 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Image": models, code, and papers
KoPA: Automated Kronecker Product Approximation
Dec 05, 2019

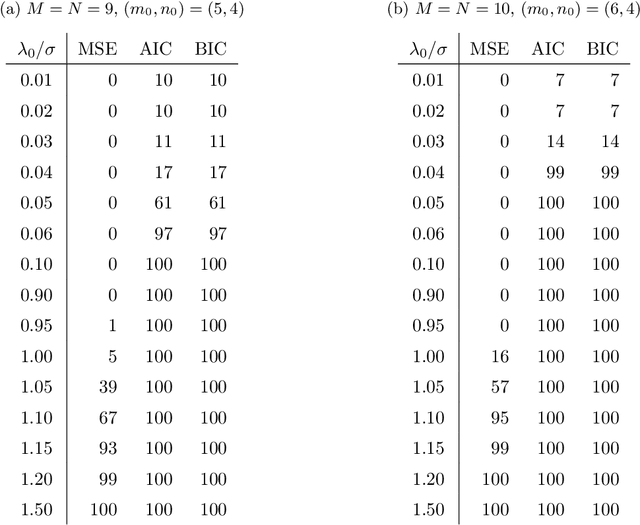
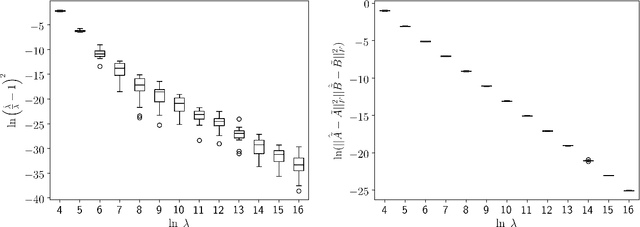
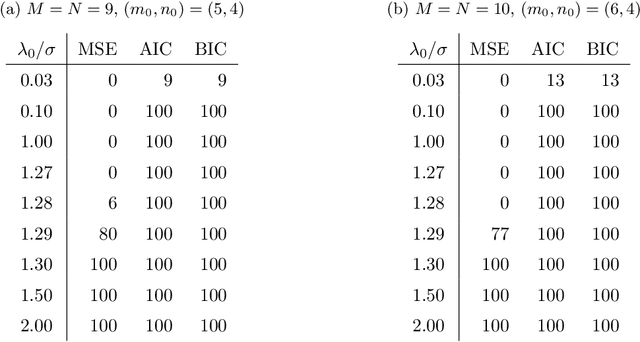
We consider matrix approximation induced by the Kronecker product decomposition. Similar as the low rank approximations, which seeks to approximate a given matrix by the sum of a few rank-1 matrices, we propose to use the approximation by the sum of a few Kronecker products, which we refer to as the Kronecker product approximation (KoPA). Although it can be transformed into an SVD problem, KoPA offers a greater flexibility over low rank approximation, since it allows the user to choose the configuration of the Kronecker product. On the other hand, the configuration (the dimensions of the two smaller matrices forming the Kronecker product) to be used is usually unknown, and has to be determined from the data in order to obtain optimal balance between accuracy and complexity. We propose to use an extended information criterion to select the configuration. Under the paradigm of high dimensionality, we show that the proposed procedure is able to select the true configuration with probability tending to one, under suitable conditions on the signal-to-noise ratio. We demonstrate the performance and superiority of KoPA over the low rank approximations thought numerical studies, and a real example in image analysis.
Opportunities for artificial intelligence in advancing precision medicine
Nov 17, 2019
Machine learning (ML), deep learning (DL), and artificial intelligence (AI) are of increasing importance in biomedicine. The goal of this work is to show progress in ML in digital health, to exemplify future needs and trends, and to identify any essential prerequisites of AI and ML for precision health. High-throughput technologies are delivering growing volumes of biomedical data, such as large-scale genome-wide sequencing assays, libraries of medical images, or drug perturbation screens of healthy, developing, and diseased tissue. Multi-omics data in biomedicine is deep and complex, offering an opportunity for data-driven insights and automated disease classification. Learning from these data will open our understanding and definition of healthy baselines and disease signatures. State-of-the-art applications of deep neural networks include digital image recognition, single cell clustering, and virtual drug screens, demonstrating breadths and power of ML in biomedicine. Significantly, AI and systems biology have embraced big data challenges and may enable novel biotechnology-derived therapies to facilitate the implementation of precision medicine approaches.
CNNTOP: a CNN-based Trajectory Owner Prediction Method
Jan 05, 2020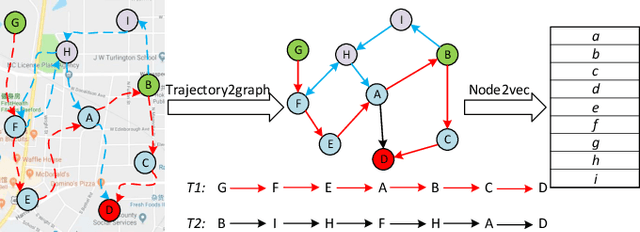
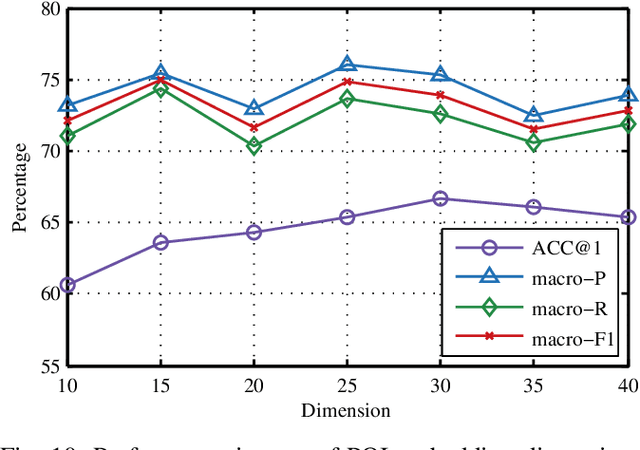
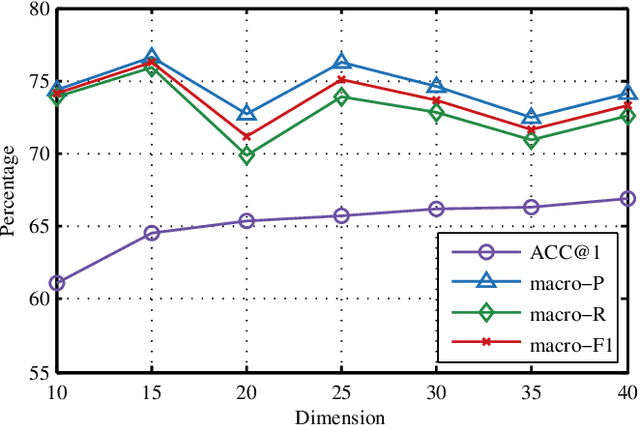
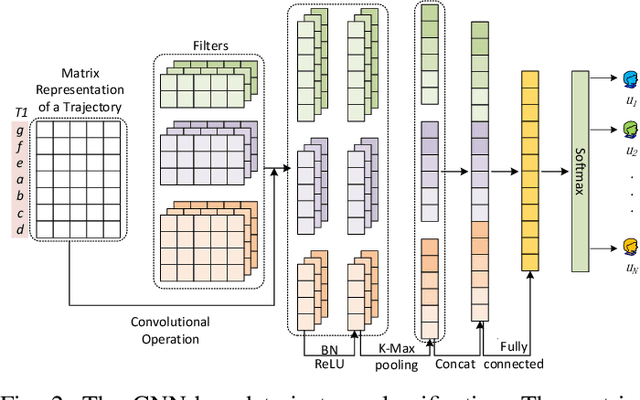
Trajectory owner prediction is the basis for many applications such as personalized recommendation, urban planning. Although much effort has been put on this topic, the results archived are still not good enough. Existing methods mainly employ RNNs to model trajectories semantically due to the inherent sequential attribute of trajectories. However, these approaches are weak at Point of Interest (POI) representation learning and trajectory feature detection. Thus, the performance of existing solutions is far from the requirements of practical applications. In this paper, we propose a novel CNN-based Trajectory Owner Prediction (CNNTOP) method. Firstly, we connect all POI according to trajectories from all users. The result is a connected graph that can be used to generate more informative POI sequences than other approaches. Secondly, we employ the Node2Vec algorithm to encode each POI into a low-dimensional real value vector. Then, we transform each trajectory into a fixed-dimensional matrix, which is similar to an image. Finally, a CNN is designed to detect features and predict the owner of a given trajectory. The CNN can extract informative features from the matrix representations of trajectories by convolutional operations, Batch normalization, and $K$-max pooling operations. Extensive experiments on real datasets demonstrate that CNNTOP substantially outperforms existing solutions in terms of macro-Precision, macro-Recall, macro-F1, and accuracy.
Automatic Co-Registration of Aerial Imagery and Untextured Model Data Utilizing Average Shading Gradients
Jun 26, 2019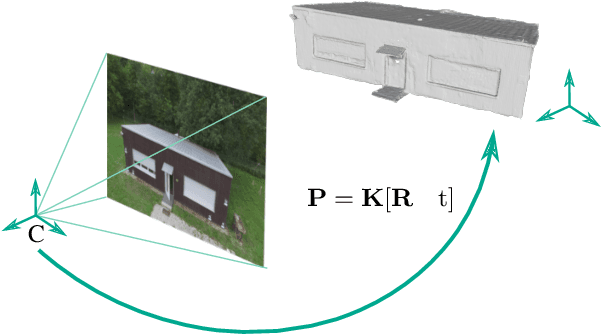
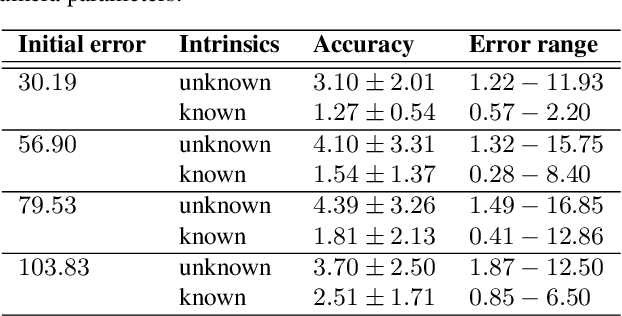
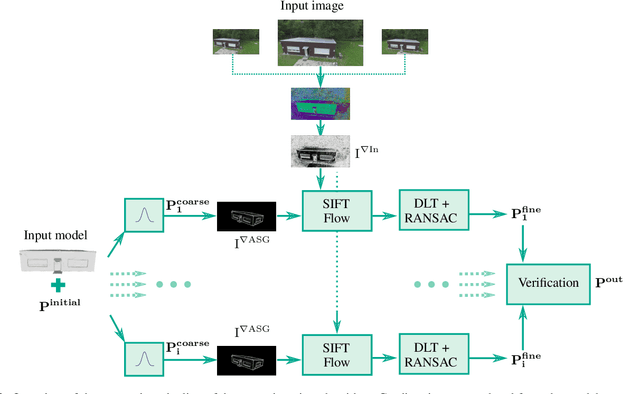

The comparison of current image data with existing 3D model data of a scene provides an efficient method to keep models up to date. In order to transfer information between 2D and 3D data, a preliminary co-registration is necessary. In this paper, we present a concept to automatically co-register aerial imagery and untextured 3D model data. To refine a given initial camera pose, our algorithm computes dense correspondence fields using SIFT flow between gradient representations of the model and camera image, from which 2D-3D correspondences are obtained. These correspondences are then used in an iterative optimization scheme to refine the initial camera pose by minimizing the reprojection error. Since it is assumed that the model does not contain texture information, our algorithm is built up on an existing method based on Average Shading Gradients (ASG) to generate gradient images based on raw geometry information only. We apply our algorithm for the co-registering of aerial photographs to an untextured, noisy mesh model. We have investigated different magnitudes of input error and show that the proposed approach can reduce the final reprojection error to a minimum of 1.27 plus-minus 0.54 pixels, which is less than 10 % of its initial value. Furthermore, our evaluation shows that our approach outperforms the accuracy of a standard Iterative Closest Point (ICP) implementation.
Does Learning Require Memorization? A Short Tale about a Long Tail
Jun 26, 2019

State-of-the-art results on image recognition tasks are achieved using over-parameterized learning algorithms that (nearly) perfectly fit the training set. This phenomenon is referred to as data interpolation or, informally, as memorization of the training data. The question of why such algorithms generalize well to unseen data is not adequately addressed by the standard theoretical frameworks and, as a result, significant theoretical and experimental effort has been devoted to understanding the properties of such algorithms. We provide a simple model for prediction problems in which interpolating the dataset is necessary for achieving close-to-optimal generalization error. The model is motivated and supported by the results of several recent empirical works. In our model, data is sampled from a mixture of subpopulations and the frequencies of these subpopulations are chosen from some prior. The model allows to quantify the effect of not fitting the training data on the generalization performance of the learned classifier and demonstrates that memorization is necessary whenever frequencies are long-tailed. Image and text data are known to follow such distributions and therefore our results establish a formal link between these empirical phenomena. To the best of our knowledge, this is the first general framework that demonstrates statistical benefits of plain memorization for learning. Our results also have concrete implications for the cost of ensuring differential privacy in learning.
Convolutional Neural Networks: A Binocular Vision Perspective
Dec 21, 2019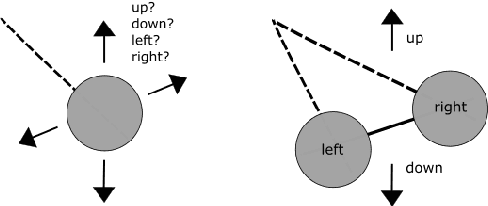
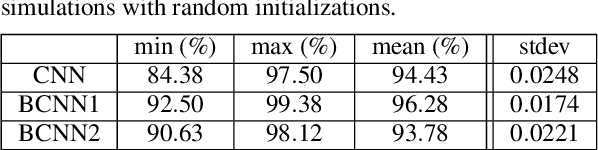
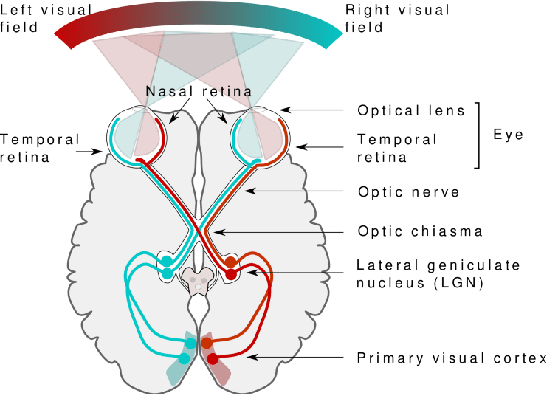

It is arguable that whether the single camera captured (monocular) image datasets are sufficient enough to train and test convolutional neural networks (CNNs) for imitating the biological neural network structures of the human brain. As human visual system works in binocular, the collaboration of the eyes with the two brain lobes needs more investigation for improvements in such CNN-based visual imagery analysis applications. It is indeed questionable that if respective visual fields of each eye and the associated brain lobes are responsible for different learning abilities of the same scene. There are such open questions in this field of research which need rigorous investigation in order to further understand the nature of the human visual system, hence improve the currently available deep learning applications. This position paper analyses a binocular CNNs architecture that is more analogous to the biological structure of the human visual system than the conventional deep learning techniques. While taking a structure called optic chiasma into account, this architecture consists of basically two parallel CNN structures associated with each visual field and the brain lobe, fully connected later possibly as in the primary visual cortex (V1). Experimental results demonstrate that binocular learning of two different visual fields leads to better classification rates on average, when compared to classical CNN architectures.
Learning to Clean: A GAN Perspective
Jan 28, 2019



In the big data era, the impetus to digitize the vast reservoirs of data trapped in unstructured scanned documents such as invoices, bank documents and courier receipts has gained fresh momentum. The scanning process often results in the introduction of artifacts such as background noise, blur due to camera motion, watermarkings, coffee stains, or faded text. These artifacts pose many readability challenges to current text recognition algorithms and significantly degrade their performance. Existing learning based denoising techniques require a dataset comprising of noisy documents paired with cleaned versions. In such scenarios, a model can be trained to generate clean documents from noisy versions. However, very often in the real world such a paired dataset is not available, and all we have for training our denoising model are unpaired sets of noisy and clean images. This paper explores the use of GANs to generate denoised versions of the noisy documents. In particular, where paired information is available, we formulate the problem as an image-to-image translation task i.e, translating a document from noisy domain ( i.e., background noise, blurred, faded, watermarked ) to a target clean document using Generative Adversarial Networks (GAN). However, in the absence of paired images for training, we employed CycleGAN which is known to learn a mapping between the distributions of the noisy images to the denoised images using unpaired data to achieve image-to-image translation for cleaning the noisy documents. We compare the performance of CycleGAN for document cleaning tasks using unpaired images with a Conditional GAN trained on paired data from the same dataset. Experiments were performed on a public document dataset on which different types of noise were artificially induced, results demonstrate that CycleGAN learns a more robust mapping from the space of noisy to clean documents.
Enabling Hyper-Personalisation: Automated Ad Creative Generation and Ranking for Fashion e-Commerce
Aug 27, 2019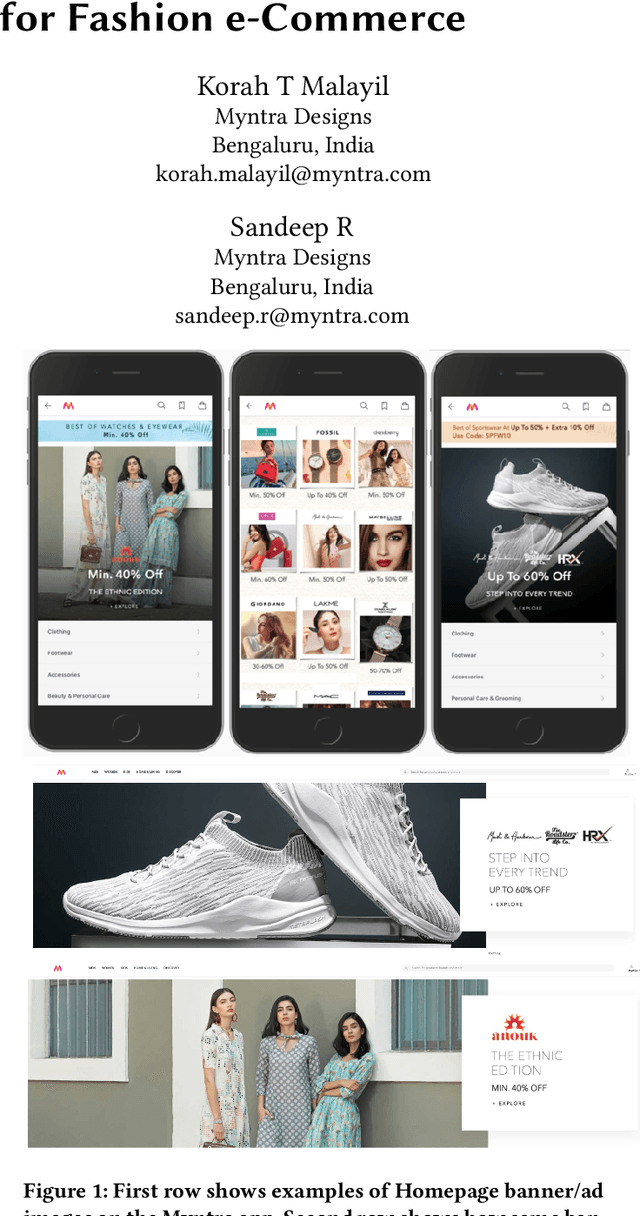
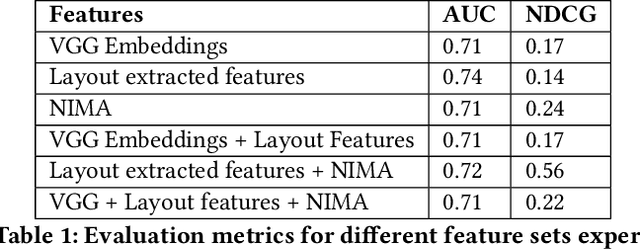
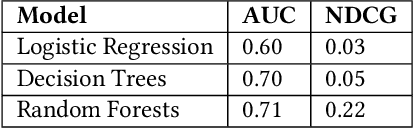
Homepage is the first touch point in the customer's journey and is one of the prominent channels of revenue for many e-commerce companies. A user's attention is mostly captured by homepage banner images (also called Ads/Creatives). The set of banners shown and their design, influence the customer's interest and plays a key role in optimizing the click through rates of the banners. Presently, massive and repetitive effort is put in, to manually create aesthetically pleasing banner images. Due to the large amount of time and effort involved in this process, only a small set of banners are made live at any point. This reduces the number of banners created as well as the degree of personalization that can be achieved. This paper thus presents a method to generate creatives automatically on a large scale in a short duration. The availability of diverse banners generated helps in improving personalization as they can cater to the taste of larger audience. The focus of our paper is on generating wide variety of homepage banners that can be made as an input for user level personalization engine. Following are the main contributions of this paper: 1) We introduce and explain the need for large scale banner generation for e-commerce 2) We present on how we utilize existing deep learning based detectors which can automatically annotate the required objects/tags from the image. 3) We also propose a Genetic Algorithm based method to generate an optimal banner layout for the given image content, input components and other design constraints. 4) Further, to aid the process of picking the right set of banners, we designed a ranking method and evaluated multiple models. All our experiments have been performed on data from Myntra (http://www.myntra.com), one of the top fashion e-commerce players in India.
Research on dynamic target detection and tracking system of hexapod robot
Dec 04, 2019Dynamic target detection and target tracking are hot issues in the field of image. In order to explore its application value in the field of mobile robot, a dynamic target detection and tracking system is designed based on hexapod robot. Firstly, the dynamic target detection method is introduced with region merging and adaptive external point filtering based on motion compensation method. This method achieves the accurate compensation of the moving background through symmetric matching and adaptive external point filtering, and achieves complete detection of non-rigid objects by region merging. Secondly, the application of target tracking algorithm based on KCF in hexapod robot platform is studied, and the Angle tracking of moving target is realized by adaptive adjustment of tracking speed. The last, the architecture of robot monitoring system is designed, which consists of operator, processor, hexapod robot and vision sensor, and the moving object detection and tracking algorithm proposed in this paper is applied to the system. The experimental results show that the improved algorithm can effectively detect and track the moving target when applied to the system of the mobile hexapod robot.
Unsupervised Segmentation Algorithms' Implementation in ITK for Tissue Classification via Human Head MRI Scans
Feb 26, 2019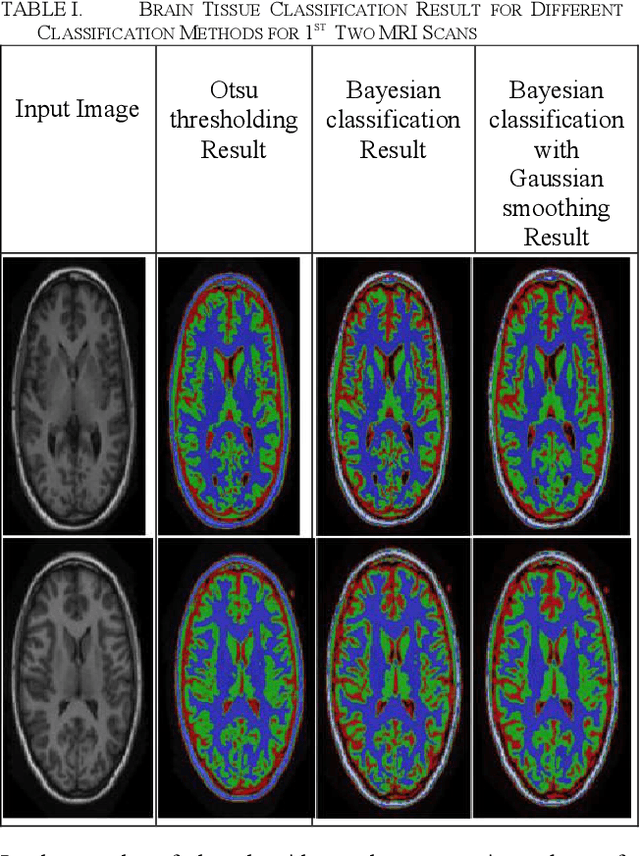
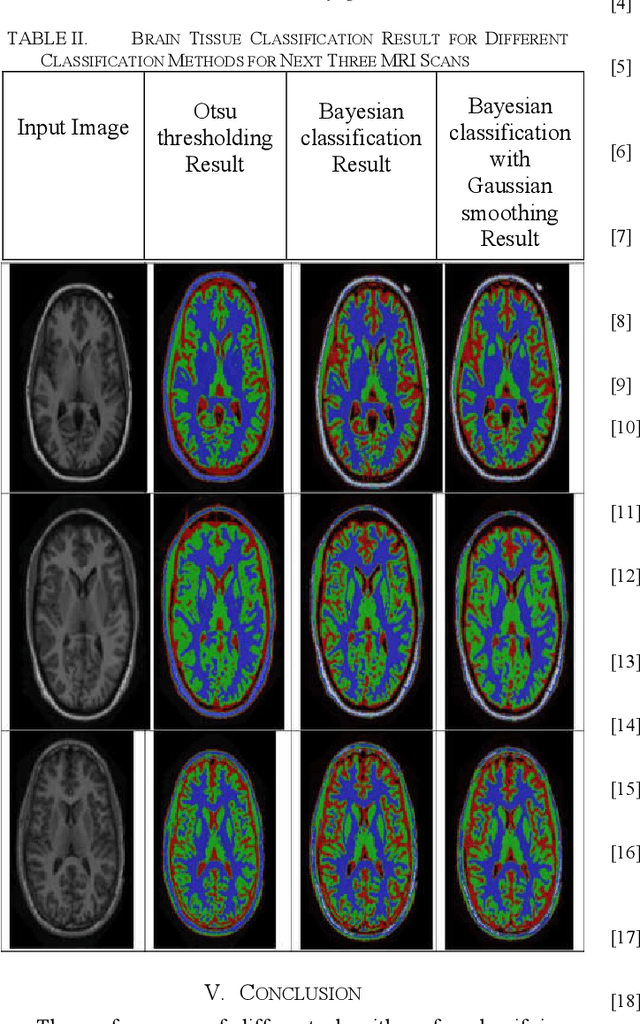
Tissue classification is one of the significant tasks in the field of biomedical image analysis. Magnetic Resonance Imaging (MRI) is of great importance in tissue classification especially in the areas of brain tissue classification which is able to recognize anatomical areas of interest such as surgical planning, monitoring therapy, clinical drug trials, image registration, stereotactic neurosurgery, radiotherapy etc. The task of this paper is to implement different unsupervised classification algorithms in ITK and perform tissue classification (white matter, gray matter, cerebrospinal fluid (CSF) and background of the human brain). For this purpose, 5 grayscale head MRI scans are provided. In order of classifying brain tissues, three algorithms are used. These are: Otsu thresholding, Bayesian classification and Bayesian classification with Gaussian smoothing. The obtained classification results are analyzed in the results and discussion section.