 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Radiomic Feature Stability Analysis based on Probabilistic Segmentations
Oct 13, 2019
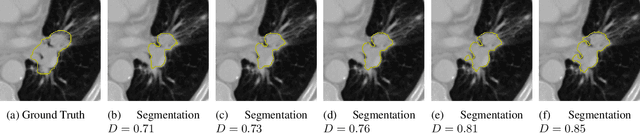
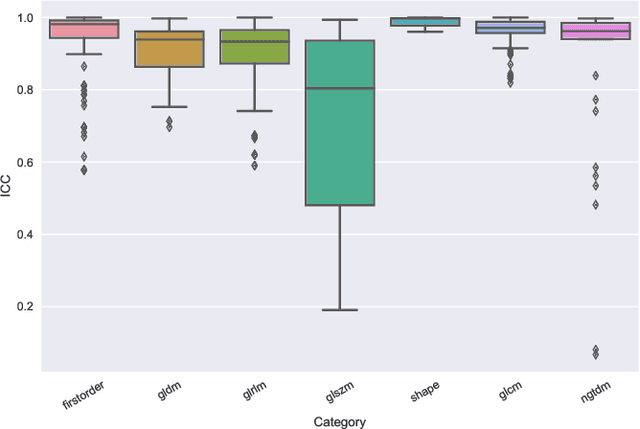
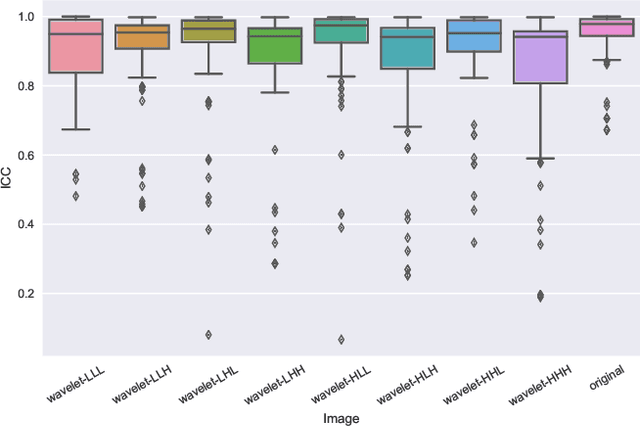
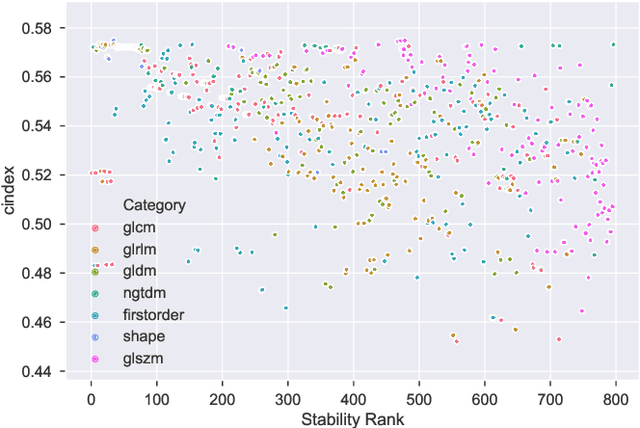
Identifying image features that are robust with respect to segmentation variability and domain shift is a tough challenge in radiomics. So far, this problem has mainly been tackled in test-retest analyses. In this work we analyze radiomics feature stability based on probabilistic automated segmentation hypotheses. Based on a public lung cancer dataset, we generate an arbitrary number of plausible segmentations using a Probabilistic U-Net. From these segmentations, we extract a high number of plausible feature vectors for each lung tumor and analyze feature variance with respect to the segmentations. Our results suggest that there are groups of radiomic features that are more (e.g. statistics features) and less (e.g. gray-level size zone matrix features) robust against segmentation variability. Finally, we demonstrate that segmentation variance impacts the performance of a prognostic lung cancer survival model and propose a new and potentially more robust radiomics feature selection workflow.
Quantile Representation for Indirect Immunofluorescence Image Classification
Feb 06, 2014
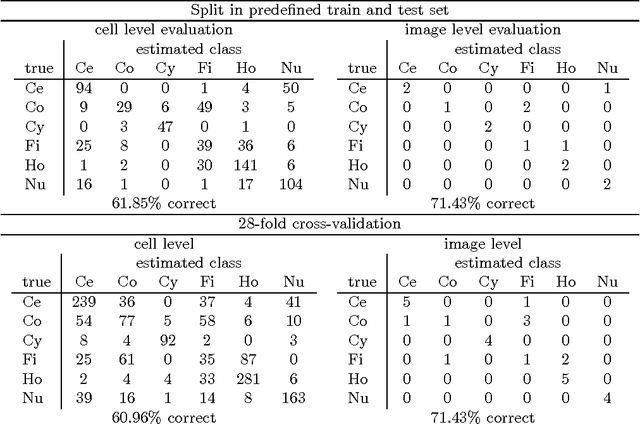
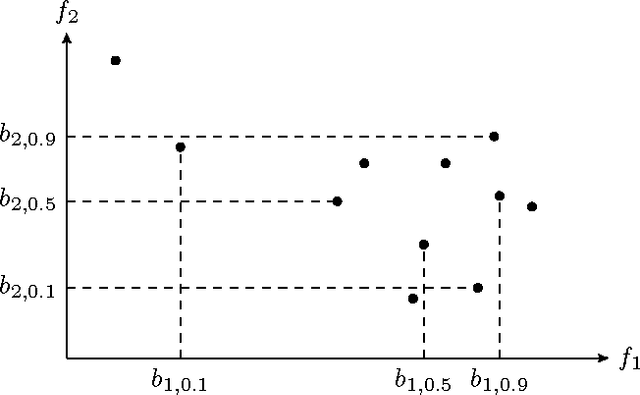
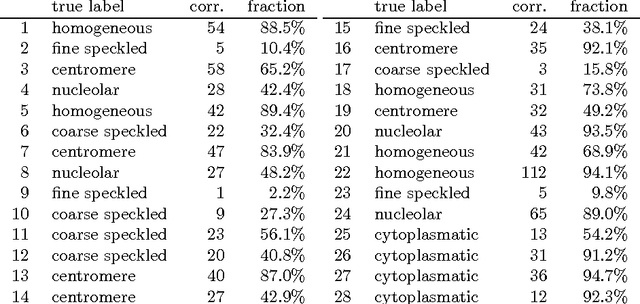
In the diagnosis of autoimmune diseases, an important task is to classify images of slides containing several HEp-2 cells. All cells from one slide share the same label, and by classifying cells from one slide independently, some information on the global image quality and intensity is lost. Considering one whole slide as a collection (a bag) of feature vectors, however, poses the problem of how to handle this bag. A simple, and surprisingly effective, approach is to summarize the bag of feature vectors by a few quantile values per feature. This characterizes the full distribution of all instances, thereby assuming that all instances in a bag are informative. This representation is particularly useful when each bag contains many feature vectors, which is the case in the classification of the immunofluorescence images. Experiments on the classification of indirect immunofluorescence images show the usefulness of this approach.
A Useful Taxonomy for Adversarial Robustness of Neural Networks
Oct 23, 2019Adversarial attacks and defenses are currently active areas of research for the deep learning community. A recent review paper divided the defense approaches into three categories; gradient masking, robust optimization, and adversarial example detection. We divide gradient masking and robust optimization differently: (1) increasing intra-class compactness and inter-class separation of the feature vectors improves adversarial robustness, and (2) marginalization or removal of non-robust image features also improves adversarial robustness. By reframing these topics differently, we provide a fresh perspective that provides insight into the underlying factors that enable training more robust networks and can help inspire novel solutions. In addition, there are several papers in the literature of adversarial defenses that claim there is a cost for adversarial robustness, or a trade-off between robustness and accuracy but, under this proposed taxonomy, we hypothesis that this is not universal. We follow up on our taxonomy with several challenges to the deep learning research community that builds on the connections and insights in this paper.
Highlighting Bias with Explainable Neural-Symbolic Visual Reasoning
Sep 19, 2019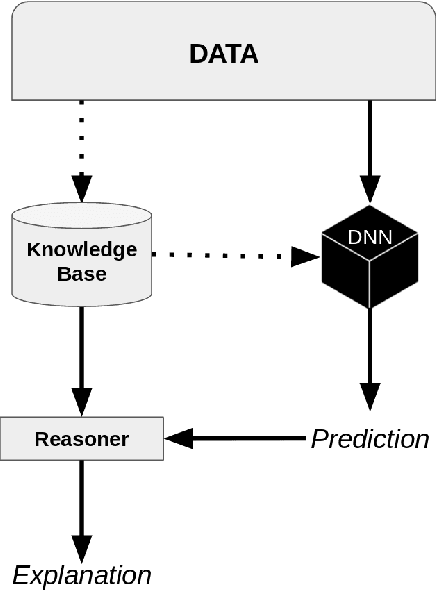

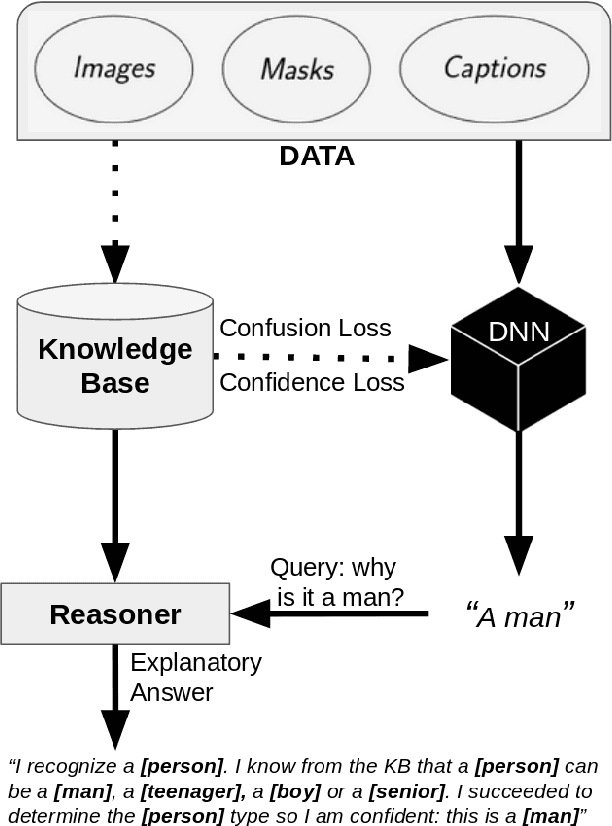
Many high-performance models suffer from a lack of interpretability. There has been an increasing influx of work on explainable artificial intelligence (XAI) in order to disentangle what is meant and expected by XAI. Nevertheless, there is no general consensus on how to produce and judge explanations. In this paper, we discuss why techniques integrating connectionist and symbolic paradigms are the most efficient solutions to produce explanations for non-technical users and we propose a reasoning model, based on definitions by Doran et al. [2017] (arXiv:1710.00794) to explain a neural network's decision. We use this explanation in order to correct bias in the network's decision rationale. We accompany this model with an example of its potential use, based on the image captioning method in Burns et al. [2018] (arXiv:1803.09797).
Filter Early, Match Late: Improving Network-Based Visual Place Recognition
Jun 21, 2019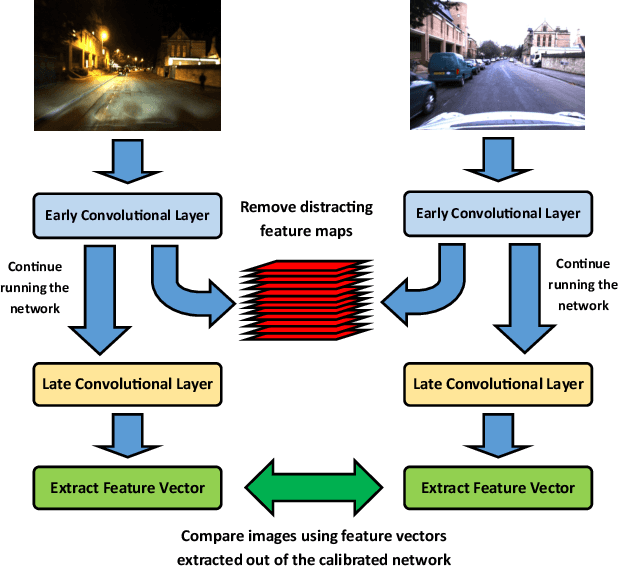
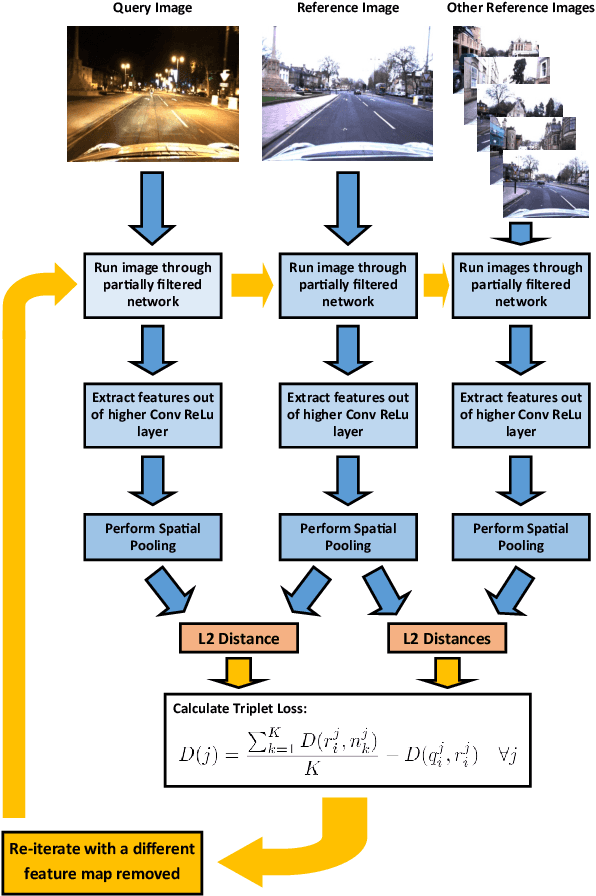
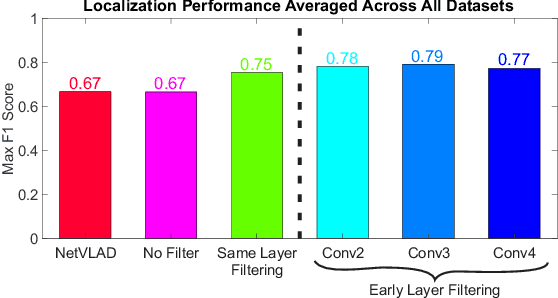

CNNs have excelled at performing place recognition over time, particularly when the neural network is optimized for localization in the current environmental conditions. In this paper we investigate the concept of feature map filtering, where, rather than using all the activations within a convolutional tensor, only the most useful activations are used. Since specific feature maps encode different visual features, the objective is to remove feature maps that are detract from the ability to recognize a location across appearance changes. Our key innovation is to filter the feature maps in an early convolutional layer, but then continue to run the network and extract a feature vector using a later layer in the same network. By filtering early visual features and extracting a feature vector from a higher, more viewpoint invariant later layer, we demonstrate improved condition and viewpoint invariance. Our approach requires image pairs for training from the deployment environment, but we show that state-of-the-art performance can regularly be achieved with as little as a single training image pair. An exhaustive experimental analysis is performed to determine the full scope of causality between early layer filtering and late layer extraction. For validity, we use three datasets: Oxford RobotCar, Nordland, and Gardens Point, achieving overall superior performance to NetVLAD. The work provides a number of new avenues for exploring CNN optimizations, without full re-training.
Repeatability of Multiparametric Prostate MRI Radiomics Features
Jul 16, 2018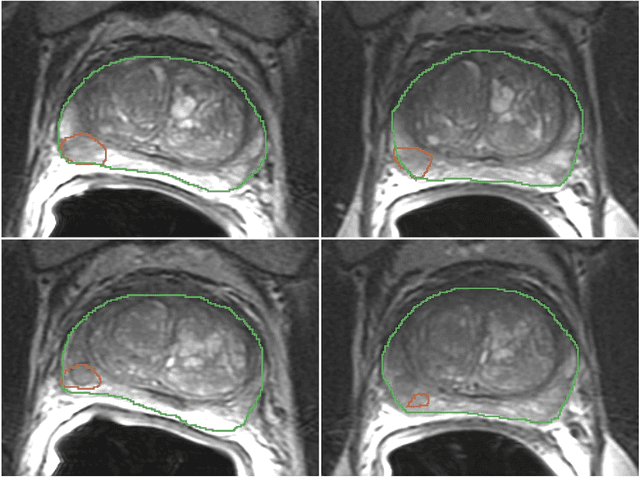
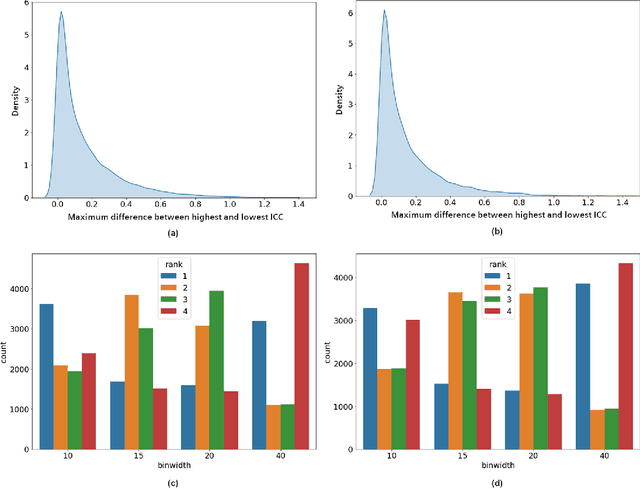
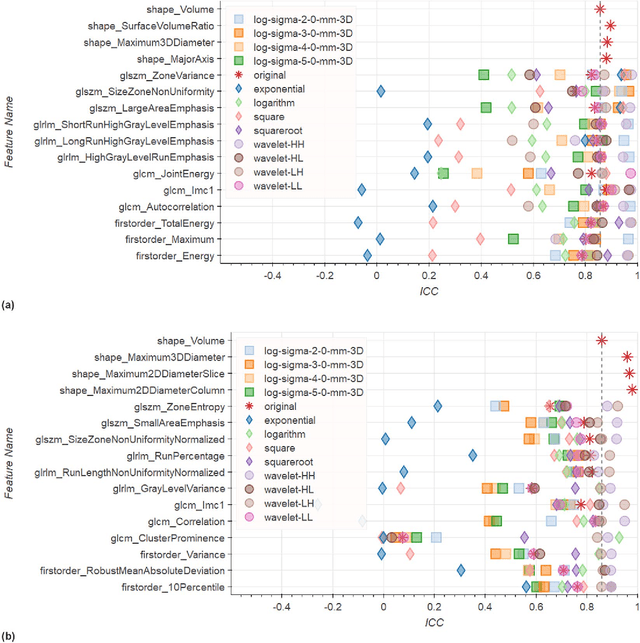
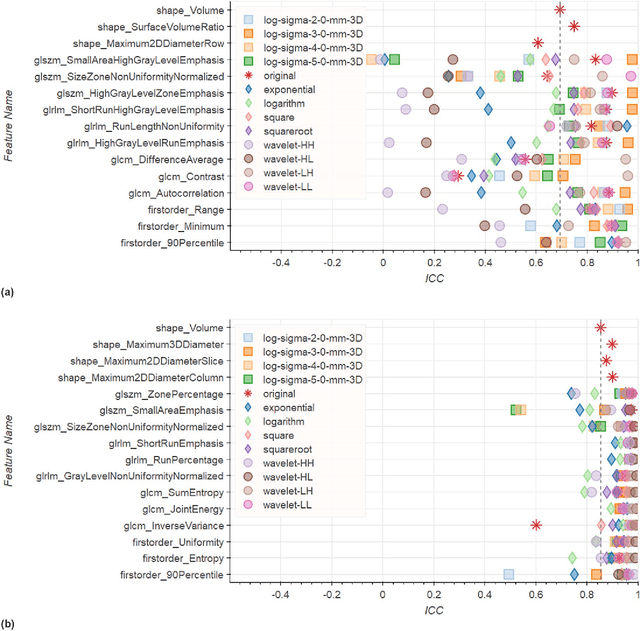
In this study we assessed the repeatability of the values of radiomics features for small prostate tumors using test-retest? Multiparametric Magnetic Resonance Imaging (mpMRI) images. The premise of radiomics is that quantitative image features can serve as biomarkers characterizing disease. For such biomarkers to be useful, repeatability is a basic requirement, meaning its value must remain stable between two scans, if the conditions remain stable. We investigated repeatability of radiomics features under various preprocessing and extraction configurations including various image normalization schemes, different image pre-filtering, 2D vs 3D texture computation, and different bin widths for image discretization. Image registration as means to re-identify regions of interest across time points was evaluated against human-expert segmented regions in both time points. Even though we found many radiomics features and preprocessing combinations with a high repeatability (Intraclass Correlation Coefficient (ICC) > 0.85), our results indicate that overall the repeatability is highly sensitive to the processing parameters (under certain configurations, it can be below 0.0). Image normalization, using a variety of approaches considered, did not result in consistent improvements in repeatability. There was also no consistent improvement of repeatability through the use of pre-filtering options, or by using image registration between timepoints to improve consistency of the region of interest localization. Based on these results we urge caution when interpreting radiomics features and advise paying close attention to the processing configuration details of reported results. Furthermore, we advocate reporting all processing details in radiomics studies and strongly recommend making the implementation available.
Learning Priors in High-frequency Domain for Inverse Imaging Reconstruction
Oct 23, 2019
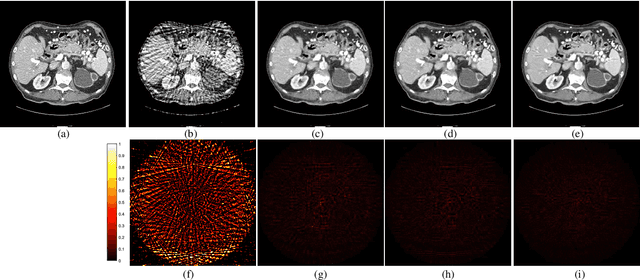
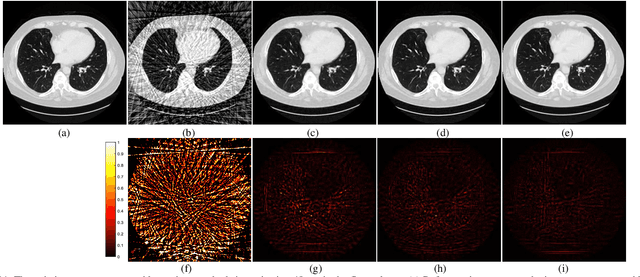
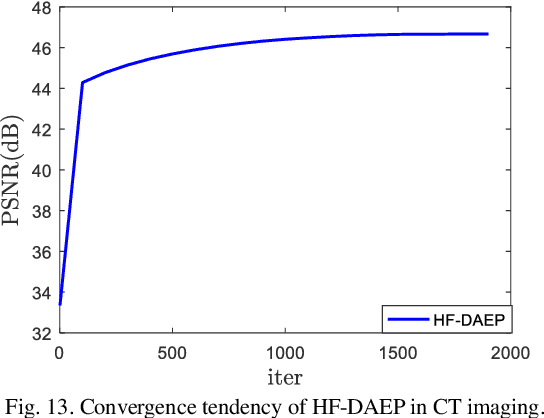
Ill-posed inverse problems in imaging remain an active research topic in several decades, with new approaches constantly emerging. Recognizing that the popular dictionary learning and convolutional sparse coding are both essentially modeling the high-frequency component of an image, which convey most of the semantic information such as texture details, in this work we propose a novel multi-profile high-frequency transform-guided denoising autoencoder as prior (HF-DAEP). To achieve this goal, we first extract a set of multi-profile high-frequency components via a specific transformation and add the artificial Gaussian noise to these high-frequency components as training samples. Then, as the high-frequency prior information is learned, we incorporate it into classical iterative reconstruction process by proximal gradient descent technique. Preliminary results on highly under-sampled magnetic resonance imaging and sparse-view computed tomography reconstruction demonstrate that the proposed method can efficiently reconstruct feature details and present advantages over state-of-the-arts.
Non-flat Ground Detection Based on A Local Descriptor
Jun 06, 2018

The detection of road and free space remains challenging for non-flat plane, especially with the varying latitudinal and longitudinal slope or in the case of multi-ground plane. In this paper, we propose a framework of the ground plane detection with stereo vision. The main contribution of this paper is a newly proposed descriptor which is implemented in the disparity image to obtain a disparity texture image. The ground plane regions can be distinguished from their surroundings effectively in the disparity texture image. Because the descriptor is implemented in the local area of the image, it can address well the problem of non-flat plane. And we also present a complete framework to detect the ground plane regions base on the disparity texture image with convolutional neural network architecture.
Deep convolutional Gaussian processes
Oct 06, 2018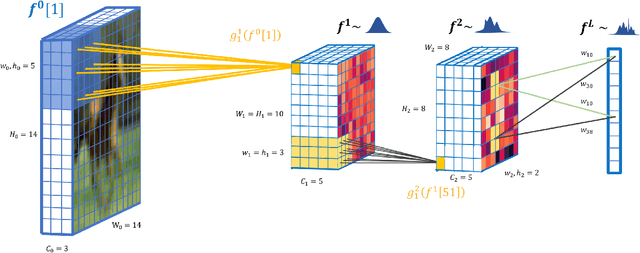
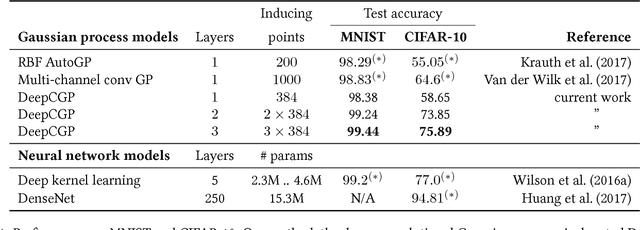
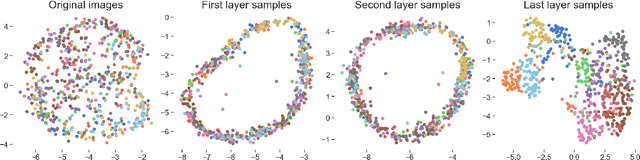
We propose deep convolutional Gaussian processes, a deep Gaussian process architecture with convolutional structure. The model is a principled Bayesian framework for detecting hierarchical combinations of local features for image classification. We demonstrate greatly improved image classification performance compared to current Gaussian process approaches on the MNIST and CIFAR-10 datasets. In particular, we improve CIFAR-10 accuracy by over 10 percentage points.
Visualizing Topographic Independent Component Analysis with Movies
Jan 24, 2019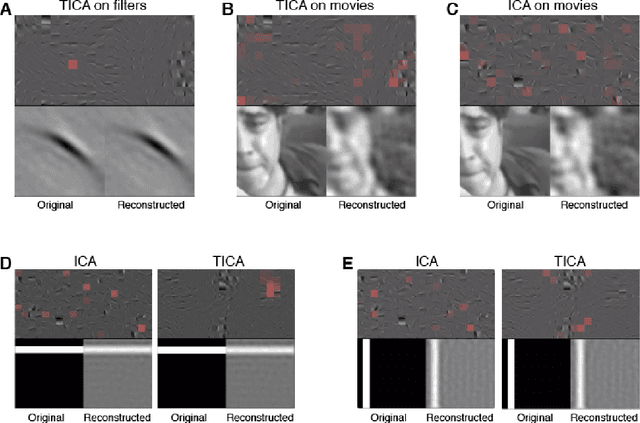
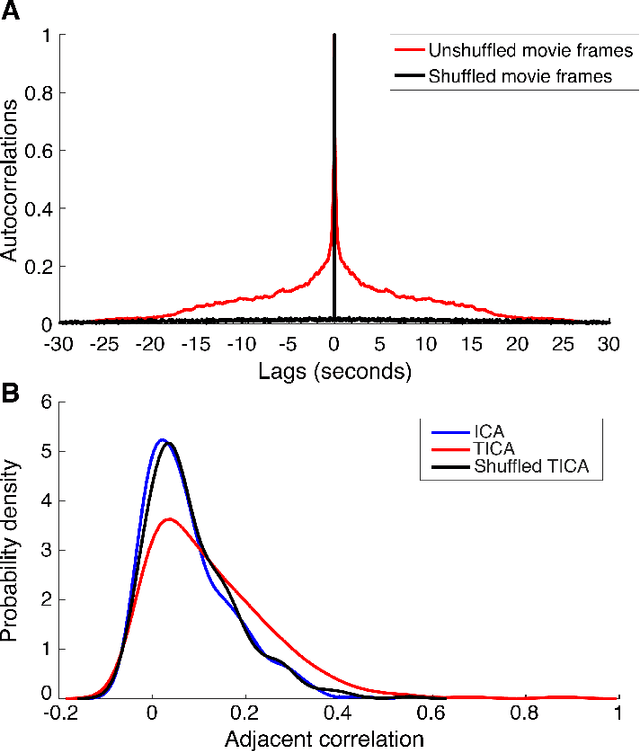
Independent component analysis (ICA) has often been used as a tool to model natural image statistics by separating multivariate signals in the image into components that are assumed to be independent. However, these estimated components oftentimes have higher order dependencies, such as co-activation of components, that are not accounted for in the model. Topographic independent component analysis(TICA), a modification of ICA, takes into account higher order dependencies and orders components topographically as a function of dependence. Here, we aim to visualize the time course of TICA basis activations to movie stimuli. We find that the activity of TICA bases are often clustered and move continuously, potentially resembling activity of topographically organized cells in the visual cortex.