 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
A Generative Approach Towards Improved Robotic Detection of Marine Litter
Oct 10, 2019


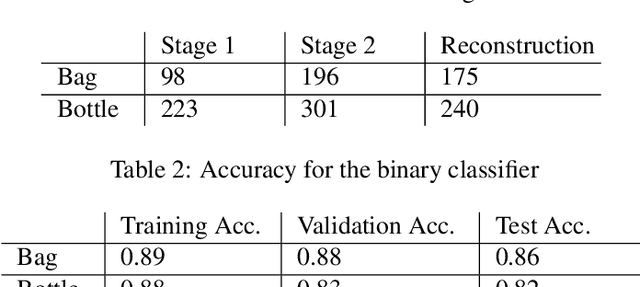
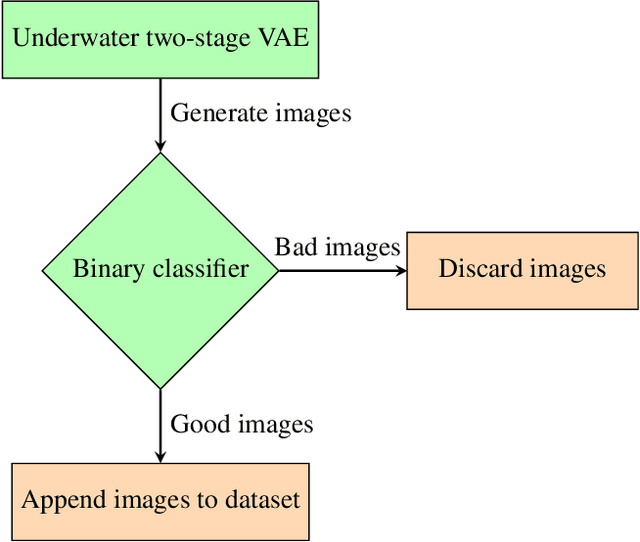
This paper presents an approach to address data scarcity problems in underwater image datasets for visual detection of marine debris. The proposed approach relies on a two-stage variational autoencoder (VAE) and a binary classifier to evaluate the generated imagery for quality and realism. From the images generated by the two-stage VAE, the binary classifier selects "good quality" images and augments the given dataset with them. Lastly, a multi-class classifier is used to evaluate the impact of the augmentation process by measuring the accuracy of an object detector trained on combinations of real and generated trash images. Our results show that the classifier trained with the augmented data outperforms the one trained only with the real data. This approach will not only be valid for the underwater trash classification problem presented in this paper, but it will also be useful for any data-dependent task for which collecting more images is challenging or infeasible.
MoverScore: Text Generation Evaluating with Contextualized Embeddings and Earth Mover Distance
Sep 05, 2019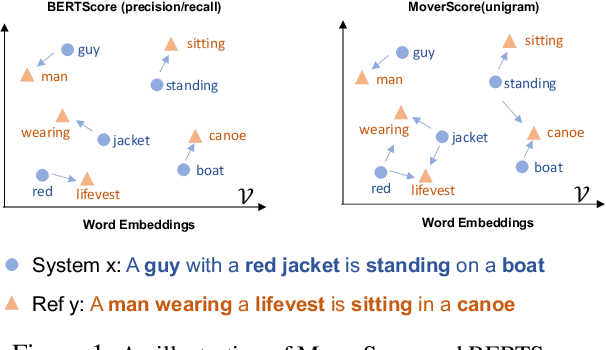
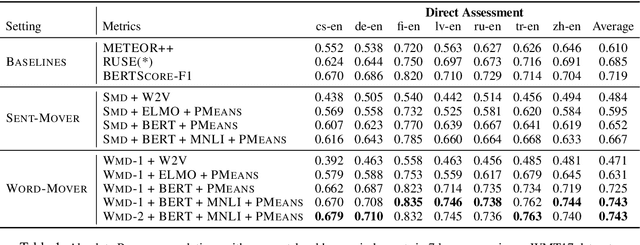
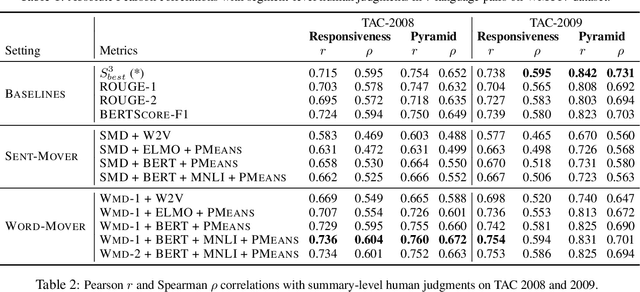
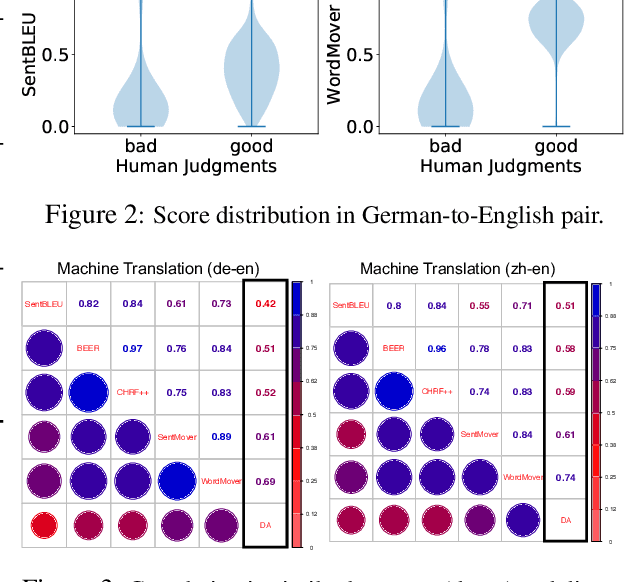
A robust evaluation metric has a profound impact on the development of text generation systems. A desirable metric compares system output against references based on their semantics rather than surface forms. In this paper we investigate strategies to encode system and reference texts to devise a metric that shows a high correlation with human judgment of text quality. We validate our new metric, namely MoverScore, on a number of text generation tasks including summarization, machine translation, image captioning, and data-to-text generation, where the outputs are produced by a variety of neural and non-neural systems. Our findings suggest that metrics combining contextualized representations with a distance measure perform the best. Such metrics also demonstrate strong generalization capability across tasks. For ease-of-use we make our metrics available as web service.
AANet: Attribute Attention Network for Person Re-Identifications
Dec 19, 2019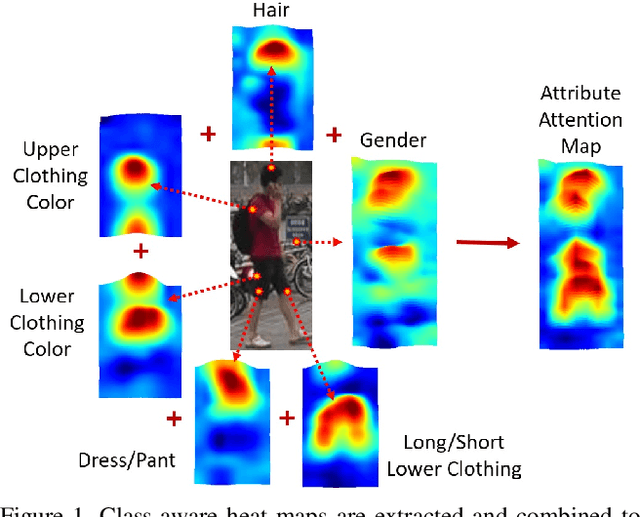
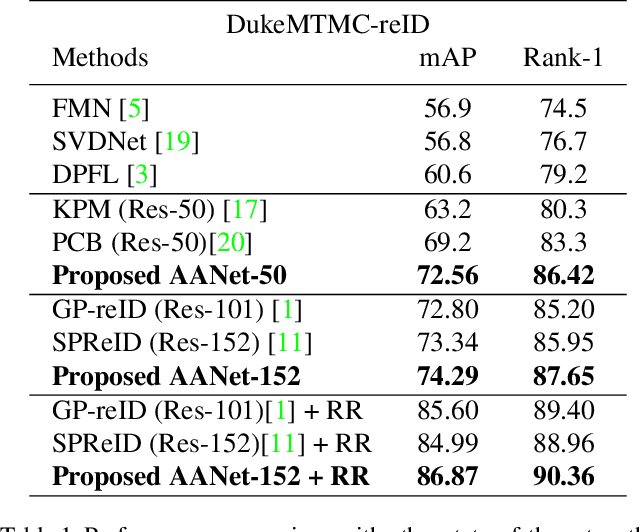

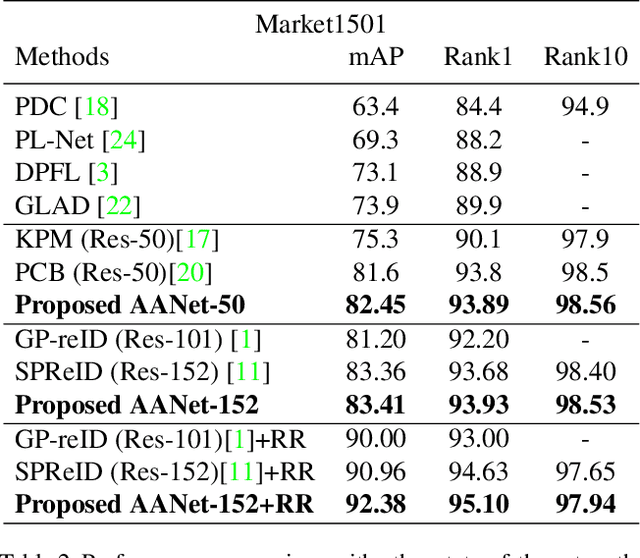
This paper proposes Attribute Attention Network (AANet), a new architecture that integrates person attributes and attribute attention maps into a classification framework to solve the person re-identification (re-ID) problem. Many person re-ID models typically employ semantic cues such as body parts or human pose to improve the re-ID performance. Attribute information, however, is often not utilized. The proposed AANet leverages on a baseline model that uses body parts and integrates the key attribute information in an unified learning framework. The AANet consists of a global person ID task, a part detection task and a crucial attribute detection task. By estimating the class responses of individual attributes and combining them to form the attribute attention map (AAM), a very strong discriminatory representation is constructed. The proposed AANet outperforms the best state-of-the-art method arXiv:1711.09349v3 [cs.CV] using ResNet-50 by 3.36% in mAP and 3.12% in Rank-1 accuracy on DukeMTMC-reID dataset. On Market1501 dataset, AANet achieves 92.38% mAP and 95.10% Rank-1 accuracy with re-ranking, outperforming arXiv:1804.00216v1 [cs.CV], another state of the art method using ResNet-152, by 1.42% in mAP and 0.47% in Rank-1 accuracy. In addition, AANet can perform person attribute prediction (e.g., gender, hair length, clothing length etc.), and localize the attributes in the query image.
Learning to Learn Relation for Important People Detection in Still Images
Apr 07, 2019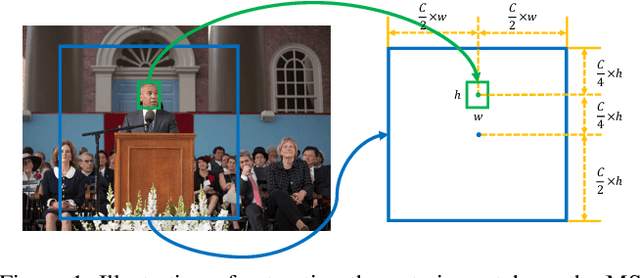
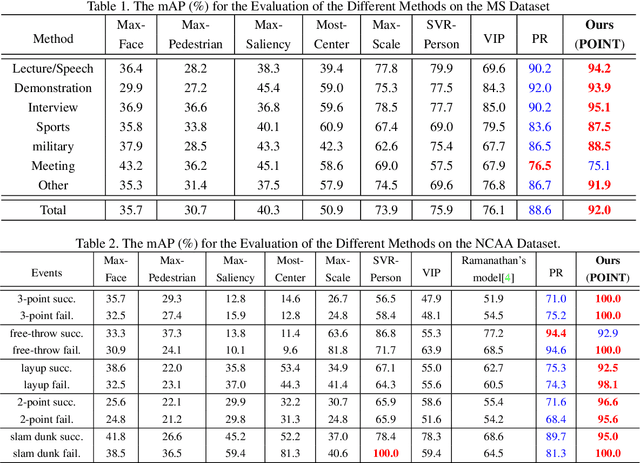
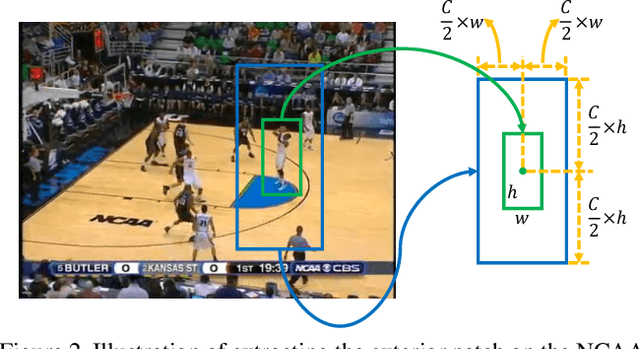
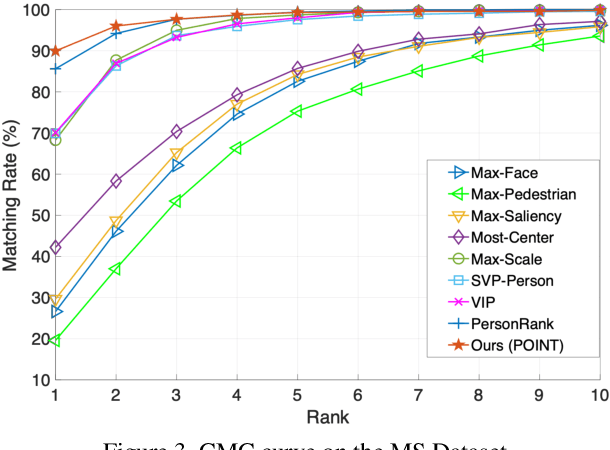
Humans can easily recognize the importance of people in social event images, and they always focus on the most important individuals. However, learning to learn the relation between people in an image, and inferring the most important person based on this relation, remains undeveloped. In this work, we propose a deep imPOrtance relatIon NeTwork (POINT) that combines both relation modeling and feature learning. In particular, we infer two types of interaction modules: the person-person interaction module that learns the interaction between people and the event-person interaction module that learns to describe how a person is involved in the event occurring in an image. We then estimate the importance relations among people from both interactions and encode the relation feature from the importance relations. In this way, POINT automatically learns several types of relation features in parallel, and we aggregate these relation features and the person's feature to form the importance feature for important people classification. Extensive experimental results show that our method is effective for important people detection and verify the efficacy of learning to learn relations for important people detection.
An Internal Learning Approach to Video Inpainting
Sep 17, 2019
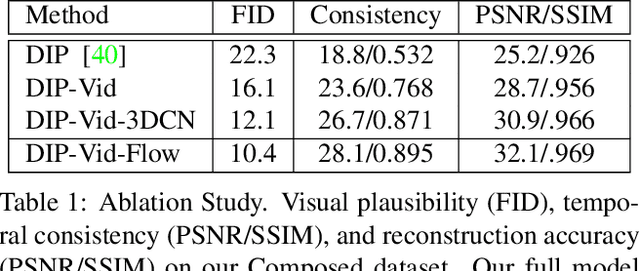
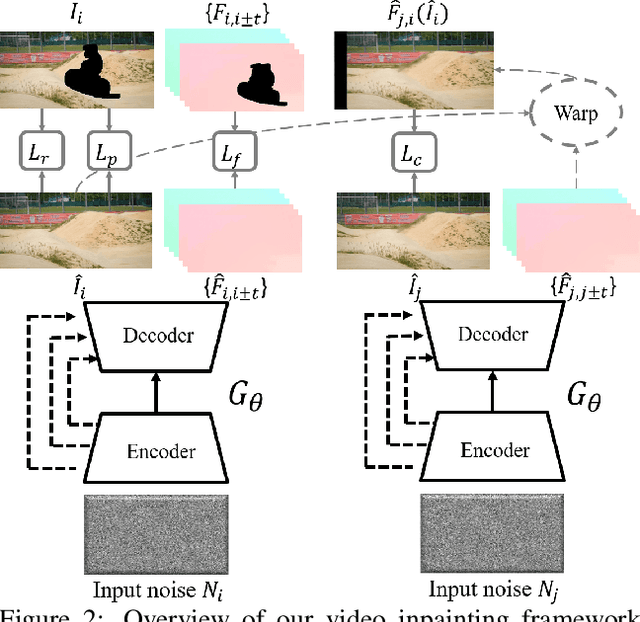
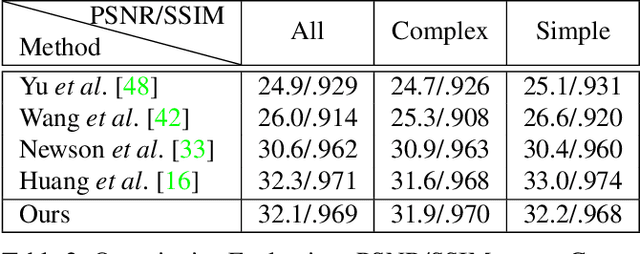
We propose a novel video inpainting algorithm that simultaneously hallucinates missing appearance and motion (optical flow) information, building upon the recent 'Deep Image Prior' (DIP) that exploits convolutional network architectures to enforce plausible texture in static images. In extending DIP to video we make two important contributions. First, we show that coherent video inpainting is possible without a priori training. We take a generative approach to inpainting based on internal (within-video) learning without reliance upon an external corpus of visual data to train a one-size-fits-all model for the large space of general videos. Second, we show that such a framework can jointly generate both appearance and flow, whilst exploiting these complementary modalities to ensure mutual consistency. We show that leveraging appearance statistics specific to each video achieves visually plausible results whilst handling the challenging problem of long-term consistency.
ForensicTransfer: Weakly-supervised Domain Adaptation for Forgery Detection
Dec 06, 2018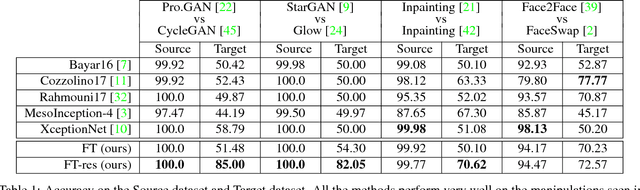
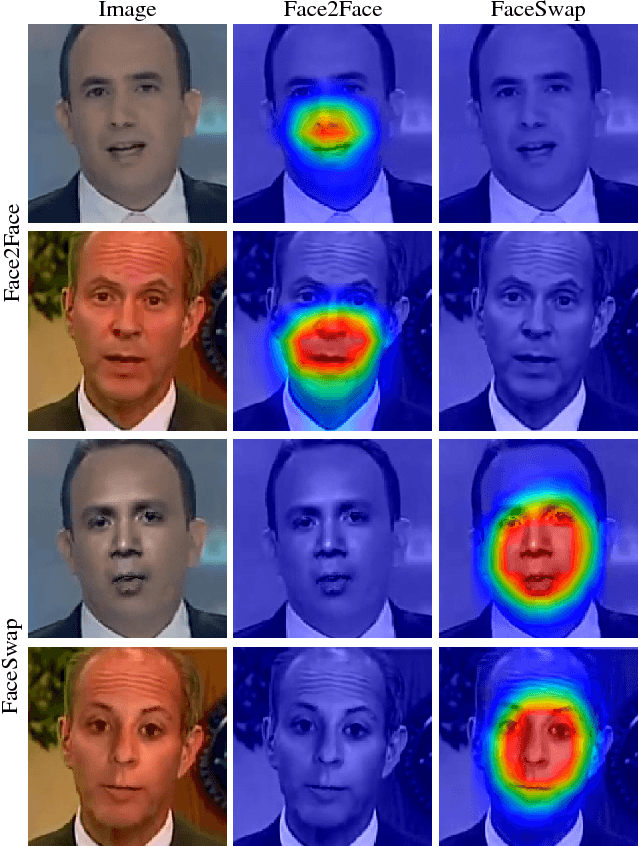


Distinguishing fakes from real images is becoming increasingly difficult as new sophisticated image manipulation approaches come out by the day. Convolutional neural networks (CNN) show excellent performance in detecting image manipulations when they are trained on a specific forgery method. However, on examples from unseen manipulation approaches, their performance drops significantly. To address this limitation in transferability, we introduce ForensicTransfer. ForensicTransfer tackles two challenges in multimedia forensics. First, we devise a learning-based forensic detector which adapts well to new domains, i.e., novel manipulation methods. Second we handle scenarios where only a handful of fake examples are available during training. To this end, we learn a forensic embedding that can be used to distinguish between real and fake imagery. We are using a new autoencoder-based architecture which enforces activations in different parts of a latent vector for the real and fake classes. Together with the constraint of correct reconstruction this ensures that the latent space keeps all the relevant information about the nature of the image. Therefore, the learned embedding acts as a form of anomaly detector; namely, an image manipulated from an unseen method will be detected as fake provided it maps sufficiently far away from the cluster of real images. Comparing with prior works, ForensicTransfer shows significant improvements in transferability, which we demonstrate in a series of experiments on cutting-edge benchmarks. For instance, on unseen examples, we achieve up to 80-85% in terms of accuracy compared to 50-59%, and with only a handful of seen examples, our performance already reaches around 95%.
Deep Mouse: An End-to-end Auto-context Refinement Framework for Brain Ventricle and Body Segmentation in Embryonic Mice Ultrasound Volumes
Oct 30, 2019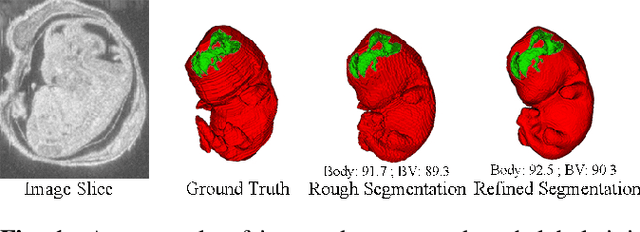
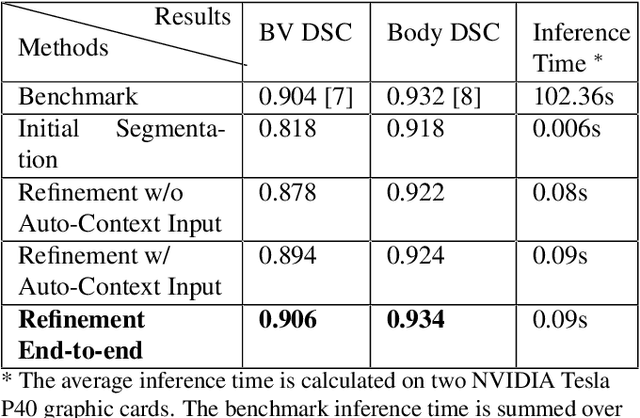
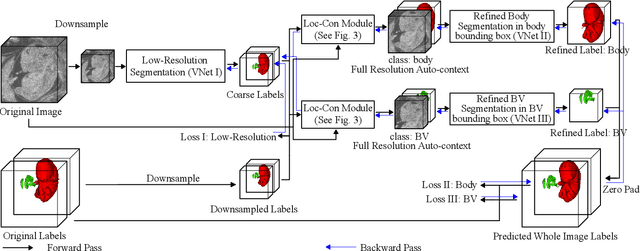
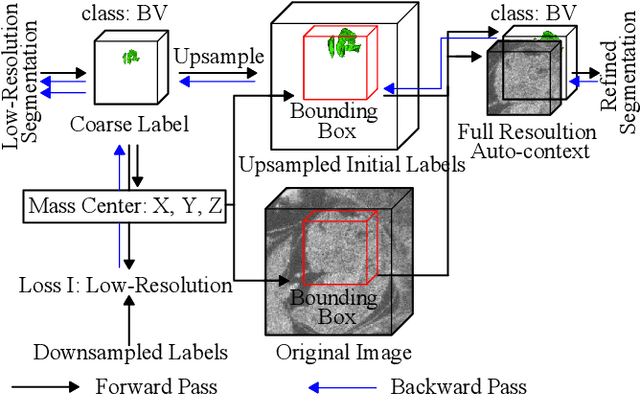
High-frequency ultrasound (HFU) is well suited for imaging embryonic mice due to its noninvasive and real-time characteristics. However, manual segmentation of the brain ventricles (BVs) and body requires substantial time and expertise. This work proposes a novel deep learning based end-to-end auto-context refinement framework, consisting of two stages. The first stage produces a low resolution segmentation of the BV and body simultaneously. The resulting probability map for each object (BV or body) is then used to crop a region of interest (ROI) around the target object in both the original image and the probability map to provide context to the refinement segmentation network. Joint training of the two stages provides significant improvement in Dice Similarity Coefficient (DSC) over using only the first stage (0.818 to 0.906 for the BV, and 0.919 to 0.934 for the body). The proposed method significantly reduces the inference time (102.36 to 0.09 s/volume around 1000x faster) while slightly improves the segmentation accuracy over the previous methods using slide-window approaches.
Decoupling Adaptation from Modeling with Meta-Optimizers for Meta Learning
Oct 30, 2019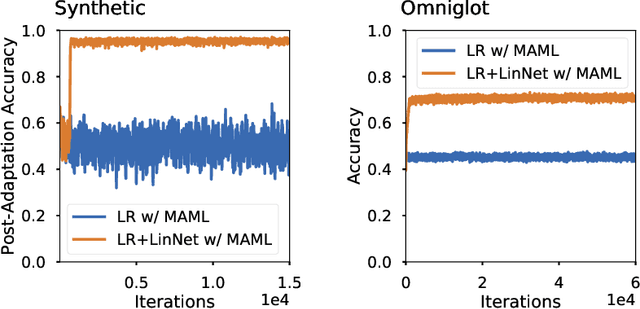

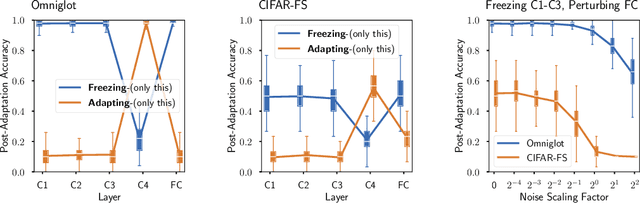

Meta-learning methods, most notably Model-Agnostic Meta-Learning or MAML, have achieved great success in adapting to new tasks quickly, after having been trained on similar tasks. The mechanism behind their success, however, is poorly understood. We begin this work with an experimental analysis of MAML, finding that deep models are crucial for its success, even given sets of simple tasks where a linear model would suffice on any individual task. Furthermore, on image-recognition tasks, we find that the early layers of MAML-trained models learn task-invariant features, while later layers are used for adaptation, providing further evidence that these models require greater capacity than is strictly necessary for their individual tasks. Following our findings, we propose a method which enables better use of model capacity at inference time by separating the adaptation aspect of meta-learning into parameters that are only used for adaptation but are not part of the forward model. We find that our approach enables more effective meta-learning in smaller models, which are suitably sized for the individual tasks.
Semi-Adversarial Networks: Convolutional Autoencoders for Imparting Privacy to Face Images
May 03, 2018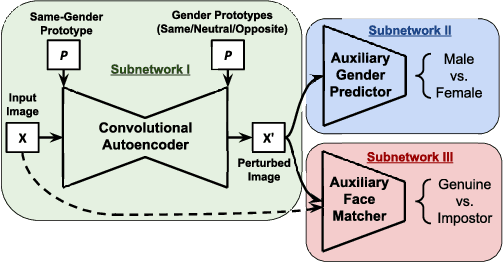
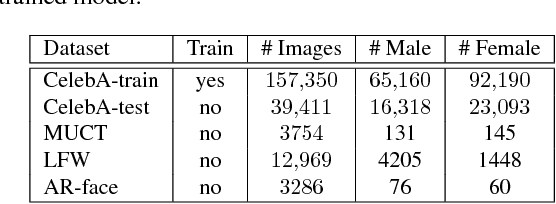
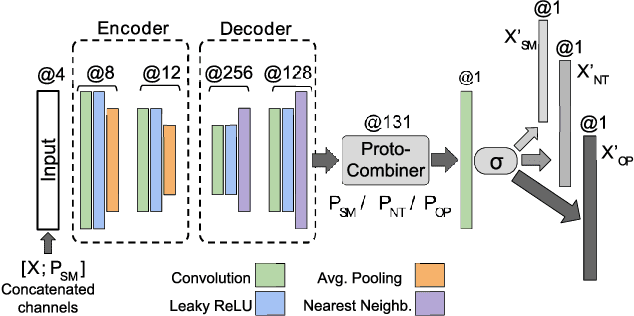
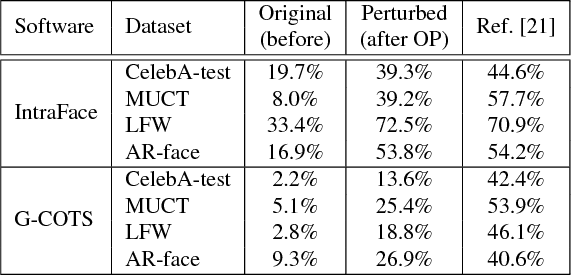
In this paper, we design and evaluate a convolutional autoencoder that perturbs an input face image to impart privacy to a subject. Specifically, the proposed autoencoder transforms an input face image such that the transformed image can be successfully used for face recognition but not for gender classification. In order to train this autoencoder, we propose a novel training scheme, referred to as semi-adversarial training in this work. The training is facilitated by attaching a semi-adversarial module consisting of a pseudo gender classifier and a pseudo face matcher to the autoencoder. The objective function utilized for training this network has three terms: one to ensure that the perturbed image is a realistic face image; another to ensure that the gender attributes of the face are confounded; and a third to ensure that biometric recognition performance due to the perturbed image is not impacted. Extensive experiments confirm the efficacy of the proposed architecture in extending gender privacy to face images.
Fitness Done Right: a Real-time Intelligent Personal Trainer for Exercise Correction
Oct 30, 2019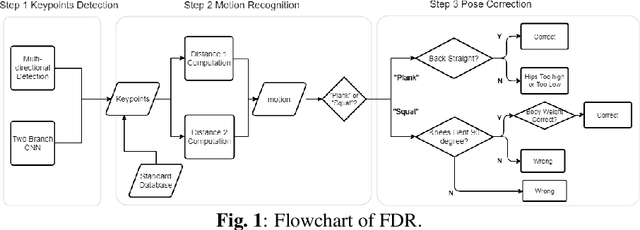
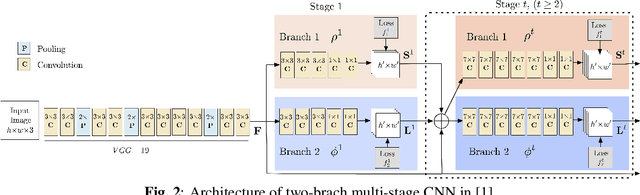
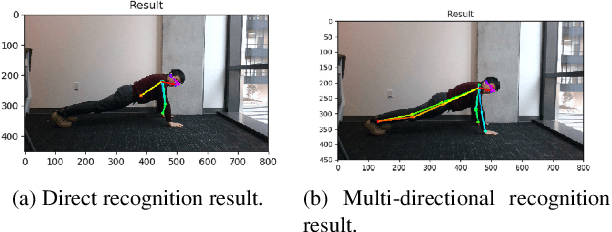
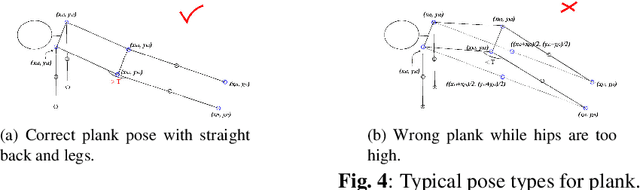
Keeping fit has been increasingly important for people nowadays. However, people may not get expected exercise results without following professional guidance while hiring personal trainers is expensive. In this paper, an effective real-time system called Fitness Done Right (FDR) is proposed for helping people exercise correctly on their own. The system includes detecting human body parts, recognizing exercise pose and detecting errors for test poses as well as giving correction advice. Generally, two branch multi-stage CNN is used for training data sets in order to learn human body parts and associations. Then, considering two poses, which are plank and squat in our model, we design a detection algorithm, combining Euclidean and angle distances, to determine the pose in the image. Finally, key values for key features of the two poses are computed correspondingly in the pose error detection part, which helps give correction advice. We conduct our system in real-time situation with error rate down to $1.2\%$, and the screenshots of experimental results are also presented.