 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Image-based Face Detection and Recognition: "State of the Art"
Feb 26, 2013
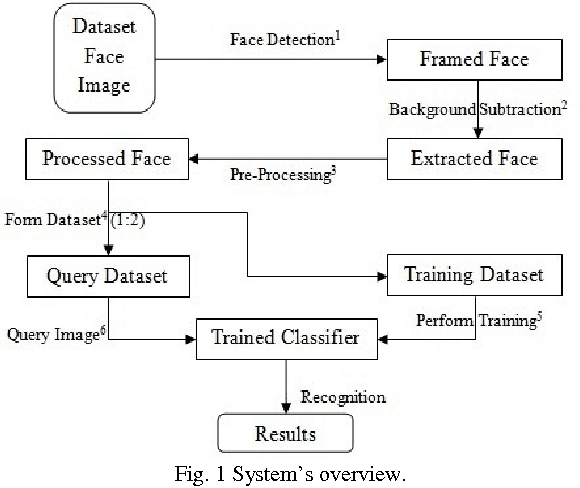
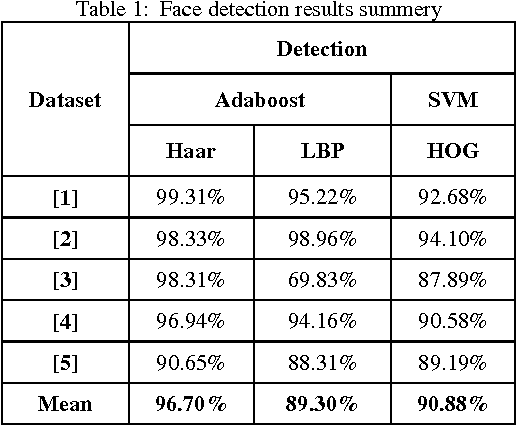
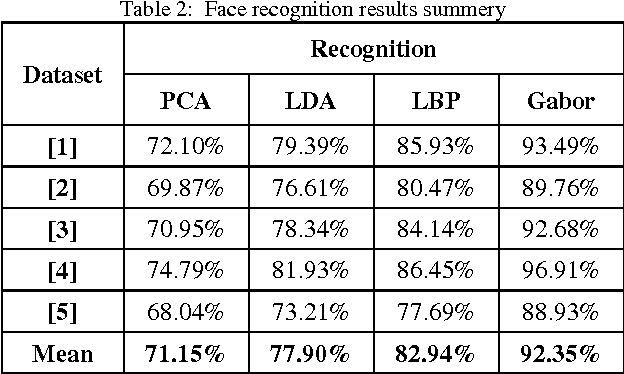

Face recognition from image or video is a popular topic in biometrics research. Many public places usually have surveillance cameras for video capture and these cameras have their significant value for security purpose. It is widely acknowledged that the face recognition have played an important role in surveillance system as it doesn't need the object's cooperation. The actual advantages of face based identification over other biometrics are uniqueness and acceptance. As human face is a dynamic object having high degree of variability in its appearance, that makes face detection a difficult problem in computer vision. In this field, accuracy and speed of identification is a main issue. The goal of this paper is to evaluate various face detection and recognition methods, provide complete solution for image based face detection and recognition with higher accuracy, better response rate as an initial step for video surveillance. Solution is proposed based on performed tests on various face rich databases in terms of subjects, pose, emotions, race and light.
* 4 pages, 3 table, 4 figure
Deep CT to MR Synthesis using Paired and Unpaired Data
Sep 03, 2018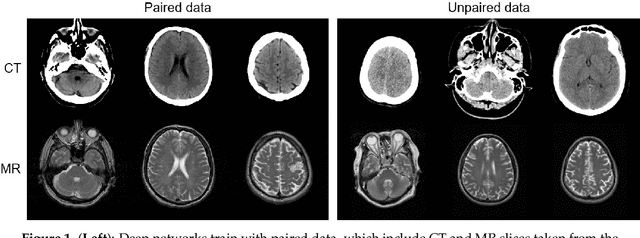
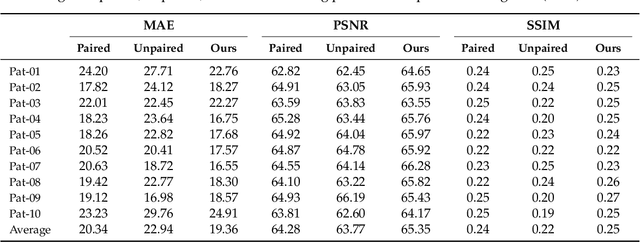
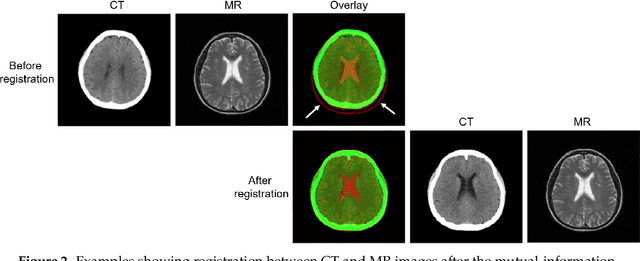
MR imaging will play a very important role in radiotherapy treatment planning for segmentation of tumor volumes and organs. However, the use of MR-based radiotherapy is limited because of the high cost and the increased use of metal implants such as cardiac pacemakers and artificial joints in aging society. To improve the accuracy of CT-based radiotherapy planning, we propose a synthetic approach that translates a CT image into an MR image using paired and unpaired training data. In contrast to the current synthetic methods for medical images, which depend on sparse pairwise-aligned data or plentiful unpaired data, the proposed approach alleviates the rigid registration challenge of paired training and overcomes the context-misalignment problem of the unpaired training. A generative adversarial network was trained to transform 2D brain CT image slices into 2D brain MR image slices, combining adversarial loss, dual cycle-consistent loss, and voxel-wise loss. The experiments were analyzed using CT and MR images of 202 patients. Qualitative and quantitative comparisons against independent paired training and unpaired training methods demonstrate the superiority of our approach.
GrappaNet: Combining Parallel Imaging with Deep Learning for Multi-Coil MRI Reconstruction
Oct 27, 2019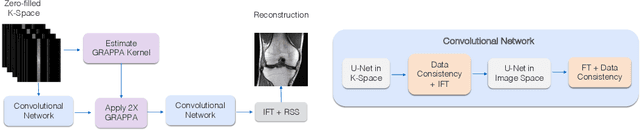
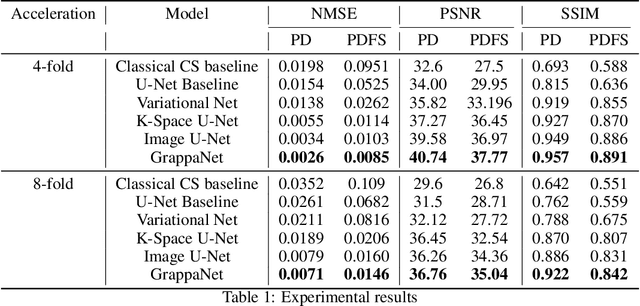
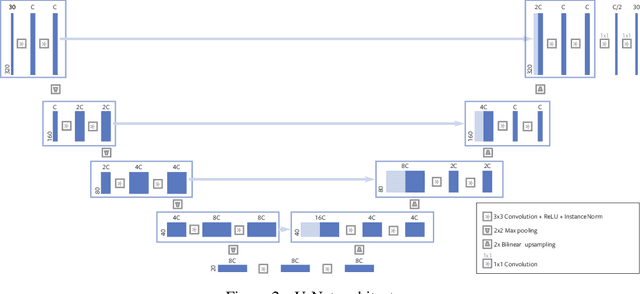
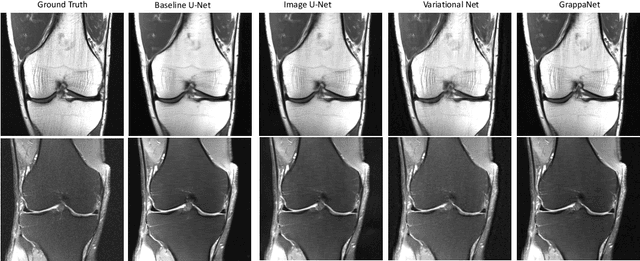
Magnetic Resonance Image (MRI) acquisition is an inherently slow process which has spurred the development of two different acceleration methods: acquiring multiple correlated samples simultaneously (parallel imaging) and acquiring fewer samples than necessary for traditional signal processing methods (compressed sensing). Both methods provide complementary approaches to accelerating the speed of MRI acquisition. In this paper, we present a novel method to integrate traditional parallel imaging methods into deep neural networks that is able to generate high quality reconstructions even for high acceleration factors. The proposed method, called GrappaNet, performs progressive reconstruction by first mapping the reconstruction problem to a simpler one that can be solved by a traditional parallel imaging methods using a neural network, followed by an application of a parallel imaging method, and finally fine-tuning the output with another neural network. The entire network can be trained end-to-end. We present experimental results on the recently released fastMRI dataset and show that GrappaNet can generate higher quality reconstructions than competing methods for both $4\times$ and $8\times$ acceleration.
Subsurface structure analysis using computational interpretation and learning: A visual signal processing perspective
Dec 20, 2018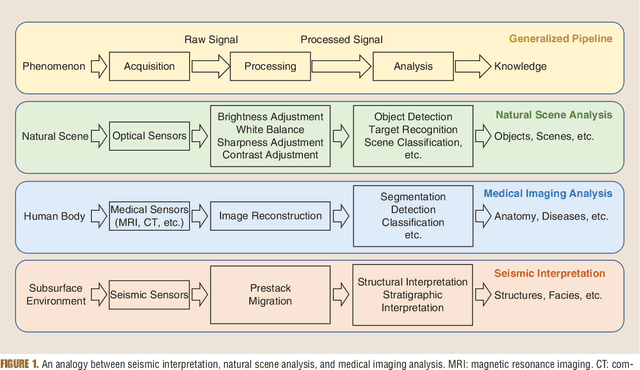
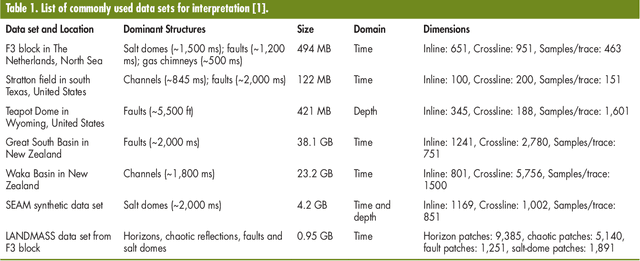

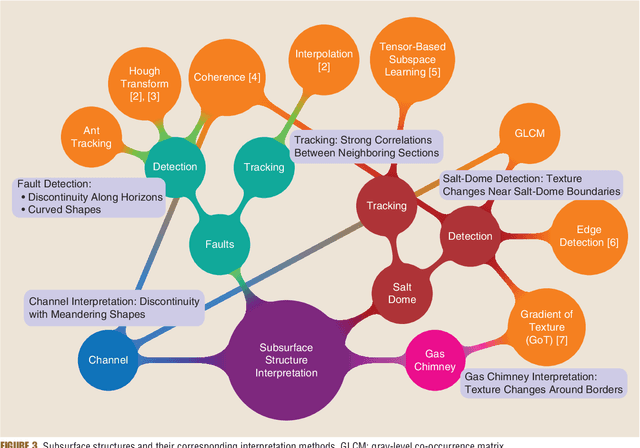
Understanding Earth's subsurface structures has been and continues to be an essential component of various applications such as environmental monitoring, carbon sequestration, and oil and gas exploration. By viewing the seismic volumes that are generated through the processing of recorded seismic traces, researchers were able to learn from applying advanced image processing and computer vision algorithms to effectively analyze and understand Earth's subsurface structures. In this paper, first, we summarize the recent advances in this direction that relied heavily on the fields of image processing and computer vision. Second, we discuss the challenges in seismic interpretation and provide insights and some directions to address such challenges using emerging machine learning algorithms.
Deep Exemplar-based Colorization
Jul 21, 2018

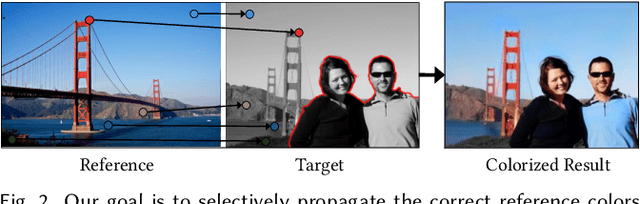
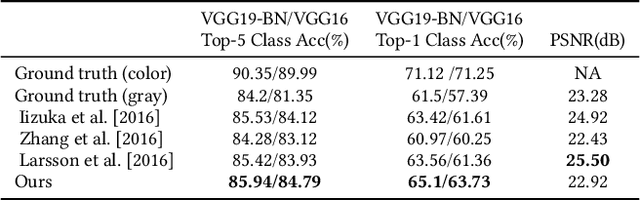
We propose the first deep learning approach for exemplar-based local colorization. Given a reference color image, our convolutional neural network directly maps a grayscale image to an output colorized image. Rather than using hand-crafted rules as in traditional exemplar-based methods, our end-to-end colorization network learns how to select, propagate, and predict colors from the large-scale data. The approach performs robustly and generalizes well even when using reference images that are unrelated to the input grayscale image. More importantly, as opposed to other learning-based colorization methods, our network allows the user to achieve customizable results by simply feeding different references. In order to further reduce manual effort in selecting the references, the system automatically recommends references with our proposed image retrieval algorithm, which considers both semantic and luminance information. The colorization can be performed fully automatically by simply picking the top reference suggestion. Our approach is validated through a user study and favorable quantitative comparisons to the-state-of-the-art methods. Furthermore, our approach can be naturally extended to video colorization. Our code and models will be freely available for public use.
Transfer Brain MRI Tumor Segmentation Models Across Modalities with Adversarial Networks
Oct 07, 2019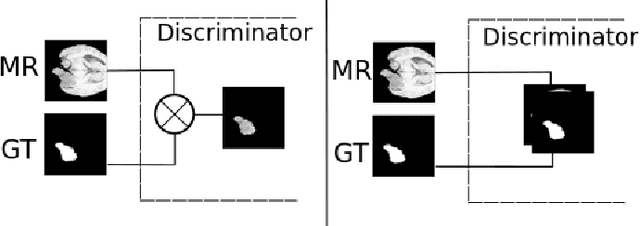
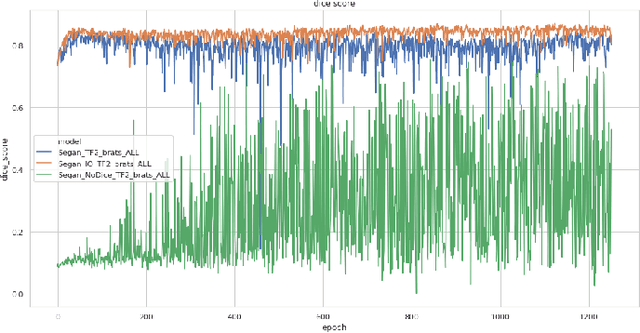
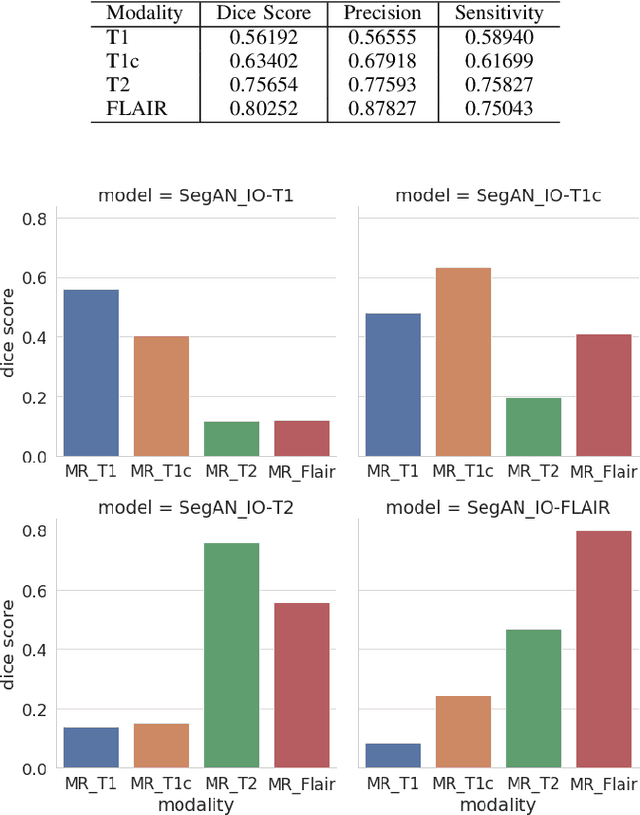

In this work, we present an approach to brain cancer segmentation in Magnetic Resonance Images (MRI) using Adversarial Networks, that have been successfully applied to several complex image processing problems in recent years. Most of the segmentation approaches presented in the literature exploit the data from all the contrast modalities typically acquired in the clinical practice: T1-weighted, T1-weighted contrast-enhanced, T2-weighted, and T2-FLAIR. Unfortunately, often not all these modalities are available for each patient. Accordingly, in this paper, we extended a previous segmentation approach based on Adversarial Networks to deal with this issue. In particular, we trained a segmentation model for each modality at once and evaluated the performances of these models. Thus, we investigated the possibility of transferring the best among these single-modality models to the other modalities. Our results suggest that such a transfer learning approach allows achieving better performances for almost all the target modalities.
L*ReLU: Piece-wise Linear Activation Functions for Deep Fine-grained Visual Categorization
Oct 27, 2019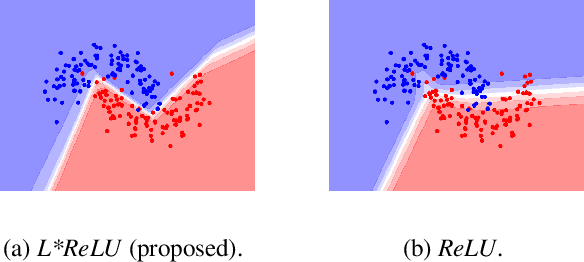

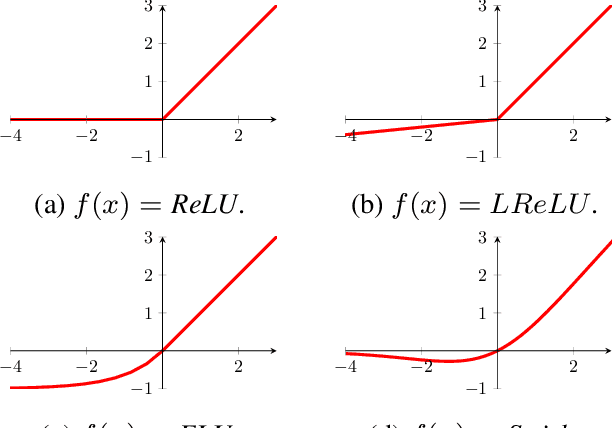
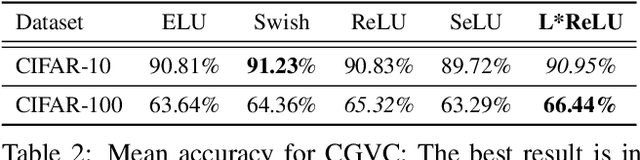
Deep neural networks paved the way for significant improvements in image visual categorization during the last years. However, even though the tasks are highly varying, differing in complexity and difficulty, existing solutions mostly build on the same architectural decisions. This also applies to the selection of activation functions (AFs), where most approaches build on Rectified Linear Units (ReLUs). In this paper, however, we show that the choice of a proper AF has a significant impact on the classification accuracy, in particular, if fine, subtle details are of relevance. Therefore, we propose to model the degree of absence and the presence of features via the AF by using piece-wise linear functions, which we refer to as L*ReLU. In this way, we can ensure the required properties, while still inheriting the benefits in terms of computational efficiency from ReLUs. We demonstrate our approach for the task of Fine-grained Visual Categorization (FGVC), running experiments on seven different benchmark datasets. The results do not only demonstrate superior results but also that for different tasks, having different characteristics, different AFs are selected.
Subtractive Perceptrons for Learning Images: A Preliminary Report
Sep 15, 2019
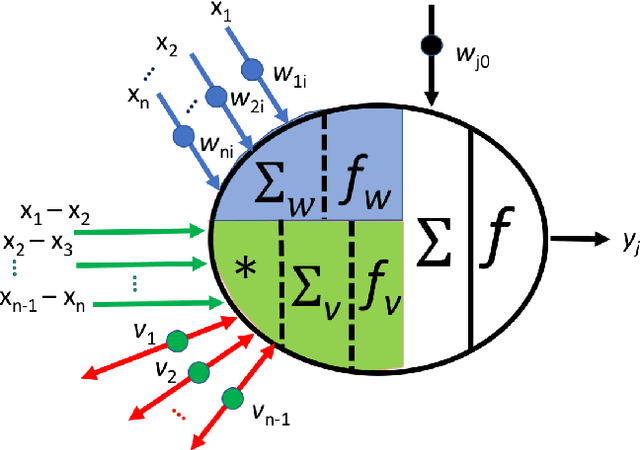
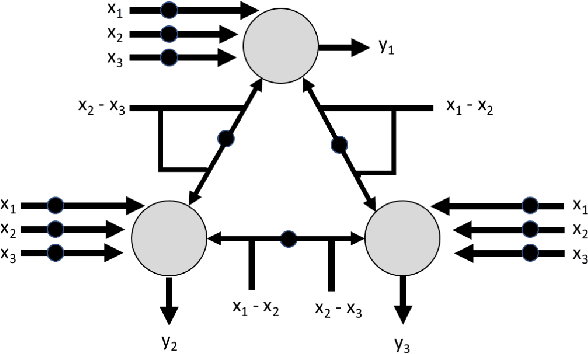
In recent years, artificial neural networks have achieved tremendous success for many vision-based tasks. However, this success remains within the paradigm of \emph{weak AI} where networks, among others, are specialized for just one given task. The path toward \emph{strong AI}, or Artificial General Intelligence, remains rather obscure. One factor, however, is clear, namely that the feed-forward structure of current networks is not a realistic abstraction of the human brain. In this preliminary work, some ideas are proposed to define a \textit{subtractive Perceptron} (s-Perceptron), a graph-based neural network that delivers a more compact topology to learn one specific task. In this preliminary study, we test the s-Perceptron with the MNIST dataset, a commonly used image archive for digit recognition. The proposed network achieves excellent results compared to the benchmark networks that rely on more complex topologies.
Deep Face Recognition Model Compression via Knowledge Transfer and Distillation
Jun 03, 2019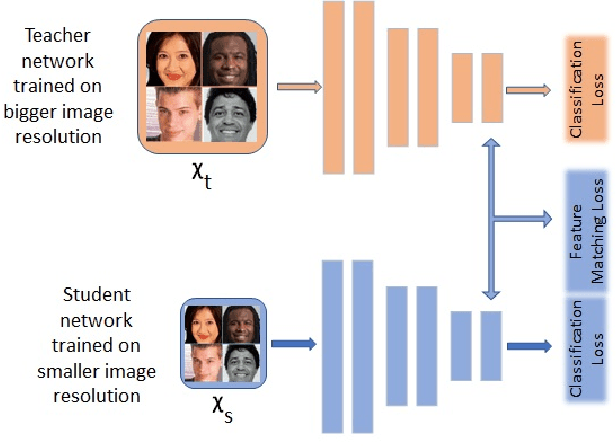
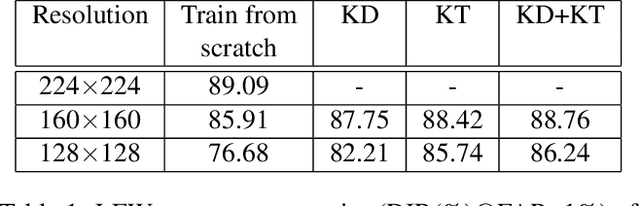
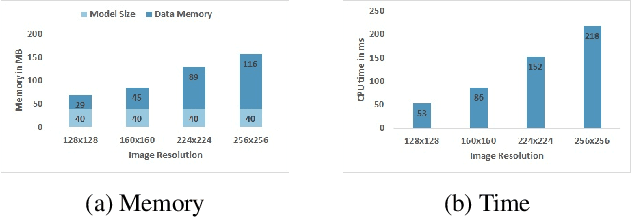
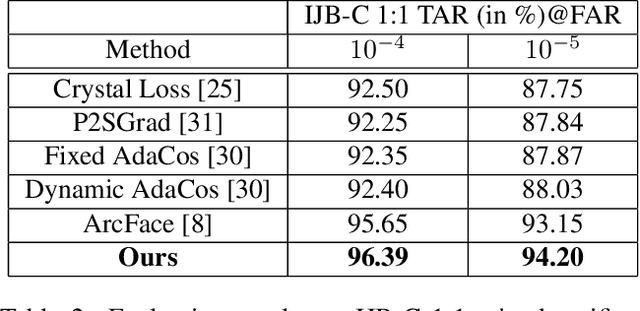
Fully convolutional networks (FCNs) have become de facto tool to achieve very high-level performance for many vision and non-vision tasks in general and face recognition in particular. Such high-level accuracies are normally obtained by very deep networks or their ensemble. However, deploying such high performing models to resource constraint devices or real-time applications is challenging. In this paper, we present a novel model compression approach based on student-teacher paradigm for face recognition applications. The proposed approach consists of training teacher FCN at bigger image resolution while student FCNs are trained at lower image resolutions than that of teacher FCN. We explored three different approaches to train student FCNs: knowledge transfer (KT), knowledge distillation (KD) and their combination. Experimental evaluation on LFW and IJB-C datasets demonstrate comparable improvements in accuracies with these approaches. Training low-resolution student FCNs from higher resolution teacher offer fourfold advantage of accelerated training, accelerated inference, reduced memory requirements and improved accuracies. We evaluated all models on IJB-C dataset and achieved state-of-the-art results on this benchmark. The teacher network and some student networks even achieved Top-1 performance on IJB-C dataset. The proposed approach is simple and hardware friendly, thus enables the deployment of high performing face recognition deep models to resource constraint devices.
Dynamic Graph Representation for Partially Occluded Biometrics
Dec 01, 2019
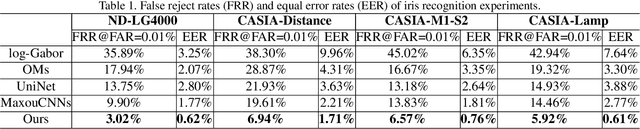
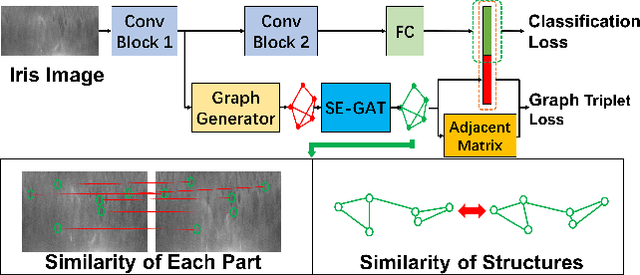
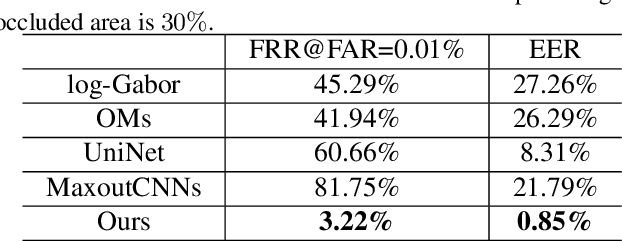
The generalization ability of Convolutional neural networks (CNNs) for biometrics drops greatly due to the adverse effects of various occlusions. To this end, we propose a novel unified framework integrated the merits of both CNNs and graphical models to learn dynamic graph representations for occlusion problems in biometrics, called Dynamic Graph Representation (DGR). Convolutional features onto certain regions are re-crafted by a graph generator to establish the connections among the spatial parts of biometrics and build Feature Graphs based on these node representations. Each node of Feature Graphs corresponds to a specific part of the input image and the edges express the spatial relationships between parts. By analyzing the similarities between the nodes, the framework is able to adaptively remove the nodes representing the occluded parts. During dynamic graph matching, we propose a novel strategy to measure the distances of both nodes and adjacent matrixes. In this way, the proposed method is more convincing than CNNs-based methods because the dynamic graph method implies a more illustrative and reasonable inference of the biometrics decision. Experiments conducted on iris and face demonstrate the superiority of the proposed framework, which boosts the accuracy of occluded biometrics recognition by a large margin comparing with baseline methods.