for Neural Architecture Search of Multi-path Convolutional Neural Networks
Dec 12, 2023Convolutional Neural Networks (CNNs) continue to achieve great success in classification tasks as innovative techniques and complex multi-path architecture topologies are introduced. Neural Architecture Search (NAS) aims to automate the design of these complex architectures, reducing the need for costly manual design work by human experts. Cellular Encoding (CE) is an evolutionary computation technique which excels in constructing novel multi-path topologies of varying complexity and has recently been applied with NAS to evolve CNN architectures for various classification tasks. However, existing CE approaches have severe limitations. They are restricted to only one domain, only partially implement the theme of CE, or only focus on the micro-architecture search space. This paper introduces a new CE representation and algorithm capable of evolving novel multi-path CNN architectures of varying depth, width, and complexity for image and text classification tasks. The algorithm explicitly focuses on the macro-architecture search space. Furthermore, by using a surrogate model approach, we show that the algorithm can evolve a performant CNN architecture in less than one GPU day, thereby allowing a sufficient number of experiment runs to be conducted to achieve scientific robustness. Experiment results show that the approach is highly competitive, defeating several state-of-the-art methods, and is generalisable to both the image and text domains.
CAManim: Animating end-to-end network activation maps
Dec 19, 2023Deep neural networks have been widely adopted in numerous domains due to their high performance and accessibility to developers and application-specific end-users. Fundamental to image-based applications is the development of Convolutional Neural Networks (CNNs), which possess the ability to automatically extract features from data. However, comprehending these complex models and their learned representations, which typically comprise millions of parameters and numerous layers, remains a challenge for both developers and end-users. This challenge arises due to the absence of interpretable and transparent tools to make sense of black-box models. There exists a growing body of Explainable Artificial Intelligence (XAI) literature, including a collection of methods denoted Class Activation Maps (CAMs), that seek to demystify what representations the model learns from the data, how it informs a given prediction, and why it, at times, performs poorly in certain tasks. We propose a novel XAI visualization method denoted CAManim that seeks to simultaneously broaden and focus end-user understanding of CNN predictions by animating the CAM-based network activation maps through all layers, effectively depicting from end-to-end how a model progressively arrives at the final layer activation. Herein, we demonstrate that CAManim works with any CAM-based method and various CNN architectures. Beyond qualitative model assessments, we additionally propose a novel quantitative assessment that expands upon the Remove and Debias (ROAD) metric, pairing the qualitative end-to-end network visual explanations assessment with our novel quantitative "yellow brick ROAD" assessment (ybROAD). This builds upon prior research to address the increasing demand for interpretable, robust, and transparent model assessment methodology, ultimately improving an end-user's trust in a given model's predictions.
GeNIe: Generative Hard Negative Images Through Diffusion
Dec 05, 2023Data augmentation is crucial in training deep models, preventing them from overfitting to limited data. Common data augmentation methods are effective, but recent advancements in generative AI, such as diffusion models for image generation, enable more sophisticated augmentation techniques that produce data resembling natural images. We recognize that augmented samples closer to the ideal decision boundary of a classifier are particularly effective and efficient in guiding the learning process. We introduce GeNIe which leverages a diffusion model conditioned on a text prompt to merge contrasting data points (an image from the source category and a text prompt from the target category) to generate challenging samples for the target category. Inspired by recent image editing methods, we limit the number of diffusion iterations and the amount of noise. This ensures that the generated image retains low-level and contextual features from the source image, potentially conflicting with the target category. Our extensive experiments, in few-shot and also long-tail distribution settings, demonstrate the effectiveness of our novel augmentation method, especially benefiting categories with a limited number of examples.
An adversarial attack approach for eXplainable AI evaluation on deepfake detection models
Dec 08, 2023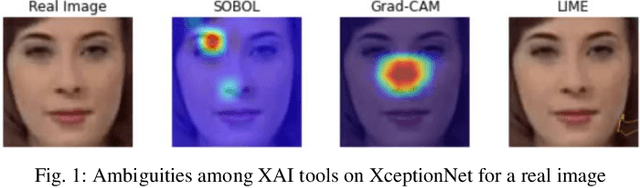


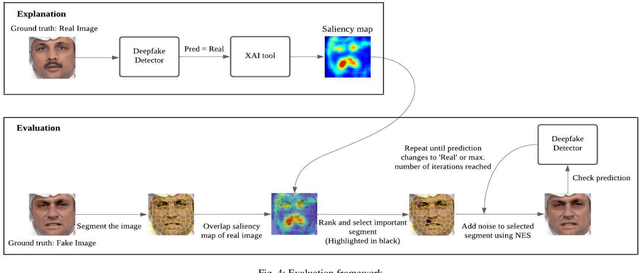
With the rising concern on model interpretability, the application of eXplainable AI (XAI) tools on deepfake detection models has been a topic of interest recently. In image classification tasks, XAI tools highlight pixels influencing the decision given by a model. This helps in troubleshooting the model and determining areas that may require further tuning of parameters. With a wide range of tools available in the market, choosing the right tool for a model becomes necessary as each one may highlight different sets of pixels for a given image. There is a need to evaluate different tools and decide the best performing ones among them. Generic XAI evaluation methods like insertion or removal of salient pixels/segments are applicable for general image classification tasks but may produce less meaningful results when applied on deepfake detection models due to their functionality. In this paper, we perform experiments to show that generic removal/insertion XAI evaluation methods are not suitable for deepfake detection models. We also propose and implement an XAI evaluation approach specifically suited for deepfake detection models.
GPT4SGG: Synthesizing Scene Graphs from Holistic and Region-specific Narratives
Dec 07, 2023Learning scene graphs from natural language descriptions has proven to be a cheap and promising scheme for Scene Graph Generation (SGG). However, such unstructured caption data and its processing are troubling the learning an acurrate and complete scene graph. This dilema can be summarized as three points. First, traditional language parsers often fail to extract meaningful relationship triplets from caption data. Second, grounding unlocalized objects in parsed triplets will meet ambiguity in visual-language alignment. Last, caption data typically are sparse and exhibit bias to partial observations of image content. These three issues make it hard for the model to generate comprehensive and accurate scene graphs. To fill this gap, we propose a simple yet effective framework, GPT4SGG, to synthesize scene graphs from holistic and region-specific narratives. The framework discards traditional language parser, and localize objects before obtaining relationship triplets. To obtain relationship triplets, holistic and dense region-specific narratives are generated from the image. With such textual representation of image data and a task-specific prompt, an LLM, particularly GPT-4, directly synthesizes a scene graph as "pseudo labels". Experimental results showcase GPT4SGG significantly improves the performance of SGG models trained on image-caption data. We believe this pioneering work can motivate further research into mining the visual reasoning capabilities of LLMs.
Foundation Model Assisted Weakly Supervised Semantic Segmentation
Dec 06, 2023This work aims to leverage pre-trained foundation models, such as contrastive language-image pre-training (CLIP) and segment anything model (SAM), to address weakly supervised semantic segmentation (WSSS) using image-level labels. To this end, we propose a coarse-to-fine framework based on CLIP and SAM for generating high-quality segmentation seeds. Specifically, we construct an image classification task and a seed segmentation task, which are jointly performed by CLIP with frozen weights and two sets of learnable task-specific prompts. A SAM-based seeding (SAMS) module is designed and applied to each task to produce either coarse or fine seed maps. Moreover, we design a multi-label contrastive loss supervised by image-level labels and a CAM activation loss supervised by the generated coarse seed map. These losses are used to learn the prompts, which are the only parts need to be learned in our framework. Once the prompts are learned, we input each image along with the learned segmentation-specific prompts into CLIP and the SAMS module to produce high-quality segmentation seeds. These seeds serve as pseudo labels to train an off-the-shelf segmentation network like other two-stage WSSS methods. Experiments show that our method achieves the state-of-the-art performance on PASCAL VOC 2012 and competitive results on MS COCO 2014.
Cache Me if You Can: Accelerating Diffusion Models through Block Caching
Dec 06, 2023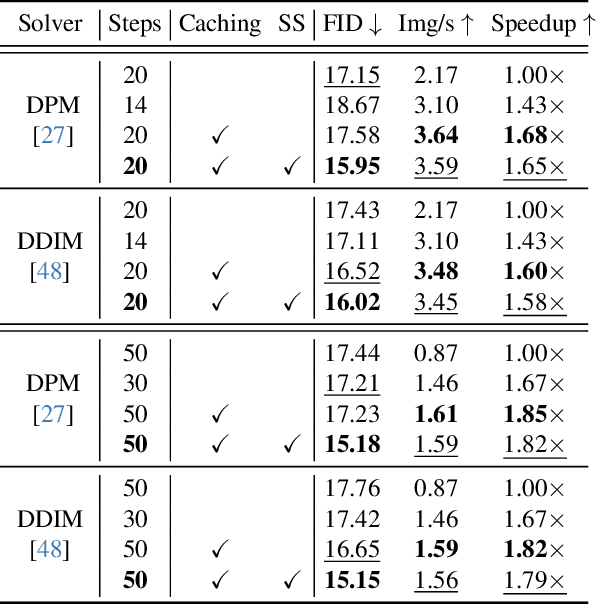

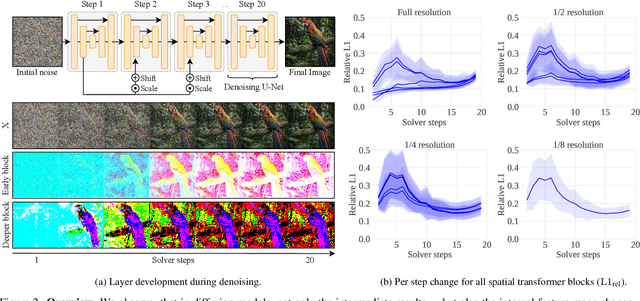
Diffusion models have recently revolutionized the field of image synthesis due to their ability to generate photorealistic images. However, one of the major drawbacks of diffusion models is that the image generation process is costly. A large image-to-image network has to be applied many times to iteratively refine an image from random noise. While many recent works propose techniques to reduce the number of required steps, they generally treat the underlying denoising network as a black box. In this work, we investigate the behavior of the layers within the network and find that 1) the layers' output changes smoothly over time, 2) the layers show distinct patterns of change, and 3) the change from step to step is often very small. We hypothesize that many layer computations in the denoising network are redundant. Leveraging this, we introduce block caching, in which we reuse outputs from layer blocks of previous steps to speed up inference. Furthermore, we propose a technique to automatically determine caching schedules based on each block's changes over timesteps. In our experiments, we show through FID, human evaluation and qualitative analysis that Block Caching allows to generate images with higher visual quality at the same computational cost. We demonstrate this for different state-of-the-art models (LDM and EMU) and solvers (DDIM and DPM).
ArchiGuesser -- AI Art Architecture Educational Game
Dec 14, 2023The use of generative AI in education is a controversial topic. Current technology offers the potential to create educational content from text, speech, to images based on simple input prompts. This can enhance productivity by summarizing knowledge and improving communication, quickly adjusting to different types of learners. Moreover, generative AI holds the promise of making the learning itself more fun, by responding to user inputs and dynamically generating high-quality creative material. In this paper we present the multisensory educational game ArchiGuesser that combines various AI technologies from large language models, image generation, to computer vision to serve a single purpose: Teaching students in a playful way the diversity of our architectural history and how generative AI works.