 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
Small-GAN: Speeding Up GAN Training Using Core-sets
Oct 29, 2019
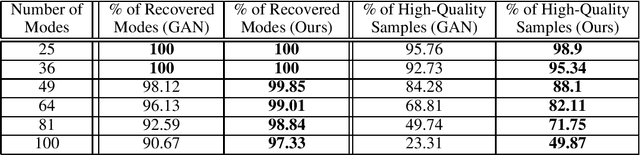
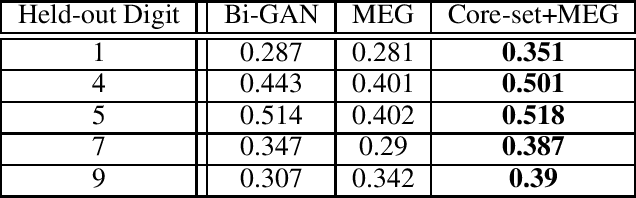


Recent work by Brock et al. (2018) suggests that Generative Adversarial Networks (GANs) benefit disproportionately from large mini-batch sizes. Unfortunately, using large batches is slow and expensive on conventional hardware. Thus, it would be nice if we could generate batches that were effectively large though actually small. In this work, we propose a method to do this, inspired by the use of Coreset-selection in active learning. When training a GAN, we draw a large batch of samples from the prior and then compress that batch using Coreset-selection. To create effectively large batches of 'real' images, we create a cached dataset of Inception activations of each training image, randomly project them down to a smaller dimension, and then use Coreset-selection on those projected activations at training time. We conduct experiments showing that this technique substantially reduces training time and memory usage for modern GAN variants, that it reduces the fraction of dropped modes in a synthetic dataset, and that it allows GANs to reach a new state of the art in anomaly detection.
ForensicTransfer: Weakly-supervised Domain Adaptation for Forgery Detection
Dec 06, 2018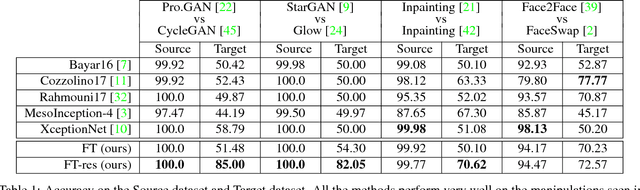
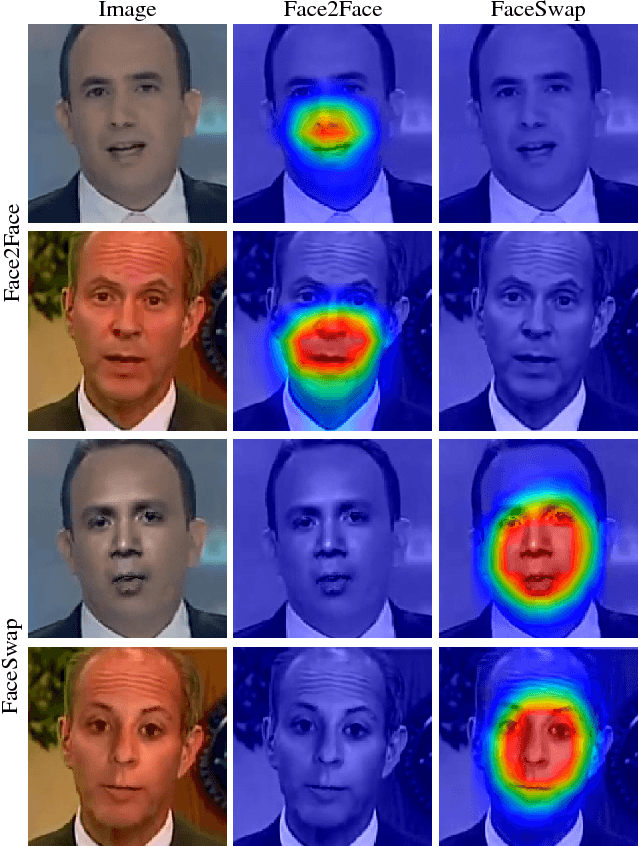


Distinguishing fakes from real images is becoming increasingly difficult as new sophisticated image manipulation approaches come out by the day. Convolutional neural networks (CNN) show excellent performance in detecting image manipulations when they are trained on a specific forgery method. However, on examples from unseen manipulation approaches, their performance drops significantly. To address this limitation in transferability, we introduce ForensicTransfer. ForensicTransfer tackles two challenges in multimedia forensics. First, we devise a learning-based forensic detector which adapts well to new domains, i.e., novel manipulation methods. Second we handle scenarios where only a handful of fake examples are available during training. To this end, we learn a forensic embedding that can be used to distinguish between real and fake imagery. We are using a new autoencoder-based architecture which enforces activations in different parts of a latent vector for the real and fake classes. Together with the constraint of correct reconstruction this ensures that the latent space keeps all the relevant information about the nature of the image. Therefore, the learned embedding acts as a form of anomaly detector; namely, an image manipulated from an unseen method will be detected as fake provided it maps sufficiently far away from the cluster of real images. Comparing with prior works, ForensicTransfer shows significant improvements in transferability, which we demonstrate in a series of experiments on cutting-edge benchmarks. For instance, on unseen examples, we achieve up to 80-85% in terms of accuracy compared to 50-59%, and with only a handful of seen examples, our performance already reaches around 95%.
Deep Learning Accelerated Light Source Experiments
Oct 09, 2019
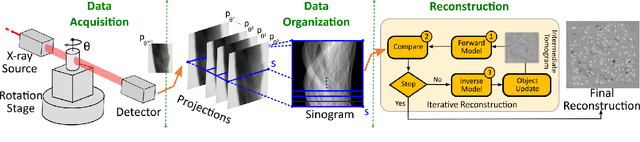

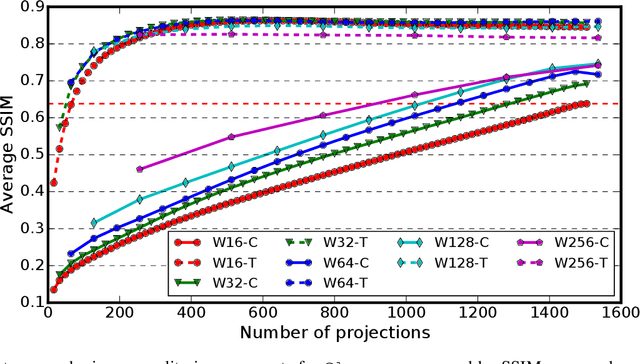
Experimental protocols at synchrotron light sources typically process and validate data only after an experiment has completed, which can lead to undetected errors and cannot enable online steering. Real-time data analysis can enable both detection of, and recovery from, errors, and optimization of data acquisition. However, modern scientific instruments, such as detectors at synchrotron light sources, can generate data at GBs/sec rates. Data processing methods such as the widely used computational tomography usually require considerable computational resources, and yield poor quality reconstructions in the early stages of data acquisition when available views are sparse. We describe here how a deep convolutional neural network can be integrated into the real-time streaming tomography pipeline to enable better-quality images in the early stages of data acquisition. Compared with conventional streaming tomography processing, our method can significantly improve tomography image quality, deliver comparable images using only 32% of the data needed for conventional streaming processing, and save 68% experiment time for data acquisition.
MetalGAN: a Cluster-based Adaptive Training for Few-Shot Adversarial Colorization
Sep 17, 2019
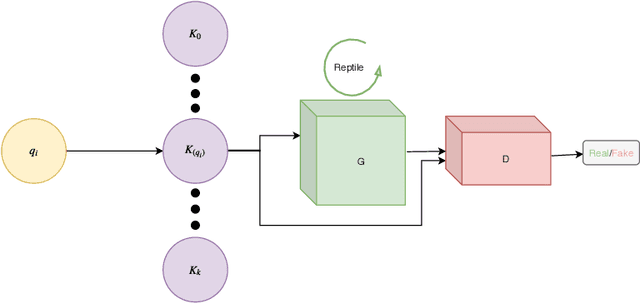


In recent years, the majority of works on deep-learning-based image colorization have focused on how to make a good use of the enormous datasets currently available. What about when the data at disposal are scarce? The main objective of this work is to prove that a network can be trained and can provide excellent colorization results even without a large quantity of data. The adopted approach is a mixed one, which uses an adversarial method for the actual colorization, and a meta-learning technique to enhance the generator model. Also, a clusterization a-priori of the training dataset ensures a task-oriented division useful for meta-learning, and at the same time reduces the per-step number of images. This paper describes in detail the method and its main motivations, and a discussion of results and future developments is provided.
Semi-Adversarial Networks: Convolutional Autoencoders for Imparting Privacy to Face Images
May 03, 2018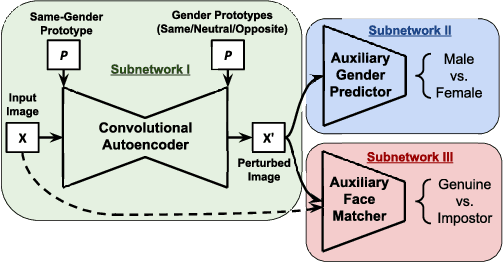
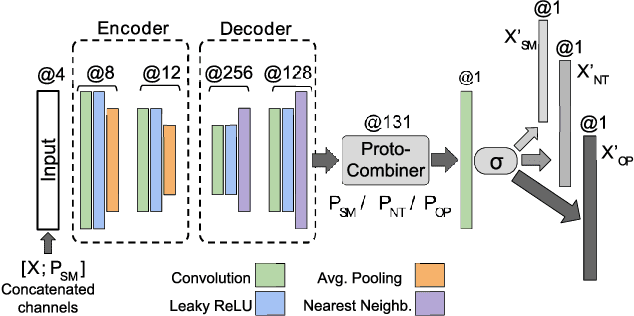
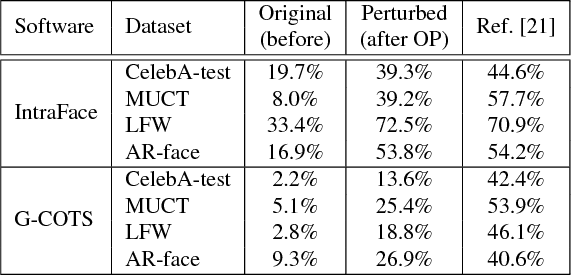
In this paper, we design and evaluate a convolutional autoencoder that perturbs an input face image to impart privacy to a subject. Specifically, the proposed autoencoder transforms an input face image such that the transformed image can be successfully used for face recognition but not for gender classification. In order to train this autoencoder, we propose a novel training scheme, referred to as semi-adversarial training in this work. The training is facilitated by attaching a semi-adversarial module consisting of a pseudo gender classifier and a pseudo face matcher to the autoencoder. The objective function utilized for training this network has three terms: one to ensure that the perturbed image is a realistic face image; another to ensure that the gender attributes of the face are confounded; and a third to ensure that biometric recognition performance due to the perturbed image is not impacted. Extensive experiments confirm the efficacy of the proposed architecture in extending gender privacy to face images.
Texture feature extraction in the spatial-frequency domain for content-based image retrieval
Dec 23, 2010
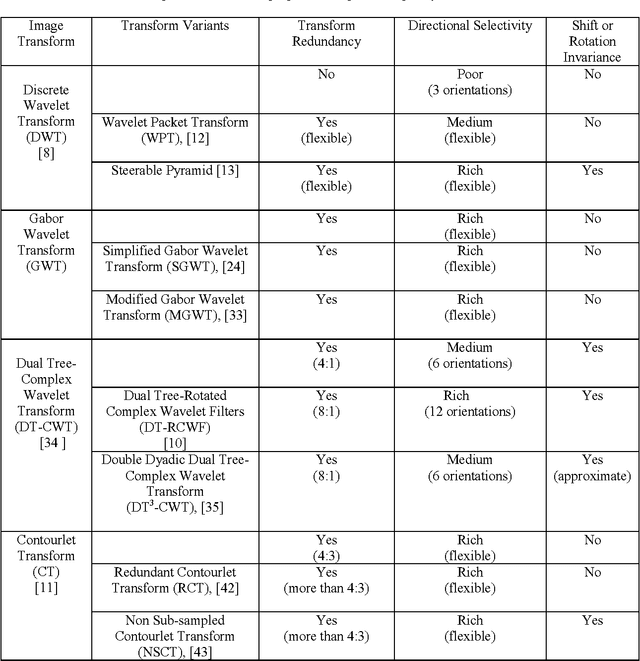

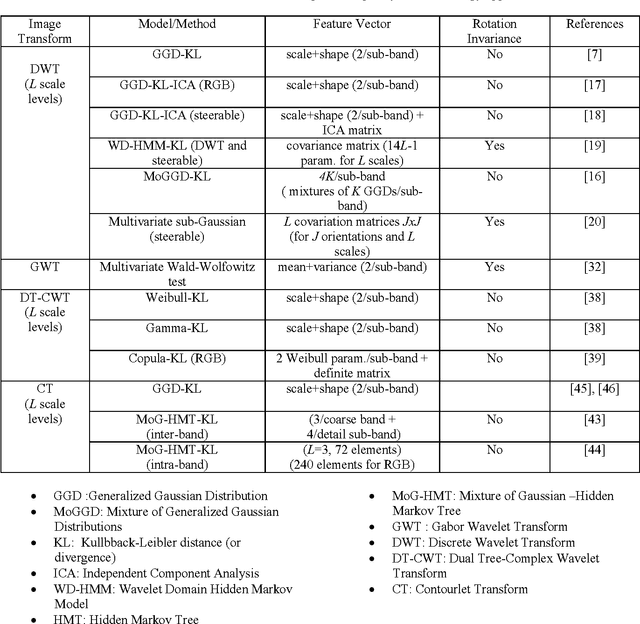
The advent of large scale multimedia databases has led to great challenges in content-based image retrieval (CBIR). Even though CBIR is considered an emerging field of research, however it constitutes a strong background for new methodologies and systems implementations. Therefore, many research contributions are focusing on techniques enabling higher image retrieval accuracy while preserving low level of computational complexity. Image retrieval based on texture features is receiving special attention because of the omnipresence of this visual feature in most real-world images. This paper highlights the state-of-the-art and current progress relevant to texture-based image retrieval and spatial-frequency image representations. In particular, it gives an overview of statistical methodologies and techniques employed for texture feature extraction using most popular spatial-frequency image transforms, namely discrete wavelets, Gabor wavelets, dual-tree complex wavelet and contourlets. Indications are also given about used similarity measurement functions and most important achieved results.
Registration and Fusion of Multi-Spectral Images Using a Novel Edge Descriptor
May 28, 2018
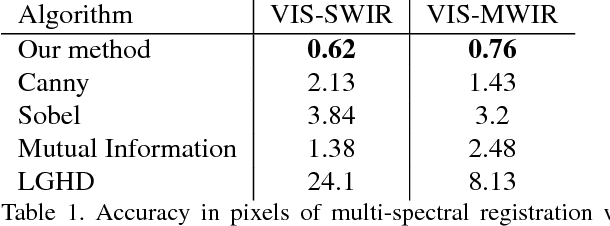
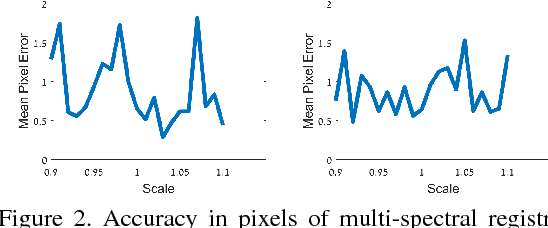

In this paper we introduce a fully end-to-end approach for multi-spectral image registration and fusion. Our method for fusion combines images from different spectral channels into a single fused image by different approaches for low and high frequency signals. A prerequisite of fusion is a stage of geometric alignment between the spectral bands, commonly referred to as registration. Unfortunately, common methods for image registration of a single spectral channel do not yield reasonable results on images from different modalities. For that end, we introduce a new algorithm for multi-spectral image registration, based on a novel edge descriptor of feature points. Our method achieves an accurate alignment of a level that allows us to further fuse the images. As our experiments show, we produce a high quality of multi-spectral image registration and fusion under many challenging scenarios.
Dense Pose Transfer
Sep 06, 2018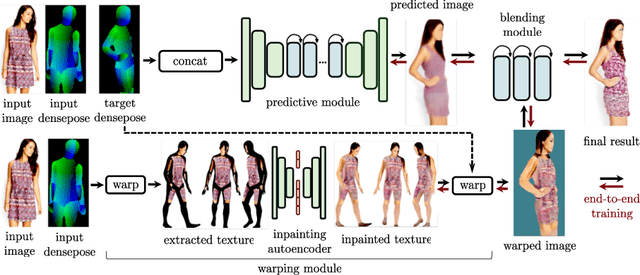
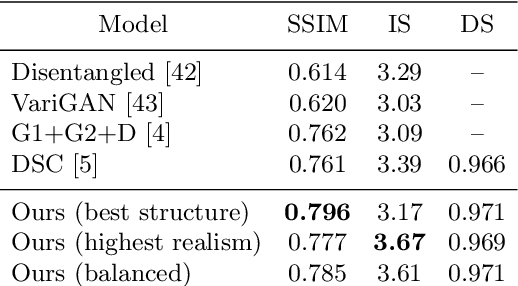
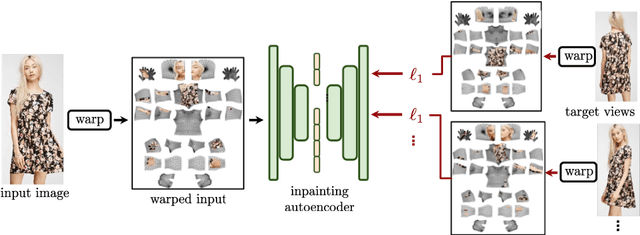
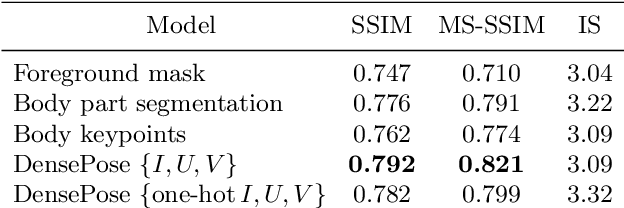
In this work we integrate ideas from surface-based modeling with neural synthesis: we propose a combination of surface-based pose estimation and deep generative models that allows us to perform accurate pose transfer, i.e. synthesize a new image of a person based on a single image of that person and the image of a pose donor. We use a dense pose estimation system that maps pixels from both images to a common surface-based coordinate system, allowing the two images to be brought in correspondence with each other. We inpaint and refine the source image intensities in the surface coordinate system, prior to warping them onto the target pose. These predictions are fused with those of a convolutional predictive module through a neural synthesis module allowing for training the whole pipeline jointly end-to-end, optimizing a combination of adversarial and perceptual losses. We show that dense pose estimation is a substantially more powerful conditioning input than landmark-, or mask-based alternatives, and report systematic improvements over state of the art generators on DeepFashion and MVC datasets.
Effects of annotation granularity in deep learning models for histopathological images
Jan 14, 2020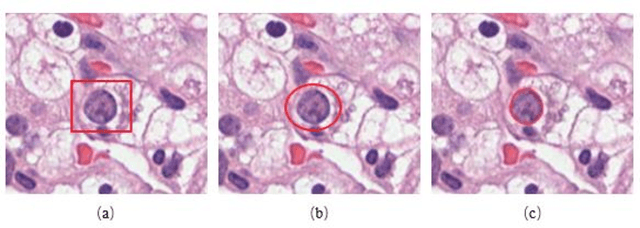

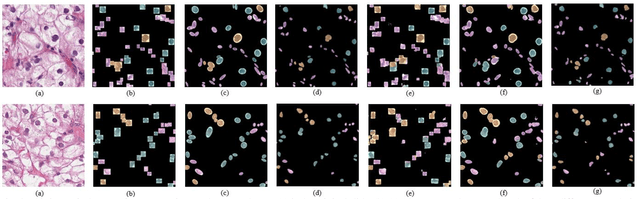

Pathological is crucial to cancer diagnosis. Usually, Pathologists draw their conclusion based on observed cell and tissue structure on histology slides. Rapid development in machine learning, especially deep learning have established robust and accurate classifiers. They are being used to analyze histopathological slides and assist pathologists in diagnosis. Most machine learning systems rely heavily on annotated data sets to gain experiences and knowledge to correctly and accurately perform various tasks such as classification and segmentation. This work investigates different granularity of annotations in histopathological data set including image-wise, bounding box, ellipse-wise, and pixel-wise to verify the influence of annotation in pathological slide on deep learning models. We design corresponding experiments to test classification and segmentation performance of deep learning models based on annotations with different annotation granularity. In classification, state-of-the-art deep learning-based classifiers perform better when trained by pixel-wise annotation dataset. On average, precision, recall and F1-score improves by 7.87%, 8.83% and 7.85% respectively. Thus, it is suggested that finer granularity annotations are better utilized by deep learning algorithms in classification tasks. Similarly, semantic segmentation algorithms can achieve 8.33% better segmentation accuracy when trained by pixel-wise annotations. Our study shows not only that finer-grained annotation can improve the performance of deep learning models, but also help extracts more accurate phenotypic information from histopathological slides. Intelligence systems trained on granular annotations may help pathologists inspecting certain regions for better diagnosis. The compartmentalized prediction approach similar to this work may contribute to phenotype and genotype association studies.
Variable selection with false discovery rate control in deep neural networks
Sep 17, 2019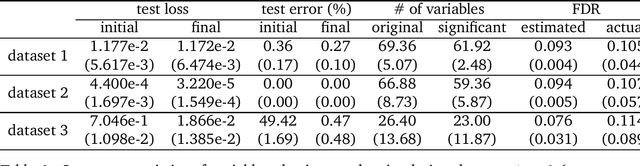
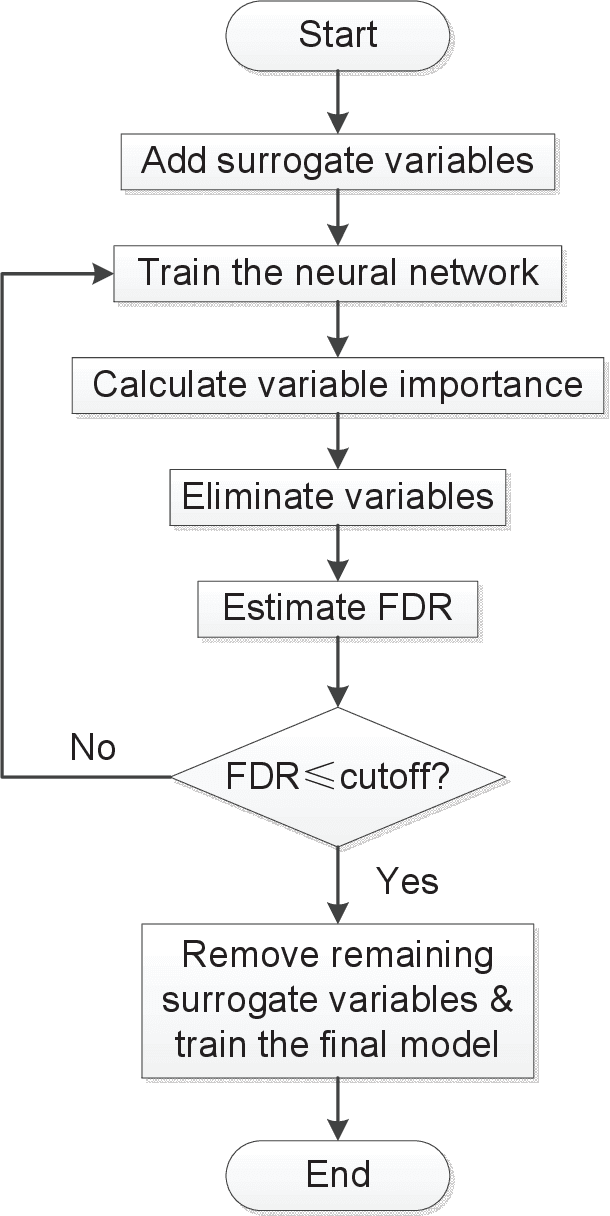
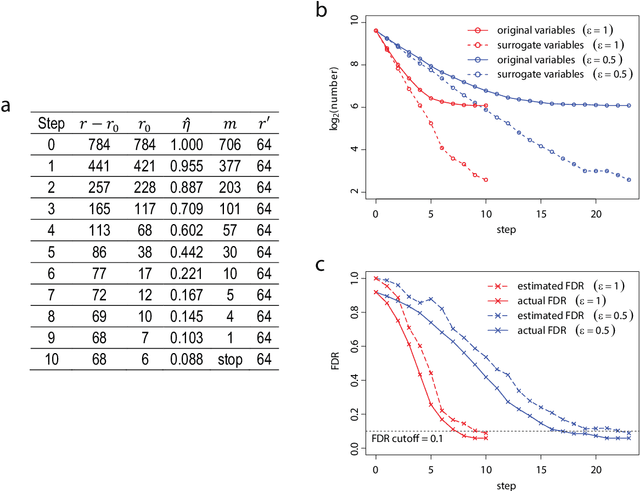

Deep neural networks (DNNs) are famous for their high prediction accuracy, but they are also known for their black-box nature and poor interpretability. We consider the problem of variable selection, that is, selecting the input variables that have significant predictive power on the output, in DNNs. We propose a backward elimination procedure called SurvNet, which is based on a new measure of variable importance that applies to a wide variety of networks. More importantly, SurvNet is able to estimate and control the false discovery rate of selected variables, while no existing methods provide such a quality control. Further, SurvNet adaptively determines how many variables to eliminate at each step in order to maximize the selection efficiency. To study its validity, SurvNet is applied to image data and gene expression data, as well as various simulation datasets.